米国のカリスマウェブマーケッター、ニール・パテルが書き下ろした上級者向けのSEOガイドを今日から一章ずつ紹介していきたいと思います。どの記事もその辺のSEO関連書籍を凌駕しかねない充実の内容ばかり。第一回目は検索エンジンにクロールされるための究極のサイト作りと手法についてページネーションから.htaccess、サイトの正しい移行方法から各種ツールの使い方まで徹底解説。 — SEO Japan
上級者向けSEOガイド チャプター 1へようこそ。このチャプターでは、インデクセーションおよびアクセシビリティを考慮してウェブサイトを評価 & 最適化する上級者向けの手法を伝授していく。
ただし、検索エンジンに対するアクセシビリティだけでなく、実際のユーザーに対するアクセシビリティにも配慮する。要するに、このチャプターには、エンジンとユーザーに対するベストプラクティスが網羅されていることになる – まるで、グーグル翻訳をインストールして、AJAXをクロール可能にするようなものだ。
このチャプターで取り上げた手法をウェブサイトに必要に応じて適用すると、並外れてクロール可能 & アクセス可能なウェブサイトに生まれ変わるだろう。
1. 検索エンジンのようにサイトを閲覧する
SEO目的でサイトを最適化する際、検索エンジンの視点に立って考えるべきではないだろうか?また、検索エンジンが見ているように、サイトを見るべきである。ご存知のように“ソース”を閲覧して、ブラウザ向けのHTMLソースを見ることが可能である。しかし、検索エンジンの視点でサイトを閲覧し、技術的なSEOの穴を見つける上で効果が高く、すぐに利用することが可能なメソッドを私は発見した。
ステップ 1: プラグインをインストールする
ここではファイヤーフォックスが便利である。以下にプラグインを挙げる:
ウェブディベロッパー - https://addons.mozilla.org/en-US/firefox/addon/web-developer/
ユーザーエージェントスウィッチャー - https://addons.mozilla.org/en-US/firefox/addon/user-agent-switcher/
ステップ 2: ファイヤーフォックスでJavaScriptを無効にする

「preferences」 & 「content」にアクセスし、「Enable JavaScript」のチェックを外す。
メニュー、リンク、そして、ドロップダウン等のアイテムをJavaScriptを使わずにグーグルボットに提供する必要があるため、この作業を実施する。JavaScriptに埋められていると、グーグルはクロールすることが出来ないのだ。
ステップ 3: ウェブディベロッパープラグインを使ってCSSを無効にする

グーグルボットがHTMLの順番でコンテンツをクロールするため、CSSを無効にする必要がある。CSSのスタイリングは、コンテンツの順序を曖昧にしてしまうことがあるためだ。
ステップ 4: ユーザーエージェントをグーグルボットに設定する

ステップ 5: ウェブサイトを立ち上げ、閲覧する
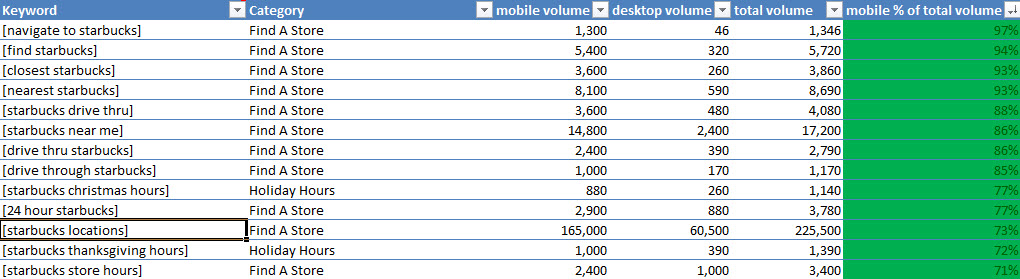
クイックスプラウトはグーグルボットの目にはどのように見えているのだろうか?
これはページの上部のみである(すべてページを掲載すると、とても長くなってしまう)。しかし、クリック可能なリンクとしてメニューが表示されており、その他のテキストやリンクはグーグルボットに全て公開されている点は伝わるはずだ。
このようにして、ウェブサイトを閲覧すると、思わぬ発見をすることがある。
チェックするべきポイントを幾つか挙げていく:
- メニューのリンクはすべて表示されているだろうか(ドロップダウンも)?
- すべてのメニューアイテムとリンクは、プレーンテキストとして表示されているだろうか?
- すべてのリンクはクリック可能だろうか?
- この手法を利用することにより、以前は隠されていたテキストが表示されるだろうか(隠されたテキストは、グーグルボットに警告を送る。悪意があって隠しているわけではなくても、グーグルボットから隠すべきではないはずだ)?
- サイドバーやウィジェットのコンテンツは、上部に掲載されているだろうか?忘れないでもらいたいことがある。特に重要なリンクやコンテンツは、HTMLの上部に掲載されているべきである。この点は、大規模なサイトにとっては特に重要である。
それでは、問題のあるサイトの例を以下に掲載する。

このサイトの問題点は、メニューのテキストが実際にはテキストではなく、イメージである点である。要するに、グーグルボットに与えるテキストのシグナルが存在しないのだ。被リンクに対するアンカーテキストの重要性は皆さんもご存知のはずである。内部リンクにとってもテキストは同じように重要である。上のウェブサイトでは、ホームページから注がれるリンクジュースの価値を余すところなく受けている内部のページは存在しないことになる。
検索エンジンの視点でオンサイトの調査を実施したら、次にウェブスパイダーを使ってサイトをクロールする段階に移る。
2. スクリーミングフロッグを使ってサイトをクロールする
スクリーミングフロッグとは?

スクリーミングフロッグ SEO スパイダーを利用すると、ウェブサイトをクロールし、見るだけで、サイトを今までよりも遥かに簡単に且つ素早く構築する方法に関して、重要な情報を得ることが出来るようになる。数分後には、サイトの見え方に関して新たな見解を得ているはずである。
これは実践ガイドであるため、自分のウェブスパイダーを利用するメリットの詳細を知りたいなら、次のスクリーミングフロッグの文書を参考にしてもらいたい:
http://www.screamingfrog.co.uk/seo-spider/
注記: スクリーミングフロッグは無料で1度に500ページまでクロールすることが可能である。そのため、500ページ以上持つ大きなサイトでこのツールを利用する場合、年間ライセンスを購入する必要がある。ここでとっておきの次善策を紹介しよう。サブディレクトリを入力してクロールさせることが出来る – 例えば http://www.quicksprout.com/2012/では、2012年の投稿のみを対象にしている。 複数のサブディレクトリでこの作業を実施すると、少しずつではあるが、サイト全体をクロールすることが出来る。
ステップ 1: サイトをクロールする
ステップ 2: クロールを保存する
ステップ 3: ページレベルをチェックする
ステップ 4: クロールのエラーを確認する
ステップ 5: 長いタイトルを探し、修正する
ステップ 6: 長いデスクリプションを探し、修正する
ステップ 7: インデクセーションの設定を確認する
おまけのアドバイス: 何らかのHTMLを持つ全てのページを見つける方法
ステップ 1: サイトをクロールする
スクリーミングフロッグを立ち上げ、サイトでクロールを実施する。

このタスクには、サイトの大きさに応じて、2 – 20分間を要する。
ステップ 2: クロールを保存する

ファイルフォーマット.seospiderでサイトのクロールの結果を保存するべきである。こうすることで、プログラムを閉じてしまった場合、または、後に見直したい場合でも、再びクロールを行わなくても済む。ただし、サイトに大きな変更を加えたら、再びクロールする必要がある点を忘れないでもらいたい。いずれにせよ、このデータがあれば、クロールを記録しておくことが出来る。
ステップ 3: ページレベルをチェックする
これはあくまでも上級者向けのガイドであり、SEOを確実に改善する、本当の意味での変化をウェブサイトにもたらすことを目標に掲げている。そのため、サイトに適用することが可能なスクリーミングフロッグの情報を獲得する取り組みに焦点を絞って説明させてもらう。
ウェブサイトの奥深くに埋められたページを持っているなら、ユーザーにとっても、SEOにとっても、マイナスに働いてしまう。そのため、スクリーミングフロッグを使って、簡単にこのようなページを見つけ、行動を起こすことが出来るようにリストアップする方法を紹介する。
クロールを行った後、サイトの内部で集められた全てのデータを表示するメインの「Internal」ページに移動する。
ドロップダウンメニューの下のHTMLを選択する。
右端までスクロールする。

「level」をクリックして、ページレベルごとにコンテンツをソートする。

クイックスプラウトでさえ、4-7ページの深さにある過去の投稿が幾つか存在する。
因みに、crosslinker(http://wordpress.org/extend/plugins/cross-linker/ )等のワードプレス用のプラグインの利用を検討してもらいたい。内部でリンクを張り、投稿をリンクで結ぶ上で役に立つためだ。
スクロールして左端に戻ると、新しい投稿を作成する際に、優先的にリンクを張っておきたいページのリストが完成しているはずだ。

リストをCSVフォーマットにエクスポートする:

これで、エクセルから直接、新しい投稿でリンクを張ることが可能な、優れた実用的なURLのリストを手に入れたことになる。
また、リンクを張る際は、当該のリファレンスが、関連しており、有益であり、そして、記述的なキーワードが豊富に詰まったアンカーテキストである点を確認してもらいたい。
ステップ 4: クロールのエラーを確認する
次に、上部のメニューのその他の項目を調べていく。スクリーミングフロッグには多くの掘り出し物が眠っているものの、探し出す方法を知らなければ宝の持ち腐れである – これからその方法を伝授する。
もちろん、グーグルウェブマスターツールでもクロールのエラーに関するデータを得ることが可能だが、データが不完全、または、古い可能性がある。また、この方法は、リンクを張っている全てのリンク切れを起こしている外部 リンクを見つけることも出来る。加えて、自分のツールでサイトをクロールする度に、最新の正確なリストを得られるメリットがある。
- 「Response Codes」をクリックする
- フィルタードロップダウンメニューから「Client Error 4xx」を選択する
- CSVでエクスポートする

こうすることで、400レベルのエラー(通常は404)を返すページのみのリストを得ることが可能になる。
ステップ 5: 長いタイトルを探し、修正する
タイトルタグとメタディスクリプションには、推奨される長さがあることは、皆さんもご存知のはずである。やはり、ウェブマスターツールからこの類のデータを手に入れることが出来る。
スクリーミングフロッグで入手可能なデータは完全であり、ソート & フィルターすることが可能である。

- 上部のメニューで「Page Titles」をクリックする。
- メニューから「Over 70 Characters」を選択する。
- CSVにエクスポートする。

CSVファイルを開く。
アドバイス: すぐに「名前を付けて」保存することを薦める。さもなければフォーマットにより変更を失う可能性がある。

このエクセル文書で、新しいタイトルに対して新たにカラムを作成しておこう。また、長さに対するカラムも作成するべきである。
エクセルで、新しいタイトルタグを作る度に、自動的に文字数をカウントする容易な手段が欲しいだろうか?それなら、このシンプルな数式を「new length」のカラムに加えよう。
=LEN(E3)
当然だが、新しいタイトルを入力したセルを参照する必要がある。

次に
- 数式のセルを選択する。
- 数式のセルの右下にカーソルを合わせる。
- カーソルが十字型に変化するまで待つ。
- スクエアをコラム全体に下方向にドラッグする。
これで全ての新しいタイトルタグの長さをカウントしてもらえるうようになる。

ステップ 6: 長いデスクリプションを探し、修正する
長いデスクリプションを探し、修正する作業は、一つ前の作業に似ている。
デスクリプションのメニューにアクセスする。

フィルタードロップダウンメニューから「Over 156 Characters」を選択する
CSVにエクスポートする
新しいタイトルタグと同じように、エクセスで新しいディスクリプションの作成に取り掛かることが可能だ。ここでも、新しいカラムを作り、数式 =LEN(E2) を使って、自動的に新しいデスクリプションタグの長さをカウントさせよう。
ステップ 7: インデクセーションの設定を確認する
「meta and canonical」メニューにアクセスして、インデクセーションの設定を確認する必要がある。次のようなエラーを探すべきである:
- カノニカルタグの欠如
- 誤ったカノニカルタグ(異なるページに向けられている等)
- インデックスされるべきなのにも関わらず、「noindex」タグがつけられているページ。
- インデックスされるべきではないにも関わらず、メタタグが欠けている、あるいは「index」がつけられているページ。

おまけのアドバイス: 何らかのHTMLを持つ全てのページを見つける方法
さらにテクニカルな内容に踏み込む。特定のHTMLを持つ全てのページを探し出したい状況を想像してもらいたい。例えば、クイックスプラウトで、新しいタブやウィンドウで開くリンクを持つページを全て見つける必要があると仮定する。
1: Configurationメニューから「Custom」を選択する

2: 探したいHTMLを「Filter 1」に入力する。
注記: 入力したHTMLを含まないページを探すことも可能だ。最高で5つのフィルターを入力することが出来る。

3: サイトを再びクロールする
4: メニューで「Custom」を選ぶ
5: フィルタードロップダウンメニューから「Filter One」を選択する

これで、新しいタブまたはウィンドウで開くリンクを持つページが全て判明したことになる。
このメソッドは、何も変わらないなら、既存のサイトにとって大きくプラスに働く。しかし、サイトのデザイン変更を準備している場合はどうすればいいのだろうか?それなら、デザイン変更に備えて、自己評価するべきである。
3. サイトのデザイン変更を自己評価
次にサイトのデザイン変更を行う際の評価プロセスを、手順を追って説明していく。これは、ウェブサイトを進化させる上で、そして、オンラインでのオーソリティをアピールする上で重要なステップとなる。また、このステップでも、トラフィックを取り逃さないことを心掛けてもらう。
上級者向けSEOガイドのこのセクションが対象にしているのは、新しいサイトを作りながら、次のようなベストプラクティスに従っている人達である:
- クロール可能なことを確かめる
- 新しいXMLサイトマップを投稿する
- 301リダイレクトを導入する
進捗状況を確認するためのスプレッドシートを作成する
以下に、新しいサイトを立ち上げる際に、このようなメトリクスを測定する方法を示すモデルのスプレッドシートを掲載する。
|
日付
|
インデックスされたページ数
|
キャッシュの日付
|
PR
|
DA
|
WMTのエラー
|
注記
|
|
4/1/2012
|
4,200
|
3/23/2012
|
6
|
71
|
525
|
新しいサイトを立ち上げる
|
|
4/8/2012
|
3,750
|
4/7/2012
|
5
|
67
|
679
|
新しいサイトのキャッシュが行われる
|
|
4/15/2012
|
4,150
|
4/12/2012
|
6
|
70
|
482
|
エラーの修正作業を開始
|
インデックスされたページ数を測定
グーグルの site: searchを利用する

キャッシュの日時を測定する
グーグルのcache:sitename.com検索をここでも利用する。

キャッシュの日時は、アルゴリズムでグーグルがサイトのどのバージョンを利用しているのかを判断する上で、最も役に立つ。
ページランクを測定する
PRはメトリクスとして重要視されているわけではないが、今でもサイトの価値の目安を得る上では有効である。
SEOquakeのツールバーは、ページランクを手っ取り早くチェックすることが可能である。次のURLからインストールしてもらいたい: http://www.seoquake.com/

SEOmozのドメインオーソリティーを測定する
このメトリクスは、SEOmozがリンクスケープのインデックスをアップデートするタイミングによって、遅延が生じることがある。それでも測定する価値はある – ツールバーは次のURLで入手することが可能だ:: http://www.seomoz.org/seo-toolbar
DAのオーソリティでは次のポイントに注目してもらいたい

「not found」エラーを測定する
ウェブマスターツールを利用し、「not found」のエラーを確認し、スタッツを入手する。

このツールおよびステップを介して、出来るだけサイトをスムーズに移行することが可能になる。
4. 公開する前に新しいサイトをテストする
このチュートリアルでは、URLを入力すると、テストウェブサイトに向かうようにコンピュータを設定し、本当のURLを使って、サイトを公開する前にテストすることが出来る状態を作っていく。
- 新しいウェブサイトのIPアドレスを取得する。
ウェブサイトをホスティングしている場所によって、方法は大幅に変わるが、基本的に、管理者パネルのどこかに掲載されているはずである。見つけられなかったら、ホスティングサービスに電話して、尋ねよう。
- ホストのファイルを編集して、IPアドレスに向ける
Macを利用しているなら:
A. Application folder > Utilities > Terminalの順にアクセスしていく

- terminalアップの中で、「sudo nano /etc/hosts」と入力する。
ユーザー名とパスワードを必要に応じて入力する。

- ファイルの最後に、以下の列を入力する:
111.222.333.444 www.newdomain.com
111.222.333.444をステップ 1で入手した実際のIPアドレスに、www.newdomain.comを新しいドメインに置き換える。
 Control-Oを押し、エンターを押す。
E. Control-Xを押し、エディターを終了する。
Control-Oを押し、エンターを押す。
E. Control-Xを押し、エディターを終了する。
F.
terminalウィンドウを閉じる
ウィンドウズのコンピュータを利用しているなら:
A. Startをクリックし、「notepad"」を検索ボックスに入力し、スタートメニューでノートパッドを表示させる
B. ノートパッドで右クリックし、「run as administrator」を左クリックする。
許可を求められたら、「はい」を選択する
C.
ファイルをクリックし、開く
D. ファイル名のボックスで、「\windows\system32\driver\etc」を入力し、Enterを押す。sp;
E. ファイルのタイプのプルダウンを「text file」から「all files」に変更する。
F. 「hosts」をダブルクリックする。
G. ファイルの最後に、次の列を入力する:
111.222.333.444 www.newdomain.com
111.222.333.444をステップ 1で入手した実際のIPアドレスに、 www.newdomain.comを新しいドメインに置き換える。
- ブラウザを開いて、ウェブサイトをテストし、思い通りに表示されているかどうか確認する。新しいウェブサイトに対するURLを入力する。すると、hosts fileエディターは、テストのサイトにアクセスさせるようになる。
- テストを行ったら、ステップ 2で加えた変更を戻す必要がある。単純に、ファイルに戻り、加えた列を削除するだけでよい。
5. ダウンタイムなしで新しいサイトに移行する
警告: 何か誤るとサイトをダウンさせる可能性があるので、細心の注意が必要である。
新しいウェブサイトに移行する際は、以下のガイドラインに従い、ダウンタイムを出すことなく、安全な移行を心掛けてもらいたい。アップデートされたIPを世界中のサーバーが入手するには約1日を要するため、少なくとも、新しいサイトの運営を開始してから1週間は新旧のサーバーを両方とも稼働させる計画を立てておこう。
- 新しいドメインのTTLを5分間に設定する
方法はホスティングサービスやドメイン登録サービスによって異なる。通常は、ドメインのコントロールパネルに設定が用意されているはずだが、見つからなかったら、ドメイン登録サービスに連絡し、サポートを要請しよう。
GoDaddyを利用しているなら:
A) GoDaddyのウェブサイトにログインする
B) My Accountをクリックする。Domainsを探し、Launchをクリックする

C) ドメインの1つをクリックする

D) DNS Managerまで下にスクロールし、Launchをクリックする

E) ホストの下で「@」を探し、「TTL」の下にある鉛筆のアイコンをクリックする

F) メニューをプルダウンして、最短の時間(1/2時間)を選択する
 CNAMEがつけられた「www」を持っているなら、同じように1/2時間に変更しておくべきである。
CNAMEがつけられた「www」を持っているなら、同じように1/2時間に変更しておくべきである。

- ドメインのDNSの設定を見つける
これでサイトのテストの実施 & TTLの変更を終えたことになる。次に、ドメイン名のDNSの設定を変える作業に移る。
まず、現在のドメイン登録サービスにアクセスし、現在のDNSの設定を探す。次に、新しいホスティングサービスにアクセスし、現在のドメイン登録サービスに入力する必要のある新しいDNSの設定をメモする。
手続きはホスティングサービスによって、そして、ドメイン登録サービスによって異なる。
通常は、ドメインのコントロールパネルに設定が用意されているはずだが、見つからなかったら、ドメイン登録サービスに連絡を取り、テクニカルサポートを要請しよう。
- 現在のドメインのDNSの設定を変更する。
双方の登録機関の設定を新しいホスティングサービスでメモしたDNSのアドレスにしたら、どこを変えればいいのかは検討がつくはずだ。既にステップ 3で見つけている。
- ステップ 1で加えた列を削除して、hosts ファイルを解除する。
元々加えた列を削除する作業以外は、基本的にステップ 1の手順に従ってもらいたい。
- 5分間待ってから、新しいウェブサイトにアクセスしてみよう。
ブラウザのキャッシュとクッキーをクリアする必要があるかもしれない。新しいウェブサイトがアップしたら、これで完了。アップしなかったら、ステップ 4の作業をリバースし、古いウェブサイトに戻そう。
6. クロール可能なAJAX(JQuery GETを利用)
この例では、jQueryのpostメソッドを使って、クロール可能なAJAXを作る方法を紹介する。このチュートリアルでは、「XMLHttpRequest POST」メソッドを利用する。
このベストプラクティスに関する詳細は次のURLで確認してもらいたい:
http://googlewebmastercentral.blogspot.com/2011/11/get-post-and-safely-surfacing-more-of.html
- HTMLテンプレートを作成する。

- jQueryをサイトに加える
この例では、列 4が加えられている。

- 「DIV」タグを固有のIDと共に、本文の動的なコンテンツが向かう場所に加える。
この例では、列 8が加えられている。

- サイトに「DIV」タグにコンテンツを読み込むJavaScriptを追加する。
この例では、列 10-15が加えられている。

- PHP スクリプトを作成する。
例のコードは、例のブログの投稿をアウトプットする。
- ウェブサーバーでスクリプトを試す。
次のようなページが表示されるはずである:

- ページのソースを確認する。
このHTMLテンプレートと同じようなソースになるはずである。
- Inspect Elementをチェックする。
DOMに動的なコンテンツが読み込まれているはずである。次のようなソースが表示されるはずだ:
7. クロール可能なAJAX(ハッシュなし)
このチュートリアルは、更新することなく、動的なコンテンツを読み込むものの、URLを変更するウェブサイトを対象にしている。グーグルは、HTMLのスナップショットに対するクエリの文字列内で、ルーティング「_escaped_fragment_」を推奨している。HTMLをグーグルボットに、JavaScriptをユーザーに表示するためだ。
同じ成果をもたらす方法は他にも多くある。方法はウェブサイトの設定に左右される。この例では、PHPを使って、何を表示するべきかを判断する。
次のようなURLを持っているなら: “http://www.example.com/index.php” スピードアップを図るため、コンテンツを動的に、そして、非同期的に読み込むJavaScriptでページを作るPHPが理想である。
次のようなURLを持っているなら: “http://www.example.com/index.php?_escaped_fragment_” インデックス & クロール可能な通常のHTMLのページを作るPHPが必要である。
この方法のベストプラクティスに関する詳細は次のページで確認しよう: https://developers.google.com/webmasters/ajax-crawling/docs/getting-started
- まず、ヘッダーに適切な「meta」タグを加えるPHPスクリプトを作成する.
こうすることで、クエリの文字列「_escaped_fragment_」を用いて、ページをクロールすることが可能な点を検索スパイダーに伝えられる。この例では、「head」タグ全体を生成する関数を作成した。
注記: 列 10に、スパイダーに「espcaped fragment」を使ってクロールするよう伝えるメタタグが記されている。
- 次に、ページを表示させる関数を作成する。
この例では、「render_post」は因数「$render_snapshot」を持つ。デフォルトの状態では、このページは通常のページをユーザーに対して表示する。「render_snapshot」が正しい場合、グーグルボットに対して同じコンテンツのHTMLページを表示する。
注記:
このPHPの列 25は、ページがHTMLか動的かの判断を行う。
列 26-29は、コンテンツを取得し、DIVタグ内にHTMLを返す。
列 31-37は、jQueryを使ってコンテンツを返し、動的にHTMLをDIVタグ内に加える。

- 次に、「escapted fragment」のクエリの文字列を処理するコードを加えていく
この例では、_escaped_fragment_が見つかった場合、HTMLを使って投稿を表示する。

- 次に、content.phpファイルを作成する。
この例では、コードはJSONをHTMLに変換する。
- 最後に、ajax_crawling.jsonを作る。
これはあくまでもデモに過ぎないが、複雑な設定のウェブサイトにもこの原則を当てはめることが出来る。通常、コンテンツはデータベースから届けられる。このデモでは、単一のファイルである。

- ユーザーによってレンダリングされるページをテストする:
次のようなページが表示されるはずだ:
- view sourceを確認する
コンテンツはJavaScriptを使って動的に加えられているため、表示されていないはずである。

- Inspect Elementsのビューを確認する。
Inspect Elementのビューでは、JavaScriptが実行された後のHTMLに似ているため、コンテンツは表示されている。

- ボットのビューを「_escaped_fragment_」をURLの最後に加えてチェックする。
ダイナミックなページと同じページが表示される:

- ボットのビューを確認しよう。
JavaScriptのない通常のHTMLのようなソースが表示されるはずである。
8. クロスドメイン Rel=canonical
いつクロスドメインを利用するべきか
これは大勢の人達が混乱するポイントであり、実装する前に、このタグを利用するべきタイミングについてを説明していく。
- 古いサイトのコンテンツ、または、重複するコンテンツを新しいサイトにを動かす必要がある時 – そして、古いサイトがサーバーサイドのリダイレクトを提供していない時。
- ただし、出来るだけ古いサイトでオンサイトの重複を削減した後、利用するように心掛けてもらいたい。
- 代わりに301リダイレクトを実装することが可能であり、ユーザーエクスペリエンスの面で好まれるなら、301リダイレクトを利用しよう。
- また、ページでrel = canonicalとnoindexを併用するべきではない。このページは、リダイレクトを拾ってもらうため、インデックス可能でなければならないためだ。
- 両方のページでコンテンツが同じ場合、または違いが僅かな場合に利用しよう。
実装する方法
通常のcanonicalタグを実装する方法と基本的に同じである。
1. ページを準備する
2. (オリジナルの)1つ目のページでソースコードを編集可能な状態にする
3. 古いページの「head」セクションにタグを加え、新しいページに向かわせる:
<link rel="canonical" href="http://www.example.com/example-page-name/>
「example-page-name」は新しいページのURLである。
例
以下のインフォグラフィックの投稿をクイックスプラウトから…
http://www.quicksprout.com/2012/06/11/5-ways-to-get-your-infographic-to-go-viral/
…KISSmetricsに移動するケースを想定する。現実的ではないかもしれないが、とりあえず、移動することにする。次のURLに移動するプロセスを説明する:
http://blog.kissmetrics.com/5-ways-to-get-your-infographic-to-go-viral

その他のアドバイス
- リンクをrelativeではなくabsoluteにする(http:// etcを丸ごと含む)
- 301と同じように、canonicalの連続を避ける
- これは絶対的なルールではなく、あくまでもグーグルに対するヒントであるため、グーグルのインデックスとウェブマスターツールでグーグルがこのタグに従っているかどうかを確認しておきたいところだ。
9. httpsの重複するコンテンツのエラーを修正
皆さんもご存知だとは思うが、httpsとはプロトコルであり、ページをワールドワイドウェブに安全に転送する規約である。ショッピングカート等のページ、ログインページ、そして、その他の安全なページには、httpsのアドレスを設定するべきである。しかし、この取り組みでは、URLに「s」を加えるため、コンテンツの重複を生む可能性がある。
通常は、httpsは、インデックスに含めるべきではない。基本的には公開しないページであり、検索結果に返す必要がないからだ。
クロールレポートやサイト評価で、httpsを持つURLがサイトで重複していることが明らかになったなら、この問題を解決するために以下の3つの手順を踏んでもらいたい:
1. インデックスされているページを特定する
2. インデックスされている理由を診断する
3a. 存在するべきではなページを301リダイレクトする
3b. 存在するべきではないなら、インデックスから削除する
ステップ 1 – インデックスされているhttpsのページを探す
httpsを持つ、インデックスされているページを探し出す次のグーグル検索を実施する
- site:yourdomain.com inurl:https
crazyeggのウェブサイトは何の問題もないように思える。flash loaderを除けば、htttpsのページはインデックされていない。

KissMetricsはインデックスにhttpsが存在するサイトの典型的な例である。
この2つ目のページは通常のブログの投稿であり、インデックスされるべきではない(このページで3つ目)。

また次のページは、httpsを利用するべきではあるものの、インデックスに含まれるべきではないページである

それでは、インデックスされるべきではないページを発見したら、どのように対処すればいいのだろうか?インデックスから削除したい、不要な古いページと同じように、そもそもなぜインデックスに含まれたのかを解明する必要がある。
ステップ 2 – インデックスに含まれた理由を診断する
例として上のブログの投稿を利用する。それでは、ページを詳しく見ていこう。
グーグルクロームは、URLにhttpsが存在するものの、このページが安全が保証されていないことを指摘している。これは、当該のページが、このこのような方法でインデックスに含まれるべきではない点を裏付けている。

内部または外部からリンクが張られたことが原因でインデックスに含まれた可能性が高い。そこで、複数のツールを使って、リンクのソースを発見する試みを行う。
まずは、スクリーミングフロッグを利用する。サイトを完全にクロールする必要があるためだ。
スクリーミングフロッグで、ウェブサイトのルートドメインを入力する(なぜなら、KissMetricsのように、中にはwww/blog等異なるサブドメインで運営しているサイトもあるからだ – ウェブサイト全体が完全にクロールされている点を確かめる必要がある)。

サイトをクロールする際は、当該のページのURLを検索し、表示されるまで待つ。

その後、クロールが完了するまで待ち、「In Links」を精査する。

「to」カラムをチェックし、「https://」を利用しているリンクがあるかどうか確認する

この例では、ページのhttps://版に向けられる内部リンクは見つからなかった。
内部リンクが見つかったら、内部リンクを変更し、httpsバージョンをhttpバージョンに301リダイレクトする必要がある。
内部リンクが見つからなくても、外部リンクが見つかる可能性がある。この場合、必ずしも設定を変える権限を持っているとは限らない。そのため、httpバージョンに301リダイレクトする。すると、ユーザーをhttpバージョンにリダイレクトし、最終的に、httpsバージョンをインデックスから削除/置き換えることが出来る。
ステップ 3a – 内部リンクを修正する
ベストプラクティスとして、常にサイトで「absolute」の内部リンクを利用してもらいたい。
例えば、次のURLにリンクを張る代わりに: /2012/04/30/6-ways-to-generate-more-traffic-out-of-your-images/
私なら次のURLにリンクを張る: http://www.quicksprout.com/2012/04/30/6-ways-to-generate-more-traffic-out-of-your-images/
http://を含むURLのパス全体が含まれている点に注意してもらいたい。
ワードプレスを利用しているなら、自動的にこの作業は行われるはずである。しかし、一部のカスタムサイトまたは他のCMSのサイトでは、自動的に修正してもらえない可能性があるので、自分で修正しなければならない。
エラーを修正する
httpsのリダイレクトに関する指南については、「htaccess hacks」のセクションを参照にしてもらいたい。
10. Rel=nextを用いるページネーション
ページネーションは、オンページのSEOおよびアーキテクチャにおいて、処理が最も難しい取り組みの一つに数えられる。しかし、現在、グーグルは、「next」および「prev」の利用を認めており、一連のページを持っていることを伝えやすくなっている。
ワードプレスのようなCMSを利用している場合、Yoast SEO等、様々なプラグインが提供されている。しかし、自分でサイトを作った人のために、あるいは、ピュア HTMLで自力でコーディングしたサイトを運営している人のために、上述した新しいタグを使って、ページネーションを是正する方法を紹介する。実は割と簡単である。インターネットでは最高のリソースを見つけるのは難しいが、ここでは万全の対策を伝授する。
ステップ 1 – 一連のページを特定する
Zapposを例に説明していく。以下に男性用のスニーカーのページ 1を掲載する。

メニューでページ 2、3等が確認できるため、一連のページ数が振られたページの中で、このページが1ページ目であることを特定した。
以下にページ 1のURLを記載する
http://www.zappos.com/mens-sneakers-athletic-shoes~dA
続いてページ2、ページ3のURLを記載する
http://www.zappos.com/mens-sneakers-athletic-shoes~dB
http://www.zappos.com/mens-sneakers-athletic-shoes~dC
注記: ページを変更するため、Zapposは文字(a、b、c)を利用している。
ステップ 2 – rel=”next”を1ページ目に加える
このように、一連のページを特定すると、ページ 1のみに「next」タグがつけられているはずである。なぜなら、一連のページの最初のページだからだ。そのため、ページ 1に対して、「head」セクションで次のコードを加える:
<link rel="next" href="http://www.zappos.com/mens-sneakers-athletic-shoes~dB”>
ステップ 3 – 中間のページにrel=”next” とrel=”prev”を加える
1ページ目と最後のページを除く全てのページに「next」と「prev」タグが必要である。前後のページが存在するためだ。ページ 2(mens-sneakers-athletic-shoes~dB)に次のタグを加えることが出来る。
<link rel="prev" href="http://www.zappos.com/mens-sneakers-athletic-shoes~dA”>
<link rel="next" href="http://www.zappos.com/mens-sneakers-athletic-shoes~dC”>
ステップ 4 – rel=”prev”を最後のページに加える
一連のページの最後のページには、そのページの一つ前のページのみを参照すればよいため、次のタグを加える:
<link rel="next" href="http://www.zappos.com/mens-sneakers-athletic-shoes~dY”>
Zが最後のページであると仮定している。
注記
cannonicalタグをnext/prevと関連させて含めることが出来る。
absoluteまたはrelativeのURLを利用することも可能だが、個人的には出来る限りabsoluteの利用を薦める。
11. .htaccessを使ってエラーページをリダイレクトする
以下のプロセスに従う必要がある:
1. エラーページを作成する – このページには特別なスクリプトを与える。
2. .htaccessファイルを設定し、エラーページへリダイレクトする。
ステップ 1 – エラーページを作成する
エラーが返されるページを作成する – 名称は何でも構わない – error.phpを薦める。
このページで、上部に次のコードを加える:
<?php
switch($_SERVER["REDIRECT_STATUS"]){
case 400:
$title = "400 Bad Request";
$description = "The request can not be processed due to bad syntax";
break;
case 401:
$title = "401 Unauthorized";
$description = "The request has failed authentication";
break;
case 403:
$title = "403 Forbidden";
$description = "The server refuses to response to the request";
break;
case 404:
$title = "404 Not Found";
$description = "The resource requested can not be found.";
break;
case 500:
$title = "500 Internal Server Error";
$description = "There was an error which doesn't fit any other error message";
break;
case 502:
$title = "502 Bad Gateway";
$description = "The server was acting as a proxy and received a bad request.";
break;
case 504:
$title = "504 Gateway Timeout";
$description = "The server was acting as a proxy and the request timed out.";
break;
}
?>
このPHPコードは、それぞれのタイプ別に異なるタイトルを作成する。こうすることで、異なるファイルを大量に作らなくても済む。すべて一つのファイルで実施することが出来る。
この例では、それぞれのエラーページに対して、固有のタイトルとディスクリプションを一つだけ作成している。しかし、変数を加えて、好きな固有のコンテンツを作成することが出来る。
ステップ 2 – .htaccessを設定する
多くのエラーコードをエラーページにリダイレクトしなければならない。以下の列を.htaccessに加えてもらいたい。
ErrorDocument 400 /error.php
ErrorDocument 401 /error.php
ErrorDocument 403 /error.php
ErrorDocument 404 /error.php
ErrorDocument 500 /error.php
ErrorDocument 502 /error.php
ErrorDocument 504 /error.php
12. RSS フィードを最適化する
RSS フィードはブログで大きな役割を担っている。しかし、このフィードを最適化することで得られるメリットの大きさを見過ごしてしまうことがたまにある。以下の実践的なアドバイスに従ってもらえば、RSS フィードを最大限まで活用することが出来るようになるだろう。
ここではフィードバーナーを利用していると仮定する。
ヘッダーでデフォルトのRSS フィードを置き変える
フィードバーナーを利用していると仮定した場合、ウェブサイト上の全てのリンクは適切なフィードに向けられているだろうか?クイックスプラウトのヘッダーセクションは、フィードバーナーのフィードに向けられている。

この作業を実施していないなら、header.phpファイル(ワードプレスの場合)、または、利用しているCMSが認める場所で、フィードのURLを変更する必要がある。
header.phpファイルでRSSのリンクを見つける
フィードバーナーのフィードのURLに置き換える
フィードバーナーでは早さが命
フィードバーナーには簡単に有効にすることが出来る機能が幾つか存在する。全て利用していることを確認してもらいたい。
Activate SmartFeed
SmartFeedは、あらゆるリーダーとの互換性を確立させる上で便利である。
Optimize->Smartfeedの順にクリックする

Activateをクリックする
FeedFlareを有効にする
Feedflareはリンクをフィードの下に掲載し、フェイスブックでの共有、eメール、deliciousでのブックマーク等の行動をユーザーに要請する手段である。
これは、あらゆるRSSフィードにとって絶対に欠かせないアイテムである。
Optimizeタブで、FeedFlareをクリックする。
表示したいリンクを選択する。 フィードは、フィードをウェブサイトに送信した際に、RSS フィードに表示されるアイテムを意味する。サイトは、ウェブサイトに表示されるアイテムを意味する。

Activateボタンは見にくい位置に掲載されているので注意してもらいたい。一番下に用意されている。

次に、「パーソナル」なフレアを幾つか加えていく。これは、ユーザーが作成したクエリであり、一連のデフォルトのフレアのセットには存在しない。
「Browse the Catalog」をクリックする。
利用可能なフレアを閲覧する。好きなフレアを見つけ、「Link」をクリックする。

するとこのフレアのタブが開く。URLをコピーする。

最初のスクリーンに戻る。フレアのURLを貼り付ける。次に「Add New Flare」をクリックする。
フレアが上に表示される。表示する場所を選ぶ(フィード、サイト、または、その双方)。

下でフレアのプレビューを見ることが出来る。アイテムをドラッグ & ドロップして順番を整えることが出来る。

忘れずに「Save」をクリックすること。 見過ごしやすいので注意してもらいたい。

PingShotを有効にする
PingShotは、アップデートが発生するとフィードバーナーに通知する機能である。PingShotにはフィードの提供をスピードアップする効果が見込める。
Publicize->PingShotの順にアクセスし、「Activate」をクリックする。

フィードのオリジナルのソースにリンクを張る
RSSフィードが許可なく利用され、別のサイトで重複する事態に直面したことはあるだろうか?(このガイドの恩恵を受け)人気の高いサイトを運営しているなら、常にこの問題を抱えているはずだ。グーグルボット、またはユーザーは、どちらがオリジナルのソースなのか分からず混乱している可能性がある。
そのため、これからRSSフィードの下に「自分」こそがコンテンツのオリジナルのソースである点を伝えるリンクを加える方法を伝授する。この手法を実行すると、検索エンジンとユーザーにとって格好の判断材料になるだけでなく、被リンクを得られる可能性がある。
1. RSS ソースリンクをブロガー(ブログスポット)に追加する
Settings -> Site Feedの順にアクセスする
以下のコードを加える:
<hr />
<a href="http://www.myblog.com">My Blog Name</a>
2. RSS ソースリンクをワードプレスに追加する
Appearance -> Editor -> functions.phpの順にアクセスする
次のコードを加える:
function embed_rss($content) {
if(is_feed())
$content .= "<p><a href='". get_permalink() ."'>'";
$content .= get_the_title() ."</a></p>";
return $content;
}
add_filter('the_content', 'embed_rss');
これでコンテンツのオリジナルのソースに対するリファレンスをRSSフィードに用意することが出来る。それでは、いつものように正しく表示されているかテストしよう。
Thank Youを作成する
パーソナライゼーション、そして、読者への感謝のメッセージは大いに効果がある。以下にシンプルなメッセージをフィードに設定する方法を紹介していく。
Optimize->BrowserFriendly->Content Optionsの順にアクセスする

‘enable’をクリックして、個人的なメッセージを入力する。
RSSのeメールを送るタイミングを決める
送信する時間を管理して、より多くのRSSのeメールを開けてもらう。
Publicize->Email Subscriptions->Delivery Optionsにアクセスする

時間帯、オーディエンスにとって最善の時間を選択する。午前9-11時を薦める。
ワードプレスのRSSをフィードバーナーにリダイレクトする
ワードプレスに内蔵されている標準のRSSフィードを利用している人がいてもおかしくはない。そのRSSフィードを購読している人がいる可能性もある。「フィードバーナーリダイレクト」と言うプラグインを利用すると、すべてのフィードがフィードバナーを経由するように設定することが出来る。
プラグインは次のURLで手に入れることが可能だ - http://wordpress.org/extend/plugins/tentbloggers-feedburner-rss-redirect-plugin/
1. ワードプレスのセットアップでインストールする。
2. 有効にする。

双方のフィールドにフィードバーナーのURLを入力する。これで完了。
13. 動画のサイトマップ
動画をサイトまたはブログに投稿しているなら、とりわけ、メタデータでマークアップしているなら、動画のサイトマップを用意するべきである。こうすることで、グーグルやビングが動画のコンテンツに気づき、処理し、インデックスするプロセスが大幅にスピードアップする。
オプション A – 自力で作成する
サイトの規模が小さく、投稿する動画が2、3本しか存在せず、また、たまに投稿する程度なら、自分で動画のXMLサイトマップを容易に作成することが可能である。/span>
まず、XML構造のスケルトンのテンプレートを提供する。後はデータを加えていけばよい。
これは必要なフィールドを持つだけの最もベーシックなテンプレートである。
ステップ 1: 空のXMLファイルを作成する
- ファイルを作成する。名前は何でも構わないが、個人的に好きなファイル名を挙げておく: sitemap_video.xml
- 次に以下のようにルートディレクトリに保存する: http://www.quicksprout.com/sitemap_video.xml
先程も申し上げた通り、ファイル名、そして、保存場所は何でも構わないが、サイトマップをウェブマスターツールに投稿する際にこの情報が必要なので忘れないように気をつけてもらいたい。
ステップ 2: 次のコードをXMLファイルに貼り付ける
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:video="http://www.google.com/schemas/sitemap-video/1.1">
<url>
<loc></loc>
<video:video>
<video:thumbnail_loc></video:thumbnail_loc>
<video:title></video:title>
<video:description></video:description>
<video:content_loc></video:content_loc>
<video:player_loc allow_embed="yes" autoplay="ap=1"></video:player_loc>
</video:video>
</url>
</urlset>
上のコードを説明しておく:

テンプレート内のプロパティの大半は任意だが、とりあえず全てを紹介したかったので掲載しておいた :-)
必要なフィールド
- ページのURL
- 動画ファイルのURLまたはプレイヤーのURL
- タイトル
- ディスクリプション
- サムネイル
それでは、例のテンプレートに情報を記入していく。このテンプレートでは、その他のプロパティは省略し、必要な要素に絞る:
動画1本に対するXML動画サイトマップの基本的なコード
<url>
<loc>http://www.quicksprout.com/videos/neil-patel-video-1.html</loc>
<video:video> <video:thumbnail_loc>http://www.quicksprout.com/thumbs/thumbnail.jpg</video:thumbnail_loc>
<video:title>Advanced SEO for Bloggers</video:title>
<video:description>An exclusive video with SEO expert Neil Patel. Drive ridiculous amounts of leads to your blog and learn the 7 secrets of conversion rate optimization.</video:description>
<video:content_loc>http://www.quicksprout.com/video.flv</video:content_loc>
</video:video>
</url>
その他のプロパティを追加する
次のように、動画のサイトマップに追加することが可能なプロパティが数多く存在する:
<video:duration>
<video:expiration_date>
<video:rating>
<video:view_count>
<video:publication_date>
<video:tag>
<video:tag>
<video:category>
<video:restriction>
<video:restriction>
<video:restriction>
<video:gallery_loc>
<video:gallery_loc>
<video:price>
<video:requires_subscription>
<video:uploader>
<video:uploader>
<video:platform>
<video:platform>
<video:platform>
<video:live>
例のテンプレートに上のプロパティを幾つか加え、動作を確認しよう。
<url>
<loc>http://www.quicksprout.com/videos/neil-patel-video-1.html</loc>
<video:video>
<video:thumbnail_loc>http://www.quicksprout.com/thumbs/thumbnail.jpg</video:thumbnail_loc>
<video:title>Advanced SEO for Bloggers</video:title>
<video:description>An exclusive video with SEO expert Neil Patel. Drive ridiculous
amounts of leads to your blog and learn the 7 secrets of
conversion rate optimization.</video:description>
<video:content_loc>http://www.quicksprout.com/video.flv</video:content_loc>
<!–optional properties–>
<video:duration>750</video:duration>
<video:rating>4.1</video:rating>
<video:view_count>54321</video:view_count>
<video:publication_date>2012-04-01T19:20:30+08:00</video:publication_date>
<video:family_friendly>yes</video:family_friendly>
<video:restriction relationship="allow">IE GB US CA</video:restriction>
<video:requires_subscription>no</video:requires_subscription>
<video:live>no</video:live>
</video:video>
</url>
これは一目見れば分かる類のプロセスである。認められている個別のフィールドの詳細は、グーグルの文書で確認してもらいたい。
ステップ 3: グーグルウェブマスターツールにサイトマップを投稿する
オプション A – ウェブマスターツールに直接投稿する
グーグルにXMLサイトマップを投稿する手法としては、この手法を薦める。
- ウェブマスターツールにサインインする
- ウェブサイトのプロフィールを見る
- Site Configuration->Sitemapsにアクセスする
- 右隅の“Add/Test a Sitemap”をクリックする

- サイトマップの名前を入力し、投稿する。
オプション B – robots.txtファイルに以下の列を加える -
サイトマップ: http://www.example.com/sitemap_video.xml
あらゆるXMLのサイトマップに共通することだが、robots.txtファイルが適切に設定されていると、グーグルはrobot.txtの情報を基に動画を発見し、処理していく。
14. .htaccessのテクニック
これから紹介するアドバイスは、クライアントがApacheを利用している場合のみ有効である。ウィンドウズ IISを利用しているなら、IISのテクニックを参照すること。
- サーバーで.htaccessファイルを探し出す。
(“サーバーで.htaccessを探す方法”を参照)
- .htaccessを見つけたら、テキストエディタを使ってファイルを編集する。
ウィンドウズを利用しているなら、 Notepadを薦める。Macを利用しているなら、 TextWrangler等の無料のテキストエディタをダウンロードしよう。
- .htaccessファイルで何をしたいのかを決め、コードの列を加える:
自分で404ページを作るには
“ErrorDocument”を利用し、最後にオリジナルの404ページへのURLを加える。例:
ErrorDocument 404 http://www.example.com/my-custom-404-page.html
フォルダーをパスワードで保護するには
A. まず、htpasswdファイルを作成する。オンラインツールを利用すると簡単に作成することが出来る: http://www.tools.dynamicdrive.com/password/
B. 左側に希望するユーザー名を、そして、当該の人物に与えたいパスワードを右側に入力する。
C. “path to .htpasswd”ボックスで、公開しないフォルダーを記入する。通常は、次のように、ホームのディレクトリを入力すると安全である:“/home/myusername”
D. submitをクリクし、ダウンロードした.htpasswdファイルを“/home/myusername”に置く。
E. 次にこの情報を.htaccessファイルに入力する。
AuthUserFile /home/myusername/.htpasswd
AuthName EnterPassword
AuthType Basic
require user some_users_name
“some_users_name”をこのフォルダで許可されるユーザーネームと置き換える。
IPアドレスでユーザーをブロックするには
次の4つの列を.htaccessファイルに入力する:
Order allow, deny
Deny from 111.222.333.444
Deny from 555.666.777.888
Allow from all
“deny from,”の列で、例のIPアドレス“111.222.333.444”をブロックしたいIPアドレスに置き換える。
リファラーでユーザーをブロックしたいなら
以下の3つの列を.htaccessファイルに加える:
RewriteEngine On
RewriteCond %{HTTP_REFERER} somedomain\.com [NC]
RewriteRule .* – [F]
複数のリファラーをブロックしたいなら、次のようにRewriteCondの列を増やす必要がある:
RewriteEngine On
RewriteCond %{HTTP_REFERER} somedomain\.com [NC,OR]
RewriteCond %{HTTP_REFERER} anotherdomain\.com [NC,OR]
RewriteCond %{HTTP_REFERER} 3rdDomain\.com [NC]
RewriteRule .* – [F]
最後の列を除く全ての列が“[NC,OR]”で終わっている点に注目しよう。
index.html以外をデフォルトのページに指定するには
“home.html”をデフォルトのページに指定したいと仮定する。その場合、次の列を.htaccessファイルに利用してもらいたい:
DirectoryIndex. home.html
古いドメインを新しいドメインに301リダイレクトするには
以下の列をhtaccessファイルに加える。
RewriteEngine on
RewriteCond %{HTTP_HOST} ^olddomain.com [NC,OR]
RewriteCond %{HTTP_HOST} ^www.olddomain.com [NC]
RewriteRule ^(.*)$ http://www.newdomain.com/$1 [R=301,NC]
"olddomain.com"を古いドメイン名に置き換える。すると、古いドメインからWWWで始まる新しいドメインにリンクを301リダイレクトするようになる。
ウェブサイト上のリソースへの直リンクを防ぐには
次の列を.htaccessファイルに加える:
RewriteEngine on
RewriteCond %{HTTP_REFERER} !^$
RewriteCond %{HTTP_REFERER} !^http://(www\.)?mydomain.com/.*$ [NC]
RewriteRule \.(gif|jpg|js|css)$ – [F]
mydomain.comをドメイン名に置き換える。この列によって、GIF、JPG、JS、そして、CSSファイルへの直リンクを阻止することが可能になる。
HTTPS://からHTTP://へ全てのページをリダイレクトするには
次の列を.htaccessファイルに加える:
RewriteEngine on
RewriteCond %{SERVER_PORT} !^80$
RewriteRule ^(.*)$ https://www.domain.com/$1 [NC,R=301,L]
domain.comを実際のドメインに置き換える。
HTTP://からHTTPS://へ全てのページをリダイレクトするには
.htaccessファイルに次の列を加える:
RewriteEngine on
RewriteCond %{SERVER_PORT} !^443$
RewriteRule ^(.*)$ http://www.domain.com/$1 [NC,R=301,L]
domain.comを実際のドメインに置き換える。
1つのURLをHTTPS://からHTTP://にリダイレクトするには
URLがhttp://www.domain.com/mypage.htmlだと仮定する
RewriteEngine on
RewriteCond %{HTTP_HOST} !^80$
RewriteCond %{HTTP_HOST} ^www.domain.com/mypage.html [NC]
RewriteRule ^(.*)$ http://www.domain.com/mypage.html [NC,R=301,L]
15. グーグルボットを検知する
ユーザーエージェントとしてグーグルボットを検知しておくべきである。その理由は数多くあるが、皆さんの想像に任せておく。 :)
1. 次のコードを文書の「body」のどこかに切り取り & 貼り付けする
if(strstr(strtolower($_SERVER['HTTP_USER_AGENT']), "googlebot"))
{
// what to do
}
2. Replace with your content
“// what to do”を好きな指示に置き換える。
アドバイス: To make it HTML
次のコードを加える:
if(strstr(strtolower($_SERVER['HTTP_USER_AGENT']), "googlebot"))
{?>
<h1>Put your HTML here</h1>
<p>anything you’d normally do</p>
<?php
}
PHPの各パーツを分ける。
if(condition){} - this is just a simple function that says “if x is true, do y”.
次にネスト化したステートメントの内側から作業する。
‘HTTP_USER_AGENT’ - これはブラウザ特有のIDの文字列を引き出す
$_SERVER – これはヘッダー、パス、スクリプトのロケーション等、ウェブサーバーによって生成される情報を持つ配列である
strtolower – 全てのアルファベットを小文字に変えた状態で文字列を返す
strstr – 最初のneedleの発生からhaystackの最後までを含むhaystackの文字列の一部を返す
{
// what to do
}
フォワードスラッシュ // はコメントを残すためだけに用いられる。つまり、波括弧の間に望む動作を挟めばよい。
ビジュアルを好むなら – このコードは分かりやすい:

16. サイトにカスタム検索エンジンを加える
グーグルのカスタム検索エンジンは強力なツールになり得るものの、このツールを利用していないサイトは意外と多い。それでは、サイトにカスタム検索エンジンをインストールする手順を説明していく。
- http://www.google.com/cseにアクセスする
ステップ 1: タイトルとディスクリプションを作成する

ステップ 2: 検索に含めるサイトを加える
ここでちょっとしたテクニカルなノウハウが役に立つ。

サイトのURLをただ単に加えるのではなく – アスタリスク (*) をURLの後ろに加えて(例
http://www.quicksprout.com/*)サイト全体を検索することが出来るようにしなければならない。
ステップ 3: Editionを選択して、確認する

この作業を完了すると、カスタム検索エンジンをサイトに実際にインストールする前に試す機会が得られる。
Let’s check it out!

カスタム検索エンジンで[twitter tips]を検索すると、良質な検索結果が表示された。また、エンジン内のサイトのバラエティも申し分ない(プレミアム版を購入しない限り、広告が表示される点に注意)。
それでは、これからサイトにインストールするプロセスを説明する。
カスタム検索エンジンをサイトにインストールする
このタイプのインストールは、新しいページか新しい投稿のいずれかに行うことになる。例では新しいページを利用するが、新しい投稿にも同じ方法を用いることが可能である。
ステップ 1: “new page”にアクセスする

ステップ 2: HTMLモードで編集する

JavaScriptのコードをページに貼り付けるため、HTMLモードで編集を行う。
ステップ 3: コードを貼り付ける

プレビューを見る

17. 複数の言語のマークアップとグーグル翻訳
グーグル翻訳をインストールして、別の言語を話すビジターにもサイトを楽しんでもらう方法をこれから伝授する。これは割と新しいテクニックであり、利用している人はまだ少ない。そのため、早い段階で導入しておくことを薦める。
http://translate.google.com/translate_toolsにアクセスする
段階 I – コードを取得する
翻訳をサイトに実装するため、まずはオプションを選択し、コードのスニペットを生成する。
ステップ 1: ページ全体またはページの一部を翻訳するかを決める

大抵、ページ全体を翻訳したいのではないだろうか。しかし、一部のテキストを異なる言語に翻訳したい場合でも、ページの一部のみを翻訳する選択肢があるので心配しないでもらいたい。
ステップ 2: ウェブページの言語を選択する

大抵の場合、英語を選択することになる。
ステップ 3: Optional Settingsを表示させる
十字マークをクリックして、optional settingsを開く。
optional settingsを使って、サイトの翻訳を完全にカスタマイズすることを私は薦める。
翻訳される言語を選択することが出来る。

翻訳ボックスの表示方法を選択することが出来る。個人的には、「inline」と「dropdown only」が良いと思う。

さらに上級者向けの設定も用意されている。ここでは、ページを翻訳する必要がある読者に自動的にバナーを表示する。また、グーグルアナリティクスで利用を追跡する。

アドバイス: グーグルアナリティクスのIDを早く見つける方法
1. 自分のウェブページにアクセスする
2. ソースを見る
3. Control F(クロームの場合)を押して、テキストを探す
4. “ua-”(ダッシュ付き)を検索する

選択を終えたら、完成したスニペットのコードが表示されるはずだ。

ページのプレビューを見る
コードをコピーして、サイトに加える前に、翻訳ボタンのプレビューを見ることが出来る。

段階 II – コードをサイトにインストールする
これでコードの準備が整ったので、これからサイトに実際にインストールしていく。ワードプレスのようなコンテンツ管理システムを利用しているなら、割と簡単にインストールすることが可能だ。ここでは、コードを挿入するスポットを探す作業のみ説明する。
ステップ 1: 翻訳ボックスを表示する場所を決める
翻訳ボックスをインストールする基本的な場所は次の2つである。
オプション A – クイックスプラウトのように、ヘッダーのどこかに表示する:

オプション B – クックスプラウトのこのページのようにサイドバーのどかに表示する:

ステップ 2(オプション A): コードをヘッダーにインストールする
再びソースコードを確認すると、コードを挿入する必要のある場所が見えてくる:

検索ボックスとロゴの間に挿入する必要がある。
1. ワードプレスにログインする
2. 「editor」にアクセスする

3. 「Header」を選択する

4. header.phpファイルの翻訳コードを貼り付ける
翻訳ボックスを表示させる場所をコードで探し出し、header.phpファイル内でスニペットを貼り付け、保存する。

ステップ 2(オプション B): サイドバーにコードをインストールする
新しいテキストのウィジェットを作成することが出来るため、このオプションの方が少し難易度は低い。
1. ウィジェットにアクセスする

2. サイドバーに新しい「Text Widget」を加える

3. 翻訳コードをウィジェットに貼り付ける

これで完了。今後は異なる言語のユーザーにもサイトを楽しんでもらえる。
18. 悪意のある、または害をもたらす可能性のあるリンクをブロックする
時折、ハッカー、または、悪意のない経験の浅い人達が、クエリパラメータを最後に加えたリンクを送ってくることがある。例を以下に挙げる:
http://www.quicksprout.com/?neilpatelscam
(このような方法でリンクを張ってもらいたくない)
また、悪意のあるクエリの文字列が異なるページに向かわせてしまうこともある:
http://www.quicksprout.com/page/2/?neilpatelscam
http://www.quicksprout.com/page/3/?neilpatelscam
このページはそのままインデックスされ、本物のページをインデックスで置き換えてしまう可能性がある。可能性こそ低いものの、万が一の時は、修正する必要がある。以下に、そのための.htaccessのコードを掲載する:
# FIX BAD LINKS
<ifModule mod_rewrite.c>
RewriteCond %{QUERY_STRING} querystring [NC]
RewriteRule .* http://example.com/$1? [R=301,L]
</ifModule>
単純に次の手順に従ってもらいたい:
1. .htaccessがルートディレクトリに存在することを確認する。
2. このコードを.htaccessファイルの一番下に掲載する。
3. “querystring” を利用されている悪意のあるクエリ文字列と置き換える。
4. example.comをサイトのURLと置き換える。
5. 複数のクエリ文字列を加えるには、“pipes” ( | )を“or”を表現するために用いる:
例えば、neilpatelscam|quicksproutripoff|badblogger
6. 最後に1週間後または2週間後にグーグルで、次のようなsite: queryを実行して、インデックスから削除されている点を確認する:
site:quicksprout.com/?neilpatelscam
19. オンサイト分析向けのブラウザプラグイン
ブラウザプラグインは、ワークフローと効率を大幅に改善するポテンシャルを秘めている。そこで、グーグルクロームのプラグインを幾つか紹介し、高度な使い方も幾つか伝授していく。
このセクションでは、サイトのアクセシビリティおよびインデクセーションを最適する上で役に立つプラグインを取り上げる。
以下にリストを掲載する。
- Broken Link Checker - https://chrome.google.com/webstore/detail/ojkcdipcgfaekbeaelaapakgnjflfglf
- Web Developer - http://chrispederick.com/work/web-developer/
- Redirect Path Checker - https://chrome.google.com/webstore/detail/aomidfkchockcldhbkggjokdkkebmdll
- SEOmoz Toolbar - https://chrome.google.com/webstore/detail/eakacpaijcpapndcfffdgphdiccmpknp
- Chrome Sniffer - https://chrome.google.com/webstore/detail/homgcnaoacgigpkkljjjekpignblkeae
- Google Analytics Debugger - https://chrome.google.com/webstore/detail/jnkmfdileelhofjcijamephohjechhna
- Microformats for Chrome - https://chrome.google.com/webstore/detail/oalbifknmclbnmjlljdemhjjlkmppjjl
- Rulers Guides and Eyedropper Color Picker - https://chrome.google.com/webstore/detail/bjpngjgkahhflejneemihpbnfdoafoeh
- Word Count - https://chrome.google.com/webstore/detail/kmndjoipobjfjbhocpoeejjimchnbjje
- Source Kit - https://chrome.google.com/webstore/detail/iieeldjdihkpoapgipfkeoddjckopgjg?hl=en-US
次に、高度な利用方法を紹介する。
Broken Links Checker
このプラグインは、リンク切れを手っ取り早く確認することが出来るだけでなく、リンクの構築および獲得に関するアイデアを得るため、他のサイトに利用する手もある。
例えば、競合者のウェブサイトのサイトマップでこのプラグインを実行してみよう。手順は以下の通りだ:
1. 競合者のHTML sitemapを探す。例えば、ランダムに www.bizchair.comを取り上げ、サイトマップを探し出してみる: http://www.bizchair.com/site-map.html
2. Link Checkerを実行する
エクステンションのアイコンをクリックする

リンク切れが見つかるまで待つ – この例では、多くのリンク切れが見つかった。

特に目立つのは、“resources” ページである。リソースのコンテンツを再現する、または、リンクを得るために利用することが出来る。
Chrome Sniffer
このプラグインは、ウェブサイトが利用しているCMS、または、スクリプトのライブラリを自動的に表示する。例えば、ワードプレスのサイトのオーナーのみに接触したい際に、とても便利である。
ウェブを閲覧している際に、利用されているCMSやライブラリに合わせて、URLの右端のアイコンが変化する。
例えば、私のサイトはワードプレスで構築されていることが分かる

そして、ドルーパルで構築されているサイトの場合このように変化する

Redirect Path Checker
このプラグインは、リダイレクトでページに移動される際に自動的に警告を発する。ウェブを閲覧している際に、内部(または外部)で期限切れのURLにリンクを張っている場合、非常に役に立つ。
例えば、私は、たった今、Gizmodo 302リダイレクトにリンクを張っていることに気づいた:

このプラグインが302を通知してくれたため、リダイレクトに気づいたのだ。

アイコンをクリックすると、ブラウザがページに向かう上で経由したリダイレクト(または一連のリダイレクト)を表示する。

SEOmoz Toolbar & Plugin
Mozのプラグインは、様々な用途で利用することが可能である。より高度な方法を幾つか紹介する:
followedとnofollowedのリンクを早く発見する

ウェブサイトの国またはIPアドレスを発見する

【上級者向けSEOガイドの記事一覧はこちらから】
この記事は、Quick Sproutに掲載された「Chapter 1: Indexation and Accessibility」を翻訳した内容です。
圧巻の質と量を誇る記事でした。英語圏のツールを中心に紹介されていましたが、大半が日本語でも問題なく使えるものばかりですし(というか、日本で使える同種のツールは余りないですし)、日本のウェブマスターにも十分に役立つ内容だったと思います。ここまで徹底してSEOに取り組んでいるサイトも余り無いと思いますし、全てを行う必要があるわけでもないとは思いますが、ここという時に参考になる情報が満載でした。 — SEO Japan [
G+]




 先週、
先週、



 私は間抜けではない。とりわけ難易度の高い分野では、手動の取り組みが必ず行われていることは分かっている。しかし、リンク構築と言う用語は、遅く、重い足取りで丘を繰り返し登り、拡大することが出来ない取り組みを連想させてしまう。これは、(リンク構築のエキスパートではなく)SEOのエキスパートとして、受け入れることの出来ないコンセプトである。例えば、食材を揃えるために彼方此方走り回っているにも関わらず、歩いていたと友達に告げられたら、私はその表現に不満を持つだろう。私がCEOであるにも関わらず、単なる社員として、ナタリー・ポートマンに紹介されたら、全く相手にされないはずである。私達 – つまり、SEO業界の関係者 – は、どれだけ質が高く、どれだけ関連性が高くても、週に5本リンクを獲得していれば問題ないと言う基準を卒業するべきである。
私は間抜けではない。とりわけ難易度の高い分野では、手動の取り組みが必ず行われていることは分かっている。しかし、リンク構築と言う用語は、遅く、重い足取りで丘を繰り返し登り、拡大することが出来ない取り組みを連想させてしまう。これは、(リンク構築のエキスパートではなく)SEOのエキスパートとして、受け入れることの出来ないコンセプトである。例えば、食材を揃えるために彼方此方走り回っているにも関わらず、歩いていたと友達に告げられたら、私はその表現に不満を持つだろう。私がCEOであるにも関わらず、単なる社員として、ナタリー・ポートマンに紹介されたら、全く相手にされないはずである。私達 – つまり、SEO業界の関係者 – は、どれだけ質が高く、どれだけ関連性が高くても、週に5本リンクを獲得していれば問題ないと言う基準を卒業するべきである。































































































































































































































 グーグルは、先月、ウェブマスターツール内の
グーグルは、先月、ウェブマスターツール内の