
Googleは自然言語の処理や合成で大量の研究開発をしているが、それらはアシスタント機能や音声認識/合成だけが目的ではない。その中には、AIの機能でできる範囲内での楽しいものもあり、そして今日(米国時間4/13)同社は、Webの閲覧者が言葉の連想システムで遊べる実験を発表した。
最初の実験は、膨大すぎて言及される機会も少ない本のデータベースGoogle Booksの、おもしろい検索方法だ。それは、言葉そのものでテキストやタイトルを探すのではなく、データベースに質問をする。たとえば、“なぜナポレオンは流刑になったのか?”(Why was Napoleon exiled?)とか、“意識の本質は何か?”(What is the nature of consciousness?)など。
すると、その質問の言葉と密接に結びついている文節が返される。結果はヒットもあれば空振りもあるが、でも良くできているし、柔軟性もある。ぼくの質問に答えるセンテンスは、必ずしもキーワードに直接関連していないし、とくにそれら〔物理的な言葉そのもの〕を探した結果でもない。
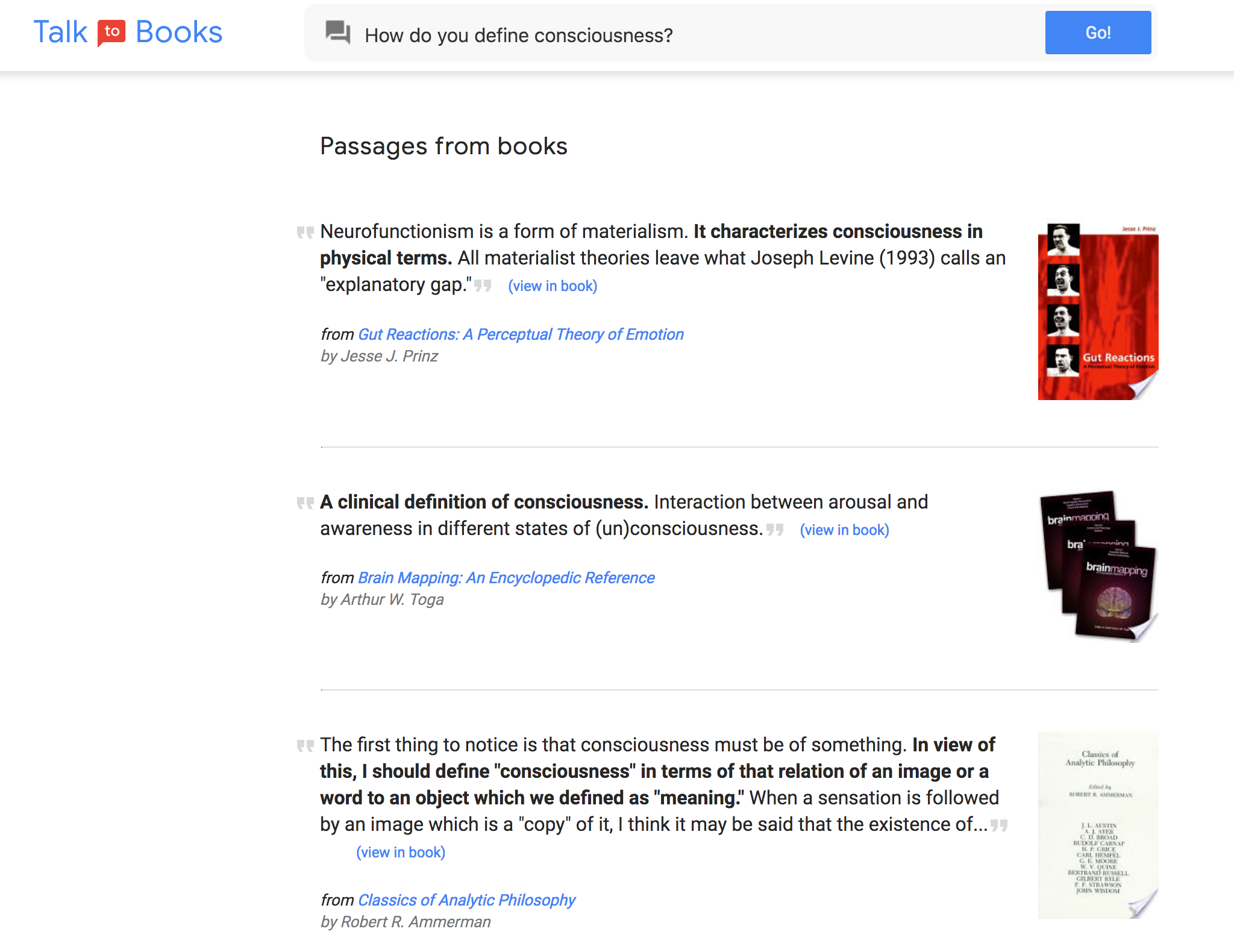
でも、それが人間と知識の内容が対話するとても分かりやすい方法か、というと、それは違うようだ。質問をするのは、答が欲しいからであり、質問と関係があったりなかったりするいろんな、互いに相反するような、引用を見たいのではない。だからぼくがこれを日常的に使うとは思えないけど、ここで使われているセマンティックエンジンの柔軟性を示す、おもしろいやり方ではある。しかもそれによって、今まで自分が知らなかった著作家に触れることができるが、ただし、データベースの収蔵書籍数は10万もあるから、当然、結果は玉石混交だ。
Googleが紹介している二つめの実験プロジェクトは、Semantrisというゲームだ。“なんとかトリス”というゲームは昔からどれも難しいが、これは超簡単だ。言葉のリストが表示されて、一つが高輝度になっている(下図)。それと関連があると思われる言葉〔連想した言葉〕をタイプすると、GoogleのAIが、関連性の強いと思う順に言葉を並べ替える。ターゲットの言葉を下に移動すると、一部の言葉が爆発して、新たな言葉がいくつか加わる。
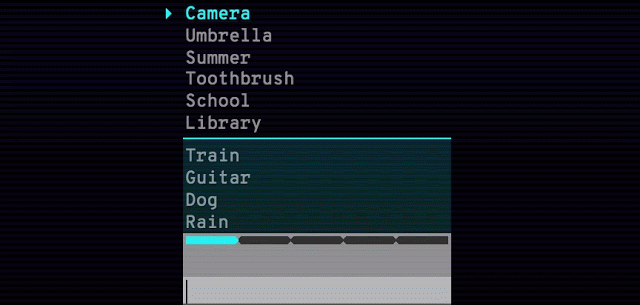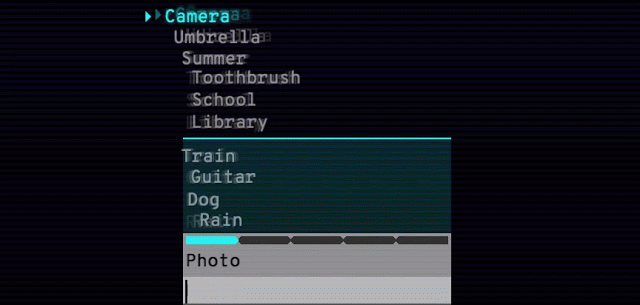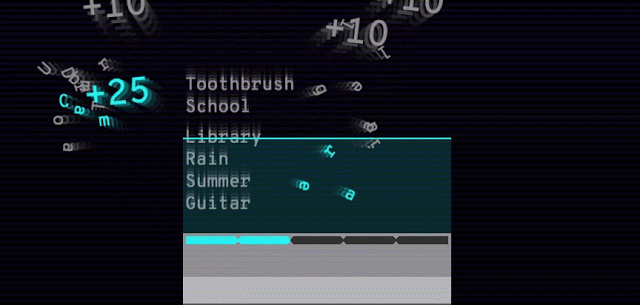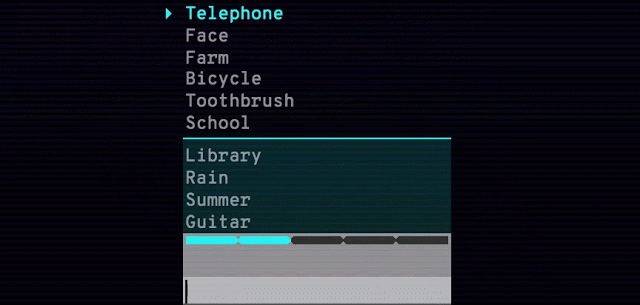
これは、暇つぶしには良いかもしれないが、やってるうちに自分が、Googleの連想エージェントの訓練に使われるモルモットになったような気がしてくる。遊び方は、とてもやさしい。でも、水(water)からボート(boat)を連想しても、誰もすごいとは思わないね。でも、やってるうちに、だんだん難しくなるのかもしれない。ユーザーの応答がAIの訓練用データとして使われるのか、今Googleに問い合わせている。
プログラマーや機械学習のマニアのためには、Googleは訓練済みのTensorFlowモジュールをいくつか提供している。そしてそのドキュメンテーションは、このブログ記事の中のリンク先の二つのペーパーにある。
〔訳注: Googleはセマンティック検索の実現を目指して、これまで多くの企業〜スタートアップの買収を繰り返している。〕