
会話を扱うコンピューターシステムにとっては、コンテキストがすべてだ。人間はそのことを意識しないけど、日常のとてもシンプルな会話でさえ、複雑なコンテキストの産物だ。会話システムが人間の能力になかなか追いつかないのも、コンテキストという難問があるためだ。しかしベルリンのRasaは、対話的な学習とオープンソースのコードを利用して、この会話するAIの問題を解決しようとしている。
そのRasa Coreというシステムのやり方は、多くのAIスタートアップと似ていて、Amazonの
Mechanical Turkのような人力サービスを利用して機械学習のモデルが持つ不正確さを修正する。ただしRasaが使うのはMechanical Turkではなく、誰でも参加できる方式で、開発中のボットと人が短い会話をし、それによりモデルを訓練しアップデートしていく。
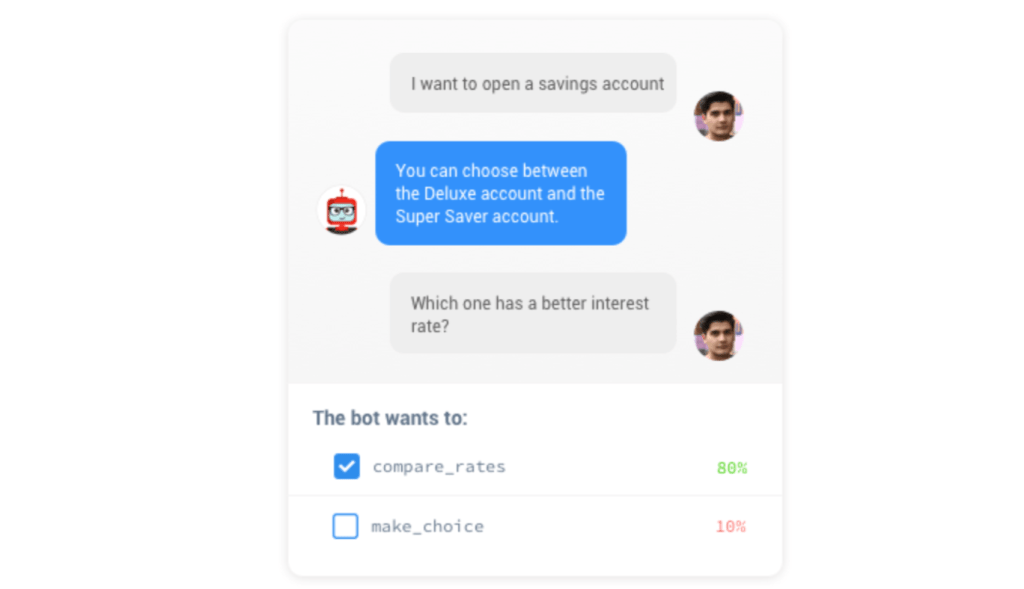
人とボットが会話をする様子を、上の図で見ることができる。上図では「利息を比較する」にチェックが入っているが、それは、ユーザーが求めている確率がもっとも高いと思われるアクションだ。それを見た人間トレーナーは、正しい/正しくないで答える。その結果をモデルは学習し、次に同じ状況に直面したら、もうその質問をしない。
Rasaのチームによると、ボットが使い物になるまでに行う人間とのサンプル会話は、数十回で十分だ。しかし、もっとたくさんやれば精度は上がるし、ユーザーフレンドリーにもなるだろう。
“IBMがWatsonで作った会話モデルを見たけど、ちょっとがっかりした”、とRasaの顧客の大手保険会社Helveticaに勤務し、会話型AIのプロマネでもあるFlorian Nägeleは述べる。“決定木が一つだけで、コンテキストをほかの木に持っていけない”、と彼はWatsonについて言う。
Rasaのよいところは、訓練データなしで顧客が自力でモデルを作れることだ。理想的には誰もがサンプル会話の自分用の大きなコーパスを持っていて、それを使って会話システムを訓練することだが、技術スタッフのいない企業では、それも難しい。
Rasa Coreは、オープンソースとしてGitHub上にある。またRasa Coreと本誌が昨年12月に取り上げたRasa NLUには、企業向け有料バージョンもある。有料版には、アドミン用管理インタフェイスや、カスタマーサポート、テストの自動化、コラボレーションによるモデルの訓練、といったサービスが付随する。