常識では考えられないリンクに関する被害妄想がまん延している。「不自然なリンクの通知」が飛び交うにつれ、もともと神経質なSEO業界は、最近、新たな境地に足を踏み入れている。
リンクの一部(サイトの規模が大きいため、数百本に達する)が、グーグルのアルゴリズムにおいて、サイトにダメージを与えているのか気になって仕方ない。外部サイトへのリンクを「rel=”nofollow”」に変えようかと思っている。出来れば変えたくないんだけど … 」
跪き、リンクスパムを行ったことを認め、許しを請おうとするサイトのオーナー達が続出している。しかし、謝罪しても、サイトをSERPに戻してもらえないケースが多い。復帰を認められるものの、ランキングとトラフィックは回復しないサイトが存在する。その一方で、同じようなリンクを持っている多くのサイトが、ペナルティを免れている。
これは、グーグルに決定権を与えるデメリットだと私は思う。
リンクの削除
サイトのオーナーが、リンクに問題があることをグーグルから告げられると、フォーラムに姿を現し、状況を説明するため、効果が数倍に増す。
グーグルは、わざわざ「不自然なリンク通知」と言う茶番をなぜ演じているのだろうか?
グーグルがあるサイトへ向かうリンクに問題がある点に気づいたなら、ウェブマスターにリンクを削除するよう促すレポートを送るのではなく、単純に削除する、あるいは、価値を軽減すればいいのではないだろうか。そして、リンクの価値を考慮しない点をウェブマスターに伝えることも出来るはずである。
グーグルの戦略はPRであり、リンクの買い手と売り手の間に爆弾を落とすための取り組みだと仮定する人もいる。なぜ、そんなことをするのだろうか?リンクはリンクでも、グーグルは、自分達が気に食わないリンクを見極めることに苦労していると思われる。
そこで、グーグルは助けを得る。
再掲載リクエスト付きのリンクの否認ツールの提供は、賢明な策だと言えるだろう。リンクを買ったことをサイトのオーナーに認めさせ、リンクを買っている場所を指摘させる、もしくは、コストをかけずに質の低いリンクのデータベースを構築することが出来るなら、これ以上優れた労働力をアウトソースするシステムは他には考えられない。
サイトを運営しており、大量のリンクを削除する必要がある場合、その作業は容易ではない。大変であり、時間がかかり、また、最終的にその努力は無駄に終わる。
多くのサイトのオーナーがリンク否認リクエストに群がり、リンクの削除に対する費用を要請する事態に発展した。リンクのオーナーを確認し、リンクを見つけ、削除し、サイトをアップデートするには、時間と労力が必要とされるため、気持ちは分かる。
明らかに辟易しているディレクトリのオーナーは次のように正直な気持ちを吐露している:
脅迫?脅迫しているのはグーグルだ。料金を払って掲載してもらったディレクトリが脅迫しているわけではない。大事なことを言っておこう。削除してもらいたいなら、私は削除料金を要求する。この作業に価値がないと思うなら、付きまとうのは止めて、これ以上eメールで無料でリンクを削除して欲しいと頼まないでくれ。
リンクを探し、削除して、削除されたことを確認し、eメールを送信して確認する。5分間で終わる。そのためには29ドル支払ってもらう。それが嫌ならeメールを送らないでくれ。一分たりとも無料で働かなければいけない義務はない。29ドルと言う料金設定が脅迫に近いと指摘するeメールが送られてきたことがある。そのため、29ドルではなく – 新たに109ドルを要求することに決めた – これが脅迫だ。
念の為に言っておくが、グーグルのランキングを操作することを理解して、料金を支払ってディレクトリにリンクを掲載してもらい、今度は、自分のグーグルのランキングを再び操作するために、料金を支払ってディレクトリから抜け出す。自分で決定を下した点を忘れないでもらいたい。誰かのせいにして不満を言うのは筋違いだ。自分の失敗の後始末は自分一人でつけてくれ。
なるほど。
いずれにせよ、当該のリンクが実際にサイトにダメージを与えているなら – 議論の余地はあるが – 次の展開は誰にでも読めるはずである。サイトのオーナー達は、ディレクトリに対して、大量に、そして、迅速に競合者のリンクを投稿することになる。
それでは、ネガティブSEOについてマット・カッツ氏に語ってもらおう….
回復する保証はない
多くのサイトは、どんなことをしても、グーグルのペナルティから回復することが出来ないだろう。
どれだけ懺悔しても、印が消えることは永遠にないと考えられる。グーグルは、アドワーズで過去の行動を考慮に入れている。そのため、同じような印が自然な結果でも永遠に残ると考えても、決して飛躍し過ぎているとは言えないはずだ。
サイトが現在推進している取り組みではなく、過去に推進した取り組みが要因になっている。
なぜグーグルは過去の取り組みを恨んでいるのだろうか?恐らく、何年も前に、アフィリエイトがかつてドメインをかき回し、葬っていたやり方を問題視しているのではないだろうか…
これが、一部の回復したサイトが、以前よりもランクが落ちている理由なのかもしれない。永遠にマイナスの印を背負っていかなければならない可能性がある。
しかし、実際にサイトがSERPに復帰した際に、ランキングとトラフィックが落下していたとしても、それが質の低いリンクや過去の行動と全く関係がないこともあり得る。ランク付けにはその他にも多くの要素がある。また、グーグルのアルゴリズムのアップデートは、じっとしているわけではないため、原因を突き止めるのは容易ではない。
SEO業界が妄想に走っているのはこのためだ。
ブランドは逃げられるのか?
マット・カッツ氏は、大きなブランドもペナルティーの対象だと明言している。Interflora UKの件を覚えているだろうか?
グーグルは確かに大きなブランドにも罰を与えているのかもしれないが、無名のサイトに対して課される罰とは全く異なる罰が与えられているようだ。ユーザーが期待するサイトがSERPに存在しない場合、グーグルの立場が危うくなるため、大きなブランドは、容易に復帰することが出来る。
BBCが – 楽しそうに – 説明したこのレポートが典型的な例である:
私はBBCのサイトを代表する立場にある。土曜日、BBCは「検知された不自然なリンクの通知」を受けた。BBCのサイトは巨大であり、また、個々にサブセクションが乱立し、大勢のオーサーやエージェントが関与している。そのため、当該の「不自然なリンク」が存在する場所のヒントを教えてもらえると有難い。
私がBBCのウェブマスターだったら、通知を無視するだろう。グーグルはBBCのサイトのランクを落とすことはない。なぜなら、自分達のイメージが悪くなるからだ。BBCに向けられたリンクの一部を問題視しているなら、グーグル自身が問題を解決するべきである。
辛抱して、前に進め
アグレッシブなリンクスキームに関わったなら、ゲームの仕組みを理解していたはずである。関連性を人為的に押し上げることを望み、そして、リンク構築を行った結果、SERPでのランクの上昇を勝ち取ったのだ。
これは、被リンクを考慮するグーグル、つまり検索エンジンが“デザイン”した仕組みを操作していることになる。グーグルは意図的に多くのリンクが向けられたサイトを少ないサイトよりも上位にランク付けする。
サイトのオーナーは、あまりアグレッシブな手法を利用しない競合者を傍目に、この成果を存分に味わった。この取り組みの短所は – どんな取り組みにも弱点は付きもの – 関連性において、グーグルに人為的な後押しを見つけられたら、ドメインを葬られるリスクがある点である。
これもゲームの一部である。
抗議を行うウェブマスターもいるが、グーグルは全く関心を持っていない。そのため、最初からこのリスクを考慮しておく必要がある。
戦略的な面で、主に2つの視点でこの“ゲーム”を見ることが出来る:
モグラたたき: 負けを見越してアグレッシブなリンク構築を行う。叩かれたら、それはこの試みを行う代償だと考える。様々なドメインを運営し、異なるリンクグラフを用意する。常に一部が生き残り、ゲームに切れ目なく参加することを願う。一部のドメインが打撃を受けたら、我慢する。復活させる試みを行うものの、うまくいかなかったら諦めて前に進む。
グーグルを無視する: グーグルの存在を無視してサイトを運営すれば、グーグルからペナルティを課される可能性は低い。ただし、成功の保証はない。いずれにせよ、ペナルティと低いランキングは、結果においては同等の意味合いを持つ。
一歩離れて状況を見てみよう。グーグルのランキングにビジネスを依存している場合、これも立派なリスクである。背負う価値のあるリスクではないと指摘しているわけではない。あくまでも、ビジネスにとって負う価値のあるリスクかどうかは、当事者にしか分からない。
モグラたたき戦略が自分のビジネスに向かず、グーグルの逆鱗に触れるリスクを減らしたいなら、トラフィックを得る手段を多様化して、トラフィックのソースが一つなくなっても、ビジネス全体を失わないように工夫する価値はある。長期的にビジネスを運営するつもりなら、ブランドを確立し、トラフィックを多様化し、そして、自然なSEOのトラフィックをボーナスとして対処する方針を検討してもらいたい。そうすることで、グーグルへの依存度が大幅に減るため、グーグルが何をするにせよ、あまり心配しなくて済む。
2つの戦略を同時に用いるサイトもある。これはリスク管理の手法として理解できる。大半のサイトのオーナーは中間に位置し、最善の結果を期待する。
前進するリンク構築
グーグルの恐れ、不安、そして、疑いをベースとした戦略により、怯える、または、混乱する、あるいは、その双方に該当する数多くのサイトのオーナーが続出するだろう。
何が許容されているのだろうか?
問題は、現在許容されている行為が、来週には許されない可能性がある点である。サイトのオーナーが、あるリンク戦略を採用したら後戻りするのは不可能に近く、また、数年後に何が禁止されているのか誰も分からない。
当然ながら、リンク戦略の目的が“ランキングを高める”ことなら、グーグルはサイトのオーナーに「リンク戦略」を考えてもらいたくないはずである。この点に関しては、グーグルの方針は変わっていない。
リスクの低いアプローチを望むなら、グーグルのトラフィックをおまけとして考えた方が得策だ。ウェブマスターワールドを設立したブレット・タブキ氏は、「検索エンジンは存在しないものだと思え」、または同じようなメッセージが綴られたステッカーをモニターに貼っていた。SEOを超えた戦略的な思考を促されるため、今こそこのステッカーが役に立つのではないだろうか。グーグルからサイトが消えても、ビジネスを引き続き運営することは出来るだろうか?その答えがNoなら、戦略を考え直すべきである。
妥協案は考えられるだろうか?
時の試練に耐えられる可能性があり、グーグルの気まぐれな行動にも負けない戦略を組み込んだ、リンク構築に対するアプローチを幾つか紹介する。全てのアプローチにおいて、リンクの価値の一部がランクの高さであれ、SEO以外の理由でリンクを獲得する点が鍵を握る。
1. パブリッシャー
オーディエンスにとって関連する、有益なコンテンツを配信する。
あるトピックに関する情報を掲載したページを投稿するだけでは不十分であり、情報の実用性を証明する必要がある – 要するに、他の人達が情報を有益であると見なし、参照し、アクセスし、そして、話題にしている必要がある。資金をリンクの購入に費やす代わりに、コンテンツの作成、そして、オーディエンスへの宣伝に資金をつぎ込もう。 するとリンクが自然に集まる可能性が高くなる。受動的にリンクを獲得するのだ。
このタイプのリンクが集まってくる分には、リンクグラフは自然に見え、要な特徴にはならないため、問題視されないだろう。その他のシグナルがこの特徴を打ち消し、インパクトを抑えてくれる。
固有で、質の高い情報を基にしたブランドを構築し、複数のチャンネルを介して売り込むことで、リンクが集まり、その結果、グーグルのランキングが引き上げられる傾向が見られる。何よりもハイレベルな実用性を証明するべきである。
このモデルの問題点は、その他のサイトに容易に実用性を盗まれてしまう点だ。これは大きな問題であり、質の高いコンテンツへの投資を躊躇させている。この問題を回避する方法として、一部のコンテンツを客寄せ目的で使って、残りを有料線にする手が考えられる。十分な量のコンテンツをオーディエンス、そして、グーグルに公開し、そして、残りを見たい人に登録を求めるのだ。
コンテンツの全てをクローラーに与える見返りについては慎重に考える必要がある。「コンテンツ」ではなく「実用性」を与えることを重視してもらいたい。
2. 差別化
リンクの獲得に関しては、先発者利益が大きい。
新しい分野が開拓され、誰よりも早く、または、早い段階でその分野に進出すると、比較的に簡単に信頼できるリンクグラフを構築することが出来る。分野が拡大し、新たな層のアクティビティが活発化し、- ブロガー、メディア、そして、その他の情報のキュレイターがコンテンツの作成を始める。あらゆるニッチに共通することだが、スタート地点では、話題になる人数が限られるため、早く行動を起こすと全てのリンクを手に入れることが出来る。
分野が成熟していくと、マイク・グレハン氏が巧みに表現しているように「汚れたリンクが増加」する。
ウェブの新しいリンクは既に多くのリンクを持つサイトに向かう傾向があり、基本的にこの構想は新しいページや知名度の低いページとって不利である。検索エンジンが、人気の高いページを毎回上位にランク付けすると、このページを発見し、リンクを張るユーザーが増えていく。
早い段階でこのように全てのリンクを獲得したサイトは、結果の上位に掲載されるため、時間の経過とともに更にリンクの本数を増やしていく。今の行動を続けていればよい。何か常識を超えた行動に出なければ、後に参加したサイトが古株のサイトに打ち勝つことは難しい。常識を超えた行動とは、本質的に、新しいニッチへのシフト変更を意味する。
競争の激しい分野に遅れて参加しているなら、差別化について本気で知恵を絞りだす必要がある。その他のサイトとは異なり、何を提供することが出来るのだろうか?このような分野では卓越したコンテンツが要求される – 取り上げる価値のあるコンテンツが求められているのだ。
当該の分野は新たな方向に向かって動いているだろうか?もしそうなら、この方向に狙いを定め、誰よりも早く動きだすことが出来るだろうか?ニッチの現在の場所ではなく、今後向かう場所を察知し、予めその場所に向かうのだ。
「ありきたり」のコンテンツは、リンクを張ってもらえず、興味を持ってもらえず、上位にランク付けしてもらえず、話題に上げてもらえない – 当然だ。ウェブは、コンテンツには不足していない。ウェブには無数のコンテンツが存在し、グーグル等の企業が対処可能な10本のリンクに縮小し、大儲けしている。
3. ブランド
ブランドはグーグルから身を守る究極の戦略である。
ブランドだからと言って、グーグルのペナルティから逃れられるわけではない。実際に、ブランドもペナルティを科されている。しかし、科される量刑に差がある。ブランドの規模が大きければ大きいほど、量刑が少ない、もしくは短い。なぜなら、ウォルマートやアメリカ政府がどれだけグーグルをスパムしても、グーグルはこのようなサイトを表示せざるを得ないのだ。この2つのサイトがアグレッシブなSEOの戦略を採用している、または、その必要があるわけではないが、確実にグーグルに掲載してもらえる。
大きなブランドである必要はない。ただし、固有のブランド名に関してある程度の量の検索が行われている必要はある。当該のニッチで十分に知られているなら、- つまりタイプインの検索が十分に行われているなら、グーグルはブランドをSERPに表示させなければならない。さもなければ質の低い検索結果だと思われてしまう。
だからと言って、低俗な行動を取っても許されるわけではない。しかし、タイプインのトラフィックが多ければ多いほど、グーグルにかかるプレッシャーは大きくなり、上位に格付けしてもらいやすくなる。
ブランドネームに向かうリンクは、フッターの「オンラインで激安価格の薬を購入」等のリンクと比べ、無理やりリンクをを張っているようには見えない。リンクを張る側はブランドの名前を知っており、- 自然に – 名前を使ってリンクを張り、名指しで話題に取り上げている。
サイトが包括的であればあるほど、弱くなる。なぜなら、包括的なキーワードの用語に合わせている場合、当該のスペースを自分のものにするのが難しくなるためだ。常に若干 – あるいは大いに – 無理やりリンクが張られているように映ってしまう。
キーワードが掲載されたリンクを得ても構わないが、固有のブランドを確立する取り組みも忘れずに行ってもらいたい。そうすることで、当然ながらリンクグラフは自然に見えるようになる。質の低いリンクが数本あったところで、多くの自然なブランドリンクが作り出す良いシグナルを踏みにじる結果にはならないだろう。
4. エンゲージメント
ウェブは“場所”である。
この場所には大勢の人々が存在する。そして、人と人の間には関係が存在する。ウェブ上の人と人の間の関係は、リンクとして表現されることが多い。フェイスブックのリンクかもしれないし、ツイッターのリンクかもしれない。コメントのリンクやブログのリンクの可能性もあるが、リンクであることに変わりはない。クロール可能かどうか、no-followかどうかに関わらず、リンクは関係を表す。
グーグルが生き残るためには、この関係を理解しなければならない。
だからこそ、- ネガティブSEOを除く – 全てのリンクは価値を持つ。実際の関係のシグナルが多ければ多いほど、客観的に見て関連性が高いため、より上位にランク付けされる*べき*である。
そのため、関係とエンゲージメント(交流)を育む方法を探してもらいたい。ゲスト投稿かもしれないし、別のサイトにコメントを投稿する行為かもしれない。フォーラムに寄稿することだって出来る。インタビューを実施する手もある。インタビューを受ける側に回っても良い。会社との関係を構築することも可能だ。チャリティーへの貢献かもしれない。カンファレンスの参加なのかもしれない。影響力を持つ人物への接触がこの方法に該当する可能性もある。
全てに共通するのは、ネットワーク作りである。
そして、ネットワーク作りを行うと、副産物としてリンクが付いてくる。
長い – 400ワード以上 – の固有の記事を提供する必要がある。リンクを張ってもらい、読者に没頭してもらい、コンテンツファームではなく、オーディエンスが実際にアクセスするサイトに掲載する必要がある。
「実用的かどうか」自分自身に問いかけてもらいたい。
5. ニーズを満たす
このポイントは、差別化に似ているものの、若干焦点が絞られていると言える。
ある分野でオーディエンスが抱えている問題について考えてみよう。解決するのは困難な問題だ。「how to」、「ヒント」、「アドバイス」等々。
難問を解決すると、とりわけ本来ならば料金を支払わなければならない場合、オーディエンスは、義務感を持つようになる。この義務感をリンクの獲得に結びつけることが出来るなら、都合がよい。例えば、「この記事/動画が役に立ったとしても、料金を支払う必要はありません。その代わりに、リンクを張る/ツイッターでフォローしてもらえると嬉しいです」等のメッセージを送る手が考えられる。ここまであからさまに訴える必要はないが、時には露骨なアピールが求められることもある。こうすることでエンゲージメントは促され、ネットワークが作られ、リンクは構築されていく。
リンクに結びつくコール・トゥ・アクションを盛り込む方法を考案してもらいたい。
最後に
ちなみにシーザーズパレスはグーグルを拒否したようだ :)
この記事は、SEO Bookに掲載された「Link Madness」を翻訳した内容です。



















 グーグルの4度目のペンギンアップデート –
グーグルの4度目のペンギンアップデート – 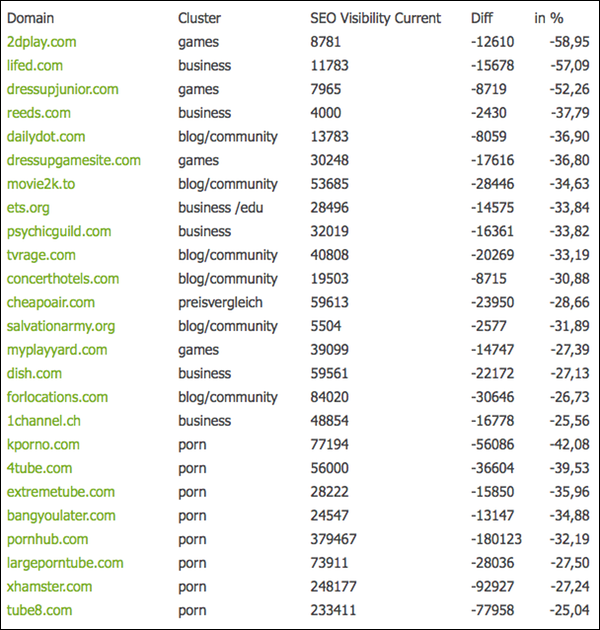

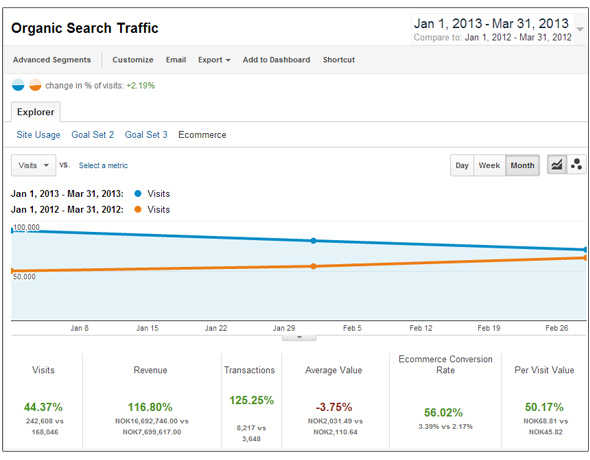

 先週のグーグル I/Oカンファレンスでグーグルが
先週のグーグル I/Oカンファレンスでグーグルが







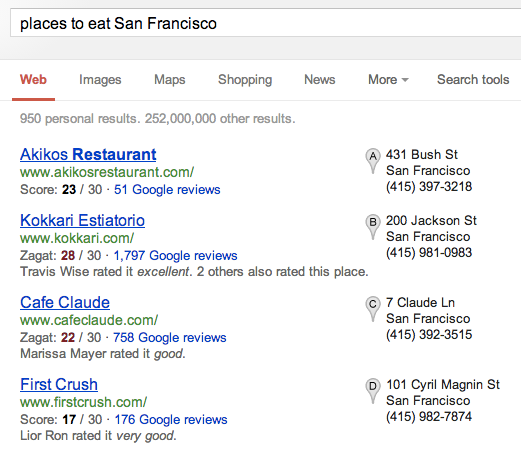



 グーグルグラスの「エクスプローラ」版には7つの音声コマンドが搭載されている。6つのうちの2つは検索に関連している – [google]と[get directions to](~へのルートを調べる)。その他の音声コマンドは、[take a photo](写真を撮影する)、[record a video](動画を録画する)、[make a call to](~に電話する)、そして、[start a Hangout with](~とハングアウトのチャットを始める)である。
グーグルグラスの「エクスプローラ」版には7つの音声コマンドが搭載されている。6つのうちの2つは検索に関連している – [google]と[get directions to](~へのルートを調べる)。その他の音声コマンドは、[take a photo](写真を撮影する)、[record a video](動画を録画する)、[make a call to](~に電話する)、そして、[start a Hangout with](~とハングアウトのチャットを始める)である。