Microsoftが今日(米国時間8/16)、Azure系列の新製品をプレビューとして発表した。それは、イベントベースのアプリケーションを作りやすくするためのツールだ。
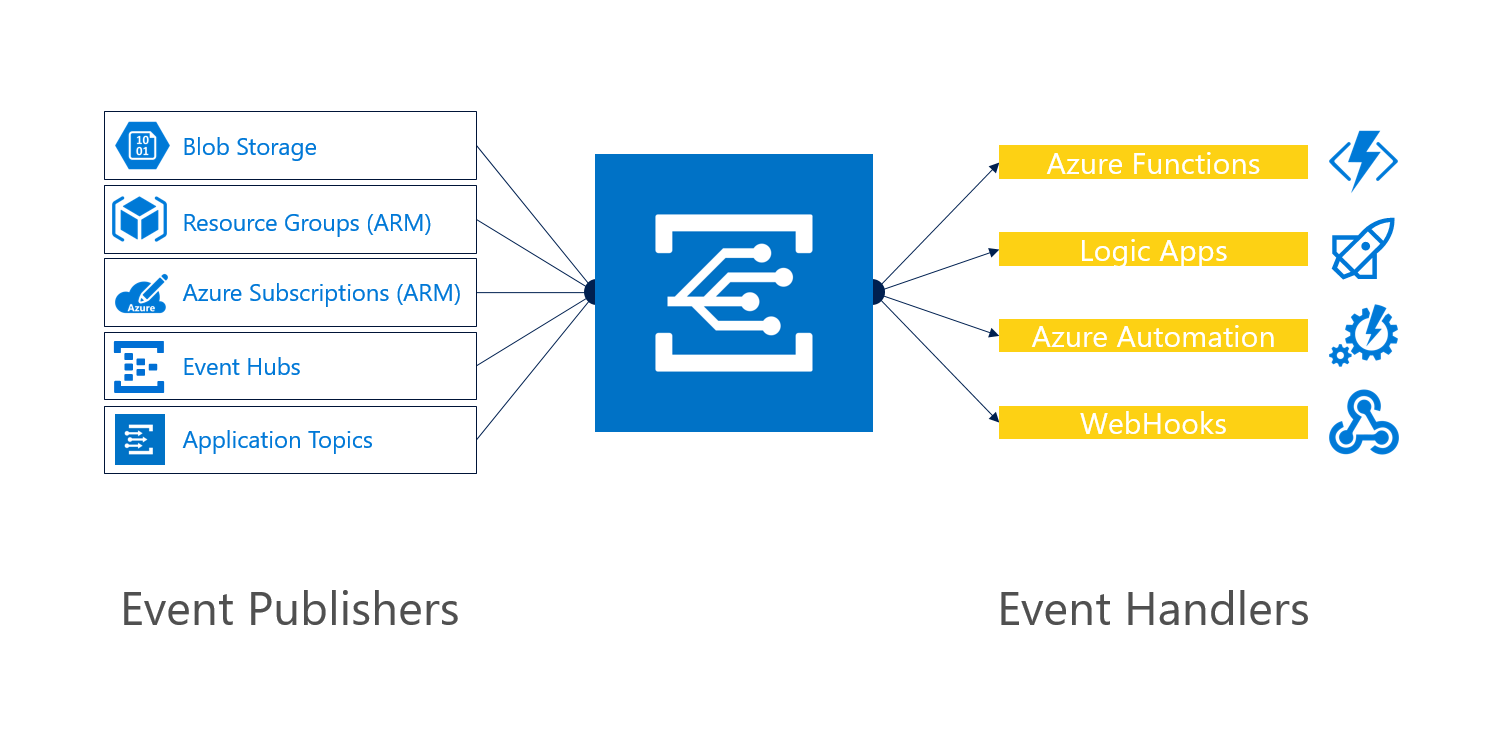
そのAzure Event Gridは、画像やビデオがアップロードされた、ボタンがクリックされた、データベースがアップデートされた、などなどのイベントをAzureの正式のオブジェクトとして扱う。Event GridはMicrosoftの既存のサーバーレス製品Azure FunctionsやAzure Logic Apps(の足りない機能)を補完して、完全に管理されたイベントルーティングサービスへのアクセスを与える。この新しいサービスにより、どんなイベントに対しても、それを受け入れて反応する柔軟性が与えられる。それらは、Azure内部で起きるイベントでも、あるいはサードパーティのサービスや既存のアプリケーションで起きるイベントでもよい。
Event Gridを使うと、イベントを特定のエンドポイント(あるいは複数のエンドポイント)へルートしたりフィルタできる。
“サーバーレス”という言葉は、最初から一貫して誤称だ。たしかにアプリケーションはサーバーを呼び出さないけど、イベントに応じて何かをやるのは依然としてサーバー、というかサーバー上のコードだ。サーバーレスプラットホームの基本的なコンセプトは、このモデルではイベント駆動のアプリケーションを、それを支える低レベルのインフラストラクチャ(サーバーなど)をまったく気にせずに作れる、という点にある。
たとえば、MicrosoftのAzure ComputeのディレクターCorey Sandersによると、Event Gridは、マイクロサービスを作るためのMicrosoftのプラットホームService Fabricの上にあるが、デベロッパーはそのサービスについて何も知る必要がなく、プラットホームがすべての面倒を見る。
Event Gridはwebhookのエンドポイントとして、どんなアプリケーションからでも入力を取れるから、Azure FunctionsやLogic Appsなどよりもやや進んでいる。“目標は、顧客が管理でき操作できる正式のオブジェクトとしてのイベントを提供することだ”、と、Sandersは語る。基本仕様としてEvent Gridは、Azure Blog StorageやResource Manager, Application Topics, Event Hubs, Azure Functions, Azure Automation, そしてLogic Appsをサポートしている。またCosmosDBデータベースサービスやIoT Hubなどの新しいサービスも、年内にはサポートされる。IoTアプリケーションはイベント駆動が定石だから、IoT Hubのリリース時点でイベントのサポートがなかったのが、むしろ意外だ。
標準的なサーバーレスアプリケーションとインテグレーションはLogic Appsがあれば十分かもしれないが、Event Gridを使えばオペレーションのワークフローの一部を自動化でき、たとえば新しい仮想マシンやデータベースの立ち上げなどにも、自動的に対応できるようになる。
Event Gridの料金は処理するオペレーションの数による。最初の10万オペレーションは無料、そしてその後、100万オペレーションごとに60セントだ。現在のプレビューの時点では、30セントとなる。ひとつのオペレーションは、入力処理、高度な数値演算、デリバリの試み、管理タスクの呼び出しなどだ。