
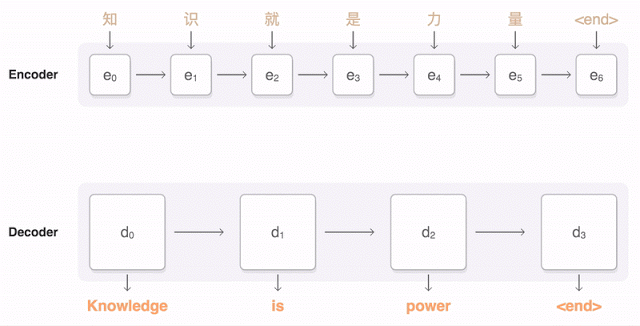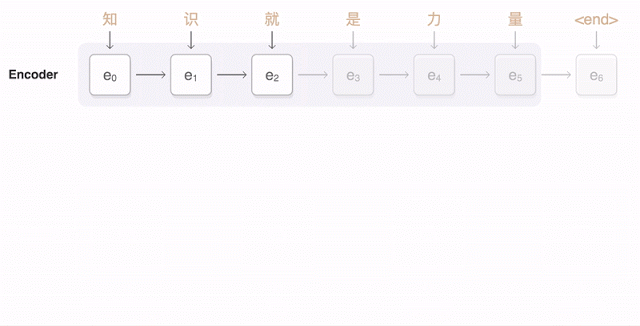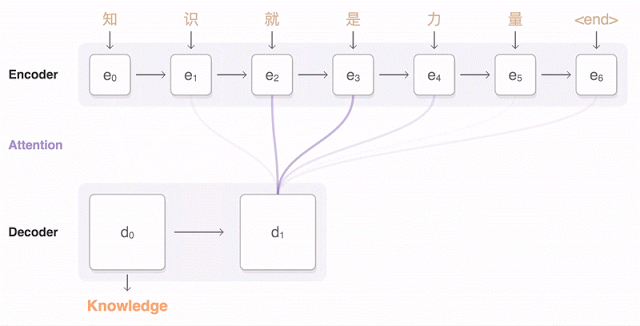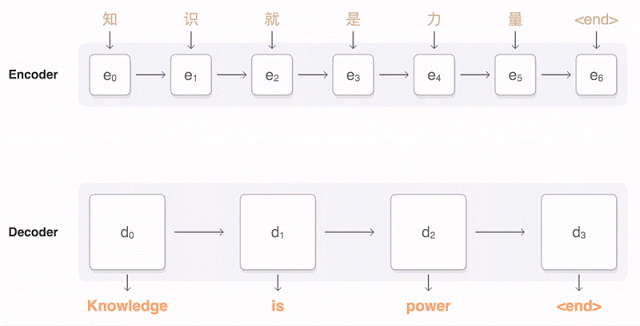
部屋の向こうから誰かがあなたにボールを投げて、あなたがそれをキャッチする。実にシンプルだ。実のところ、これは私たちが理解しようとしてきたプロセスの中でも最も複雑なものの1つだ – ましてや再現は困難だ。私たちが見るように見ることができるマシンを発明することは、見かけ以上に困難な仕事だ、コンピューターにそれをやらせることが難しいというだけでなく、そもそも私たち自身がそれをどのようにやっているのかがはっきりしないからだ。
実際に起こっているのはおおよそこのなようなことだ:ボールのイメージがあなたの目を通過して網膜に映る、そこである程度の基礎的な解析を行い、その結果を脳に送る、そして視覚野がイメージをより徹底的に解析する。そして、その後解析結果は皮質の残りの部分へと送り出される、そこでは既に知っている全てのものと結果が比較され、物体と寸法を分類し、最終的に何を行うかを決定する:腕を上げてボールを掴む(その軌跡を予測しながら)。このプロセスはほんの一瞬で行われて、意識的な努力はほぼ不要だ、そして多くの場合決して失敗しない。だから、人間の視覚を再現することは、単に1つの困難な問題ではないのだ、それは複数の困難な問題の集まりで、お互いが他に依存している。
まあ、これが簡単だろうと言った人はいない。おそらく、AIのパイオニアである、マービン・ミンスキーを除いては。彼は1966年に1人の大学院生にこのような有名な課題を与えた「カメラをコンピューターに接続して、それが見ているものを記述させなさい」。学生に同情を禁じ得ない:50年後、私たちはまだその課題に取り組んでいるのだ。
本格的な研究は、50年代に始まり、3つの異なるラインに沿って進んだ:目を複製する(難しい)。視覚野の複製(非常に難しい):そして脳の残りの部分の複製(ほぼ間違いなくこれまで試みられたものの中で最も困難)。
見ること
目の再発明は、私たちが最も成功を収めてきた領域だ。過去数十年にわたって、私たちは人間の目の能力に匹敵し、ある部分ではその能力を凌ぐほどの、センサーや画像処理装置を作成してきた。より大きく、より光学的に完璧なレンズと、ナノメートルスケールで製造された半導体サブピクセルのおかげで、現代のカメラの精度と感度は信じられないという他はない。カメラはまた、毎秒数千ものイメージを記録し、高い精度で距離を検出することができる。

デジタルカメラの中によく見ることができるイメージセンサの1つ
しかし、出力の忠実度は高いにもかかわらず、これらのデバイスは多くの点で、19世紀のピンホールカメラより優れているとは言えない:それらは単に与えられた方向から来る光子の分布を記録しているだけなのだ。これまでに作られた最も優れたカメラセンサーでもボールを認識することはできない — もちろんそれをキャッチするなんて事もできそうもない。
別の言葉で言えば、ハードウェアはソフトウェアが存在しないと極めて機能が限られてしまう — それが解くべき、より重要な問題なのだということが分かったのだ。とはいえ、現代のカメラ技術は、撮影のためにリッチで柔軟なプラットフォームを提供している。
記述すること
ここは、視覚神経解解剖学についての完全なコースを提供する場所ではないが、私たちの脳は、言ってみれば、視覚を意識して、ゼロから構築されているのだと言えば十分だろう。脳の大部分は他のどのようなタスクよりも視覚に割り当てられている、そしてその専門化は細胞に至るまで全部が関連している。数十億のそれらの細胞が一緒に働き、網膜から送られたノイズだらけで無秩序な信号からパターンを抽出する。
もし特定の線上に特定の角度でコントラストがあったり、例えば、ある方向へ急な動きがあった場合に、神経細胞の集合がお互いを刺激する。より高いレベルのネットワークが、これらのパターンをメタパターンへと集約する:上方に移動している円、のように。そこへ別のネットワークが話に加わる:円は白く、線は赤い。また別のネットワーク:そのサイズは成長している。1つの画像が、これらの粗く補完的な記述から現れ始める。

「勾配方向ヒストグラム(HOG:histogram of oriented gradients)」が、脳の視覚野に見られるような技術を用いて、エッジや他の特徴を見つける
これらのネットワークを、計り知れない複雑なものと考えた初期のコンピュータービジョンの研究は、違うやり方を採用した:「トップダウン」アプローチだ — 本は/この/ように見えるので、/この/ようなパターンを探せ。もし横置きされていないなら、/この/ように見えるだろう。車は/この/ように見えて、/この/ のように移動する。
私たちは、私たちの心がどのように働いているかに関しての、使える定義をほとんど持っていない。それをシミュレートすることは更に困難だ。
制御された状況下で少数のオブジェクトを扱うなら、このやり方は上手く行った、しかし身の回りの全てオブジェクトを記述しようとすることを想像して欲しい。あらゆる方向から様々な光と動きがやってきて、数百ものその他の要素があるのだ。幼児レベルの認識を達成することでさえ、非現実的に巨大なデータセットを必要とすることが明らかになった。
脳内で発見されたものを模倣する「ボトムアップ」アプローチは、より有望だ。コンピュータはイメージ対して連続した変換を適用し、予測されるオブジェクト、複数の画像が示されたときの遠近や動きなどを発見することができる。このプロセスは、大量の数学と統計計算を伴うが、要するにコンピューターは見たものを、既に認識するように学習していたものとマッチングさせようとしているだけのことだ — 私たちの脳がそうであるように、他の画像で学習したものを使うのだ。

上のようなイメージ(パデュー大学のE-labより)が示しているものは、コンピューターが計算によって、注目したオブジェクトが他の例の中の同じオブジェクトのように見え、似た動きをすることに、ある統計的確信度のレベルまで達したことを表示している。
ボトムアップアーキテクチャの支持者たちは「だからそう言ったじゃないか」と言うだろう。しかし、つい最近まで、人工ニューラルネットワークの構築と運用は非現実的だった、なぜなら必要な計算量が膨大だったからだ。並列コンピューティングの進歩は、これらの障壁を打ち破りつつあり、ここ2、3年は私たちの脳の中を模倣する(もちろんまだ概略レベルだが)システムの、構築と利用の研究が爆発的に増えている。パターン認識のプロセスは桁違いに高速化されていて、私たちは日々進歩を重ねている。
理解すること
もちろん、あなたはあらゆる種類のリンゴを認識するシステムを作ることができる、すべての角度から、どのような状況でも、止まっていても、動いていても、少々齧られていても、どのような場合でも — そして、そのシステムはオレンジを認識することはできない。さらに言えば、そのシステムは、リンゴとは何か、それは食べられるものなのか、どれほど大きなものなのか、あるいは何に使われるものなのかに答えることさえできないのだ。
問題は、良いハードウェアとソフトウェアがあっても、オペレーティングシステムがなければあまり役に立たないということだ。

私たちにとっては、それが私たちの心の残りの部分なのだ:短期並びに長期記憶、私たちの他の器官からの入力、注意と認知、本当に膨大な世界とのインタラクションを通じて学んだ、これまた膨大なレッスン、私たちがかろうじて理解した手法で書かれた、これまで私たちが出会ったどのようなものよりも複雑な相互接続されたニューロンのネットワーク。
コンピュータビジョンの将来は、私たちが開発した、強力なしかし特定の役にしかたたないシステムを、より大きなものと統合するところにある
ここが、コンピュータ科学とより一般的な人工知能のフロンティアが集まる場所だ — そして私たちが大いに空回りをしている場所なのだ。コンピュータ科学者、技術者、心理学者、神経科学者そして哲学者の間で、私たちは、私たちの心がどのように働いているかに関しての、使える定義をほとんど持っていない。それをシミュレートすることは更に困難だ。
とはいえ行き止まりに来たという意味ではない。コンピュータビジョンの将来は、私たちが開発した、強力なしかし特定の役にしかたたないシステムを、捉えることが少し難しい概念(文脈、注意、意図)にフォーカスしたより大きなものと、統合するところにある。
とは言っても、たとえ初期の段階であるとしても、コンピュータビジョンは、非常に有益なものだ。それはカメラの中に入って、顔と笑顔を認識している。それは自動運転車の中に入って、交通標識を読み取り歩行者に気をつけている。そしてそれは工場のロボットの中に入り、問題を監視し、人間の作業者の周りでナビゲーションを行っている。それらが、わたしたちと同じように見ることができるようになるまでには、(もしそれが可能だとしても)なお長い年月が必要だが、現在手にできている仕事の規模を考えると、彼らが見ているということは素晴らしいことだ。
[ 原文へ ]
(翻訳:Sako)

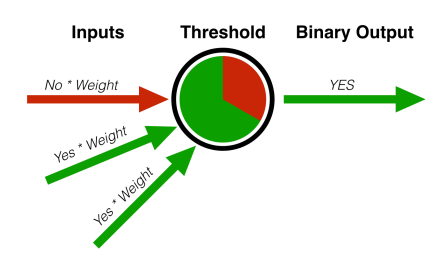
 パーセプトロンは、機械学習の分野で行われた多くの初期の進歩の、ほんの1例に過ぎない。ニューラルネットワークは、協力して働くパーセプトロンの大きな集まりのようなものである。私たちの脳や神経の働き方により似通っていて、それが名前の由来にもなっている。
パーセプトロンは、機械学習の分野で行われた多くの初期の進歩の、ほんの1例に過ぎない。ニューラルネットワークは、協力して働くパーセプトロンの大きな集まりのようなものである。私たちの脳や神経の働き方により似通っていて、それが名前の由来にもなっている。












{kind=link}