
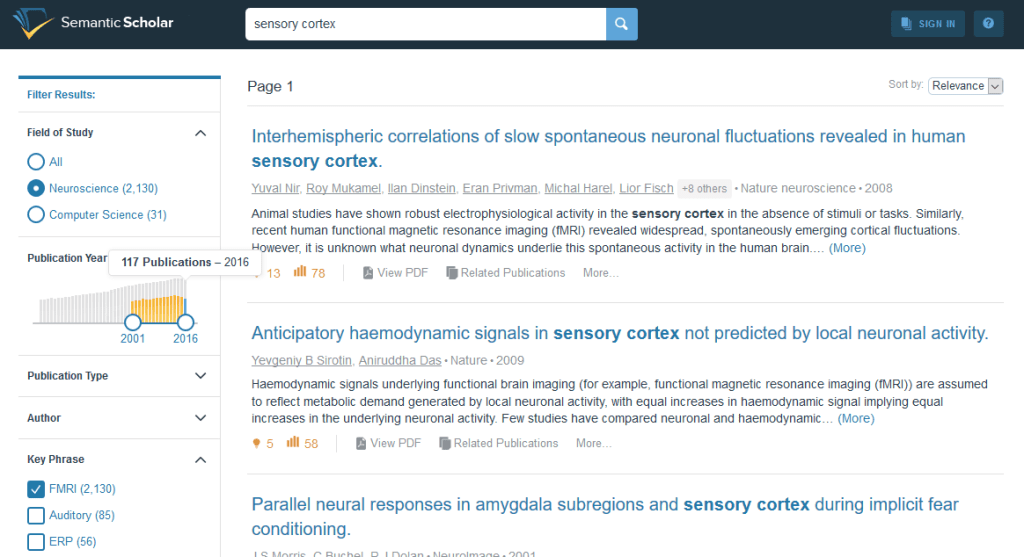
科学論文はかなりの頻度で発行されており、主要な分野の最先端にいる人が論文の情報を追おうとすると、それだけでフルタイムの仕事になってしまうほどだ。しかし、論文サーチエンジンのSemantic Scholarは、自動で論文を読み込み、トピックやその影響力、引用回数などの情報を取り出す機能を備えており、ユーザーは簡単に最新の論文や探しているものをみつけることができる。
もしもあなたが科学者であれば、きっとこのようなサービスを求めていたことだろう。Google ScholarやPudMedも便利なリソースではあるが、メタデータに関しては、著者や論文の引用回数や実験対象となる有機体、使われている共変数など比較的基礎的なものしか含まれていない。
Semantic Scholarは、特定分野の論文を10万本以上読み込んだデータを参照し、重要なフレーズを探しながら、新しい論文の文章全てを分析する。自然言語処理能力も備えているため、ある論文が独自の実験を基に書かれているのか、他人の実験について論じているのか理解することができ、そこから実験方法やマテリアル、動物の種類、テストを行った脳の部位など重要な情報を取り出すことができるのだ。さらに可能な場合は図表を引っ張ってきて、後で検索やソートができるようにその内容まで読み込もうとする。
 また、Semantic Scholarは同じトピックについて書かれた他の論文の情報も参照するため、例えば、どの関連論文もしくは引用元の論文が分析対象の論文と関連性が高いかや、分析中の論文を参照してその後どのような研究が行われたか、といったインテリジェントな判断もできるようになっている。さらにはTwitterとも連携しているため、ユーザーは気になる論文の著者や部署・学部に直接メッセージを送ったり、その後の議論がどのように展開されていったか確認したりできる。
また、Semantic Scholarは同じトピックについて書かれた他の論文の情報も参照するため、例えば、どの関連論文もしくは引用元の論文が分析対象の論文と関連性が高いかや、分析中の論文を参照してその後どのような研究が行われたか、といったインテリジェントな判断もできるようになっている。さらにはTwitterとも連携しているため、ユーザーは気になる論文の著者や部署・学部に直接メッセージを送ったり、その後の議論がどのように展開されていったか確認したりできる。
検索スピードは早く、検索結果の関連度合いも高い上、簡単に検索結果をソート・深堀りすることもできる。このような論文を参照することの多い科学者にとって、Semantic Scholarの機能は大きなアドバンテージだ。実際に昨年ベータ版が公開されてから、すでに何百万回もこのサービスが利用されている。
 Semantic Scholarが一番最初に特化した分野は、コンピューターサイエンスだった。しかし、今後はバイオメディカルにも対応していくと本日発表され、最初のフォーカスは神経科学になるようだ。神経科学に関する情報が貯まったあとは、PubMedのバイオメディカルに関する論文全てを2017年中にSemantic Scholarに読み込ませる予定だ。もちろん有料で提供されている他のサービス上にもたくさんの論文が掲載されており、ElsevierやSpringerといった企業がそれを無料で開放するとは考えづらい。しかしそのような企業とも交渉にあたっているところだとSemantic Scholarは語っていた。
Semantic Scholarが一番最初に特化した分野は、コンピューターサイエンスだった。しかし、今後はバイオメディカルにも対応していくと本日発表され、最初のフォーカスは神経科学になるようだ。神経科学に関する情報が貯まったあとは、PubMedのバイオメディカルに関する論文全てを2017年中にSemantic Scholarに読み込ませる予定だ。もちろん有料で提供されている他のサービス上にもたくさんの論文が掲載されており、ElsevierやSpringerといった企業がそれを無料で開放するとは考えづらい。しかしそのような企業とも交渉にあたっているところだとSemantic Scholarは語っていた。
Semantic ScholarをつくったAllen Institute for Artificial Intelligence(AI2)は、数十人程度の小さな組織であると同時に、アメリカ最大の非営利AI研究機関でもある。彼らのモットーは、「公共の利益のためのAI」で、純粋かつ直接的に社会に貢献できるよう、AIテクノロジーを発展させることに注力している。
「医療界のブレイクスルーを、科学論文の検索のように面倒なプロセスのために遅らせるわけにはいきません。私が考えているSemantic Sholarのビジョンは、科学者がオンライン上にある何百万という数の論文を効率的にチェックし、爆発的に増え続ける情報にもついていけるような強力なツールをつくることです」とファウンダーのPaul Allenはプレスリリースの中で語った。
また、AI2のシアトルのオフィスを訪ね、CEOのOren Etzioniに話を聞いたところ、彼はSemantic Scholarが最終的に仮説生成エンジンになる可能性を秘めていると説明してくれた。彼の言う仮説生成エンジンとは、研究者の仕事を奪ってしまうほど高度なものではなく、むしろ大局的な「この手法は、感覚皮質では有効だけど、運動皮質では誰も試したことがないようだから、もしかしたらそっちを試してみた方がいいかもね」と意見を述べる教授のようなものを指している。
さらにEtzioniは、他の分野でもAI関連のプロジェクトを率いており、その多くでも自然言語処理技術が利用されている。例えばEuclidは、「3つの立方数の合計で最小の正の数は?」のように、普段私たちが使っている言葉で表現された数学の問題を理解することができる。また、別のプロジェクトでは、4年生の子供が日頃解いているような、読解問題から構成された標準テストを解くことを目標にソフトの開発が進められている。このようなプロジェクトは意外に難しいと同時に、チュータリングソフトやテストを自動で生成するソフトのように、便利なサービスにつながる可能性があり興味深い。
Semantic Scholarは誰でも試すことができるが、コンピューターサイエンスや神経科学の分野にいない人だと、検索結果はあまり役に立たないだろう。しかし、もしもあなたがそのような分野の研究をしているのであれば、Semantic Scholarを天から与えられたツールのように感じるかもしれない。
[原文へ]
(翻訳:Atsushi Yukutake/ Twitter)












