スマートフォンで検索を行っていると、サイト側の 設定ミス の結果として、欲しい情報が発見されないことがあります。しばしば見られるのは、デスクトップでは問題なく動作する一方、スマートフォンではエラー ページが表示されてしまったり、関係のないページへリダイレクトされてしまう、といったサイトです。Googlebot からはクロール エラーとして認識されるこれらの問題は、ユーザー体験上、大きな問題になる場合があり、以前このブログでもご案内した、スマートフォン向け検索結果における ランキングの変更 のきっかけでもあります。
本日より、ウェブマスター ツール内の クロール エラー 機能で、これらの問題を特定することができるようになりました。新たに設けられた「スマートフォン」タブには、スマートフォン向け Googlebot よって検出されたエラーが表示されています。
ここで表示されるエラーには、以下のようなものがあります。
- サーバー エラー: Googlebot があるページをクロールした際、HTTP エラー コード を返された場合に表示されます。
- ソフト 404: Googlebot が 404 を返された、あるいは返されたコンテンツが ソフト エラー ページ であると判断された場合に表示されます。
- 間違ったリダイレクト: デスクトップ向けのページが、スマートフォン ユーザーを検索クエリとは 無関係なページへとリダイレクト してしまう場合に表示されます。特に、スマートフォン向けサイトのトップ ページへのリダイレクトが多く見受けられます。
- ブロック: サイトの robots.txt が、スマートフォン向け Googlebot を ブロックしている際 に表示されます。通常、このようなスマートフォンに特化した振る舞いはエラーを招きます。サーバーの設定を再度ご確認ください。

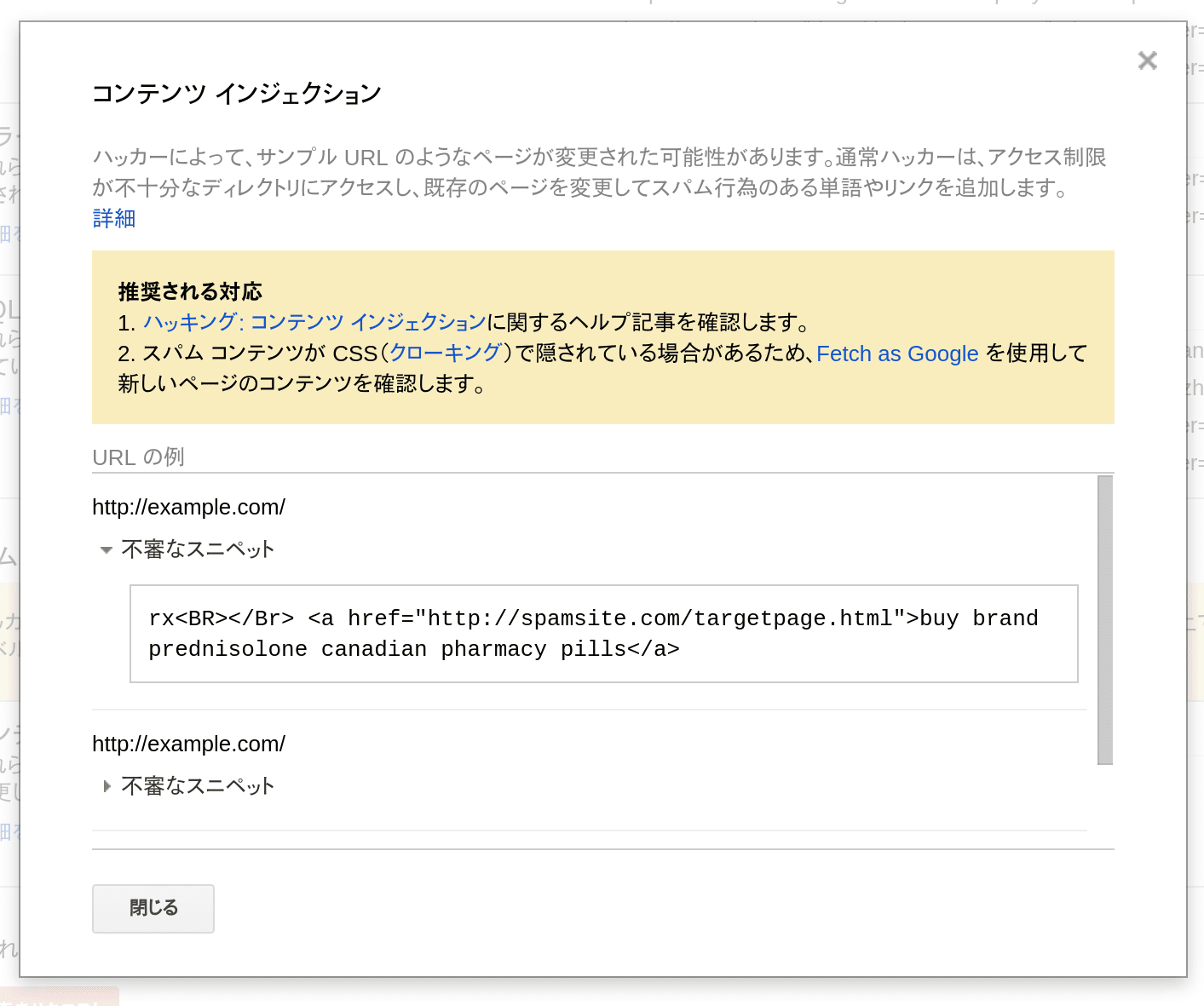






 にまとめました:
にまとめました:

 をクリックします。
をクリックします。