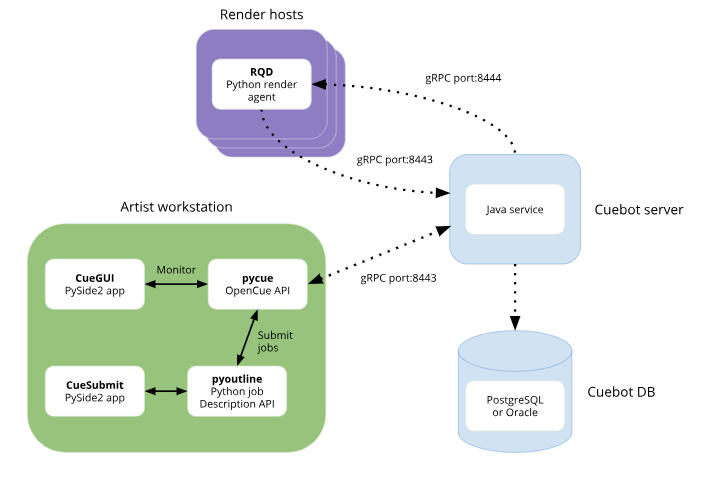
Googleが今日(米国時間1/24)、Sonyの視覚効果やアニメーションのスタジオSony Pictures Imageworksとの提携により、オープンソースのレンダーマネージャーOpenCueを発表した。OpenCueは実際のレンダリングをせず、そのさまざまなツールでレンダリング工程を各ステップに分解し、スケジューリングと管理を行なう。ローカルとクラウド両様の、大規模なレンダリングファームが使用するツールセットだ。
Googleはもちろん、そんなワークロードをクラウドに持ち込むことに関心があり、ハリウッドのスタジオに同社のCloud Platformを使わせる努力を続けてきた。たとえば昨年はそのためにロサンゼルスにクラウドのリージョンを立ち上げ、また2014年にはクラウド上のレンダラーZyncを買収した。さらに同社は、Academy Software Foundationの創立メンバーでもある。それは映画産業のためのツールに特化したオープンソースのファウンデーションだ。Sony Pictures Entertainment/Imageworksは創立メンバーではなかったが、創設から数か月後に参加した。
Cue 3は元々、Imageworksがおよそ15年前から社内で使っていたキューイングシステム(タスクの待ち行列の作成〜発進〜管理を行なうシステム)だ。Googleは同社と協働して、そのシステムをオープンソースにした。それは両社協働により、最大コア数15万にまでスケールアップした。
今日の発表声明でGoogleのプロダクトマネージャーTodd Privesはこう述べている: “コンテンツのプロダクションが全世界的かつ継続的に加速している中で、視覚効果のスタジオは高品質なコンテンツの需要に対応するためにますますクラウドに目を向けるようになっている。オンプレミスのレンダーファームは今でも重用されているが、クラウドが提供するスケーラビリティとセキュリティはスタジオに、今日のハイペースでグローバルなプロダクションスケジュールに対応できるための、必要なツールを与える”。
なお、Sonyがオープンソースに手を出すのはこれが初めてではない。同社はこれまでにも、OpenColorIOやAlembicなどのツールをオープンソースでコントリビュートしている。
画像クレジット: Sony Pictures Imageworks