テキストから音声への合成技術は近年大きく進歩し、最近のシステムは本物の人間がテキストを読んでるように聞こえるものが多い。その進歩を引っ張った企業のひとつであるGoogleは今日(米国時間3/27)、同社がAssistantやGoogle Mapsなどで今使っているのと同じ、DeepMindが開発したテキスト音声変換エンジンをデベロッパー向けに一般公開した。
そのCloud Text-to-Speechと呼ばれるサービスは、32種の声が12の言語とその変種を喋る。このサービスが生成するMP3またはWAVファイルは、ピッチや読む速度、音量などをデベロッパーがカスタマイズできる。
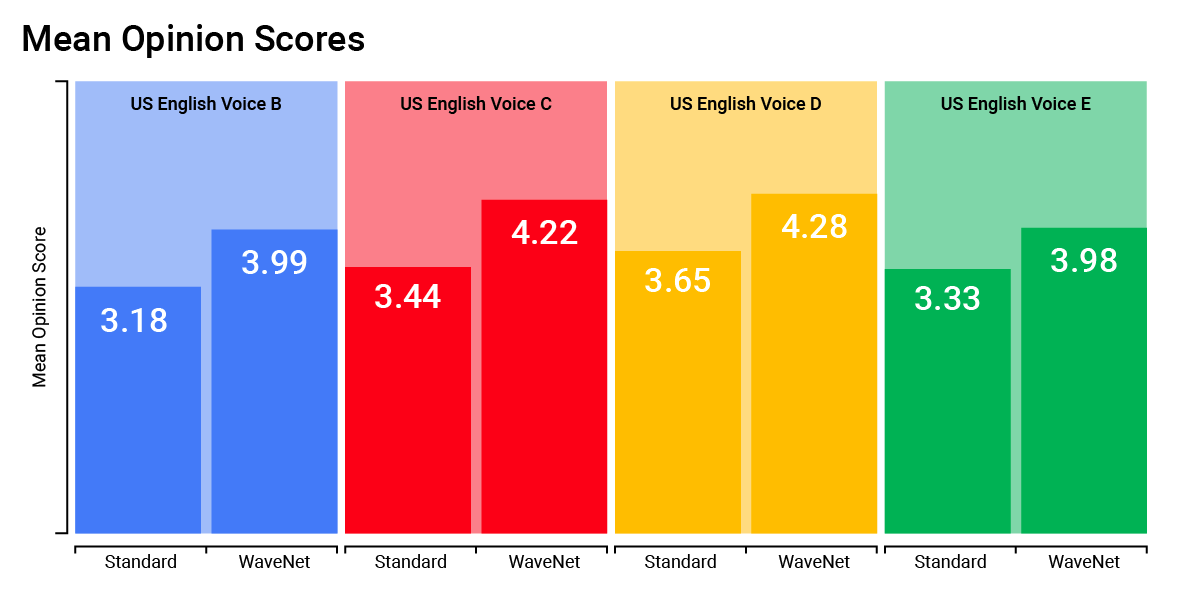
しかし、声の質にはむらがある。それはたとえば、英語には6種類の声があるからで、それらはすべて、テキストから生のオーディオを作るためのDeepMindのモデルWaveNetで作られている。
WaveNetはそれまでの技術と違って、短い発話の集まりから音声を合成しない。それをやると、私たちにはおなじみの、ロボットふうの話し方になってしまう。それに対してWaveNetは機械学習のモデルを使って生のオーディオのモデルを作り、より自然に聞こえる音声を合成する。Googleが行ったテストでは、WaveNetの声の方がふつうの(人間の)声よりも20%良い、という評価になった。
Googleが初めてWaveNetに言及したのは約1年前だが、その後同社は、同社自身のTensor Processing Unitsをベースとする新しいインフラストラクチャへこれらのツールを移し、オーディオ波形の生成をそれまでの1000倍速くした。だから今では1秒のオーディオの生成に50ミリ秒しかかからない。
この新しいサービスは、すべてのデベロッパーが利用できる。料金表はここにある。