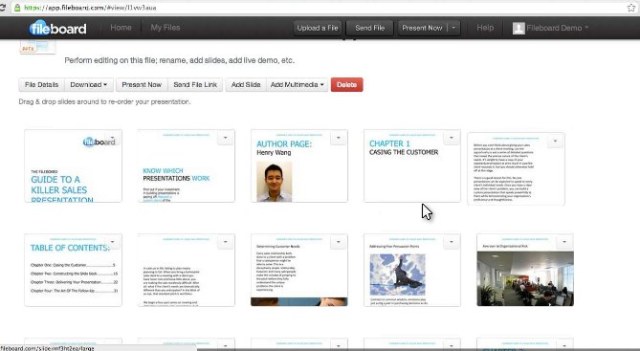
Node.jsのサポートを提供しているクラウドプロバイダはAWSだけではない。Joyentはこのプラットホームを企業向けサービスの一環として提供している。Windows Azureもビッグなサポーターだ。Rackspaceもサポートしている。3月にMicrosoftは、Windows Azure Service Busを使うオープンソースの寄与貢献物を提供した。それは、Node.jsによるリアルタイムアプリケーションのためのスケールアウトをサポートするライブラリだ。
しかしアプリケーションのパフォーマンスやデータ分析のスピードを左右する要素は、非常に多面的だ。最近FirstMark Capitalの常勤パートナーになったMatt Turckは、先週ニューヨークの同社のオフィスで行ったインタビューで、物のインターネット(Internet of Things, IoT)がデータ転送の総量を爆発的に増大させる、と言った。彼はそのとき、その兆候としてMQTTの登場を挙げた。この、IoTのための通信プロトコルは、The New York Timesによると、“マシンツーマシン通信のための共通語であるだけでなく、データ交換のためのメッセンジャーでありキャリアだ”。
Engima は、先週行われたDisrupt NY 2013で優勝した。協同ファウンダのHicham Oudghiriによると、スピードのニーズの背後には必ず、データ量の絶えざる増大というニーズがある。しかし彼によると、EnigmaやPalantirなどが抱えるスケールの問題は、多くのスタートアップが日々直面している問題とまったく異なる。
Windows Azureのブログによると、これまでもっともリクエストの多かった機能が、バージョンコントロールシステムのサポートだ:
TFS(Team Foundation Server)とVisual StudioがGitをサポートしたことの発表に続き、さらにWebMatrix 3がGitとTFSの両方をサポートする。これらによるソースコントロール体験はエクステンションとして提供される。弊社は複数のパートナーとの協働により、CodePlexとGitHubの充実したサポートを提供する。
Windows Azureのブログはさらに、Gitの利用はユーザの緊急リポジトリと構成と既存のツールもカバーする、と述べている。コミット、ブランチ、マルチプルリモート、そしてWebサイトのWindows Azureへのパブリッシュもサポートされる。
Amazon Web Servicesの複雑さを克服することが、一つのビジネスになりつつある。その新人選手CloudCheckrは、AWSに欠けているリソース分析/費用分析/セキュリティ分析のためのツールを提供し、最近200万ドルの資金を調達するとともに、そのフリーミアムサービスの一般公開にこぎ着けた。200万ドルのシリーズAを仕切ったのはGarrison Capital、そこにGenesee Capitalが参加した。
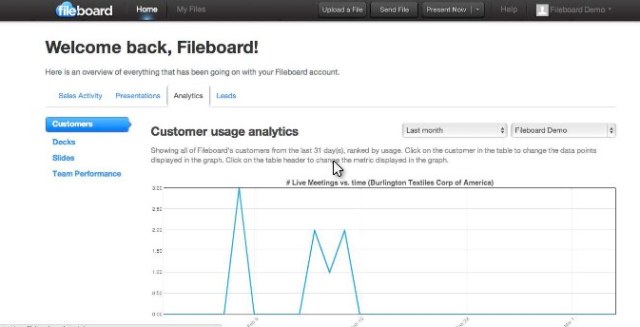
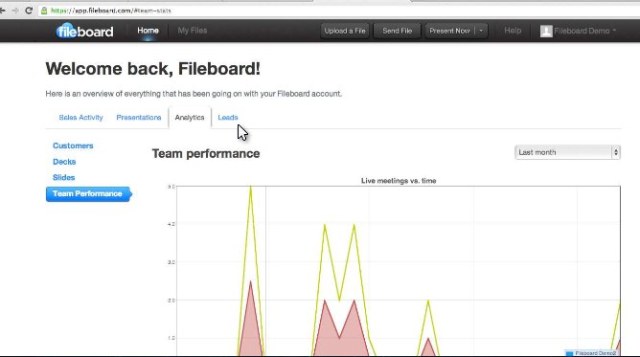
Get Satisfactionのオペレーション担当VP Jonathan Clayによると、CloudCheckrはAWSの利用状況を総合的に見るためのポータルのようなサービスで、リソースの使われ方やその費用などを報告してくれる。また、インスタンスの混み具合や空き具合を見て、最適容量のリコメンデーションもする。予備インスタンス(reserved instances)の確保量に関するリコメンデーションも提供する。総じて、このサービスを利用すると企業は、費用やリソース利用の無駄をチェックでき、またセキュリティのためのベストプラクティスの遵守状態も知ることができる。
Amazon Web Servicesの複雑さを克服することが、一つのビジネスになりつつある。その新人選手CloudCheckrは、AWSに欠けているリソース分析/費用分析/セキュリティ分析のためのツールを提供し、最近200万ドルの資金を調達するとともに、そのフリーミアムサービスの一般公開にこぎ着けた。200万ドルのシリーズAを仕切ったのはGarrison Capital、そこにGenesee Capitalが参加した。
Get Satisfactionのオペレーション担当VP Jonathan Clayによると、CloudCheckrはAWSの利用状況を総合的に見るためのポータルのようなサービスで、リソースの使われ方やその費用などを報告してくれる。また、インスタンスの混み具合や空き具合を見て、最適容量のリコメンデーションもする。予備インスタンス(reserved instances)の確保量に関するリコメンデーションも提供する。総じて、このサービスを利用すると企業は、費用やリソース利用の無駄をチェックでき、またセキュリティのためのベストプラクティスの遵守状態も知ることができる。
しかしDrawn to Scaleの協同ファウンダBradford Stephensは、“RedshiftはデータウェアハウスだからVerticaやGreenplum、AsterData、Impala、Hadapt、CitusDataなどと比較すべきだ”、と言っている。“Hadoopとは全然違うものだ”、と。
スタートアップたちの売上や利益は大企業に比べると微々たるものだが、しかしときにはHapyrusのような企業が出現して、Amazon Web Servicesの新しい使い方によって、独自の顧客ベースを堅実に築いていく。ビジネスの一件々々の額は小さくても、その技術力はユニークで高い。
今後作成するDBインスタンス(MySQLまたはOracle)は、ストレージの最大量が3TB(これまでは1TBまで)で、最大30000IOPS(これまでは10000)となる。SQL Serverを使うDBインスタンスは、最大ストレージが1TB 7000IOPSとなる。m2.4xlargeの上のリード/ライト各50%のワークロードに対しては、Oracleで最大25000IOPS、MySQLで12500IOPSとなる。しかしながら30000IOPSの配備では、レイテンシの低下とスループットの向上が可能となる。実際のIOPSは、データベースのワークロード、インスタンスタイプ、使用するデータベースエンジンの違いに応じ、何を配備したかによって異なる。詳細については、Amazon RDS User GuideのFactors That Affect Realized IOPSを見ていただきたい。
今ではAWSだけでなく、GoogleもRackspaceもFacebookも、日用品的なハードウェアを使っている*。安いし、ソフトウェアを動かしやすいからだ。ソフトウェアを作るのはデベロッパだ。そしてデベロッパが作っているのは、労働者たちが自分のGalaxyスマートフォンやiPadから使うアプリケーションだ。今では、ハードウェアをオープンソース化しようとする動きすらあり、OpenComputeような団体が関心を集めている。だからハードウェアは今後ますます安くなり、そしてイノベーションを加速する。今や、ハードウェアのハッカソンが行われる時代だ。〔*: 日用品的なハードウェア, Sun SPARKのような高価なサーバ専用機でなく、一般市販のx86機のこと。〕