
元Googleの役員たちが作ったAIと機械学習のスタートアップであるRealityEngines.AIが米国時間1月28日、ステルスを脱して最初の製品を発表した。
同社が2019年に525万ドル(約5億7300万円)のシードラウンドを発表したとき、CEOのBindu Reddy(ビンドゥ・レディ)氏はミッションについて、機械学習を企業にとってやさしくすると言うだけで、詳しい話は何もなかった。しかし今日チームは、エンタープライズにおけるMLの標準的なユースケースに伴う問題を解決する一連のツールをローンチして、サービスの具体的な内容を明らかにした。それらの問題とは、ユーザーチャーン(中途解約)の予測、不正の検出、営業の見込み客予測、セキュリティの脅威の検出、クラウド支出の最適化などだ。これらにあてはまらない問題には、もっと一般的な予測モデルサービスが提供される。
RealiyEnginesの前は、レディ氏はGoogleでGoogle Appsのプロダクトのトップを、AWSでは業種別AIのゼネラルマネージャーを務めた。共同創業者のArvind Sundararajan(アービンド・スンダララジャン)氏はかつてGoogleとUberに在籍し、Siddartha Naidu(シッダールタ・ナイドゥ)氏はGoogleでBigQueryを作った。同社の投資家は元Google会長Eric Schmidt(エリック・シュミット)氏、Ram Shriram(ラム・シュリラム)氏、Khosla Ventures、そしてPaul Buchheit氏(ポール・ブッフハイト)だ。
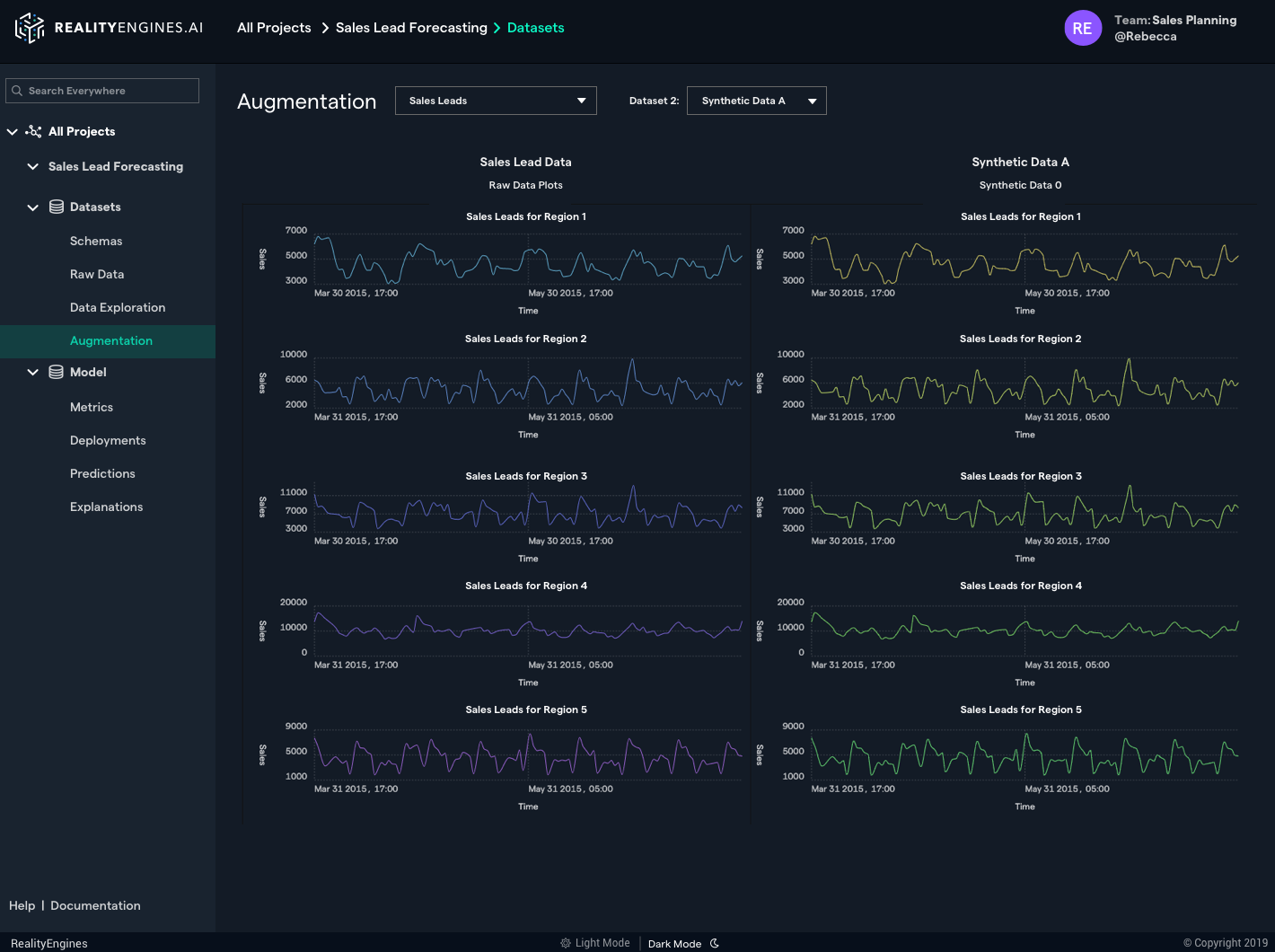
レディ氏によると、これら一連の製品を支える基本的な考え方は、企業に機械学習への容易なエントリーを提供することだ。企業自体にデータサイエンティストがいなくてもよい。
人材以外の企業にとっての問題は、ネットワークを有効に訓練するために必要な大量のデータが、往々にして存在しないことだ。AIを試してみたいという企業は多くても、この問題が前途に転がっている巨大な落石のような障害になっていた。RealityEnginesはこの問題を、本物そっくりの合成データを作ることによって解決。それで企業の既存のデータを補うことができる。その合成データがある場合は、ない場合に比べてモデルの精度が15%以上アップするそうだ。
レディ氏は次のように主張する。「敵対的生成ネットワーク(Generative Adversarial Networks、GANS)の最も強力な使い方は、ディープフェイクを作ることだった。ディープフェイクは、部分的に手を加えたビデオや画像で誤った情報を広めることが極めて容易であることを世間に知らしめたから、大衆の心にも訴えた。しかしGANSは、生産的な善用もできる。たとえば合成データセットを作って元のデータと合わせれば、企業に大量の訓練用データがなくても、堅牢なAIモデルを作れる」。
RealityEnginesの現在の社員は約20名で、その多くはML/AI専門の研究者または技術者だ。









{kind=link}