Googleが今日、同社のモバイルとWebとIoT用のサーバーレスNoSQLドキュメントデータベースCloud Firestoreの一般供用を発表した。Googleはまた、10の新しいリージョンに、いくつかの新しい機能を導入してこのサービスを提供しようとしている。
今回のローンチでGoogleはデベロッパーに、データベースを単一のリージョンで動かすオプションを与える。ベータの間はデベロッパーはマルチリージョンのインスタンスを使っていたが、それはレジリエンスの点では有利でも、料金が高くなり、また複数のリージョンを必要としないアプリケーションも少なからずある。
GoogleのプロダクトマネージャーDan McGrathはこう語る: “マルチリージョンによって可能になる信頼性や耐久性を、必要としないユーザーもいる。そういう人たちにとっては、費用効率の良い単一リージョンのインスタンスが好ましい。またCloud Firestoreデータベースに関しては、データをユーザーのなるべく近くに置ける‘データのローカル性’が確保される”。
新しい単一リージョンのインスタンスは、料金が現在のマルチクラウドインスタンスよりも最大で50%安くなる。ただしGoogleがユーザーに与えるSLAの保証は、使用するソリューションによって異なる。単一リージョンのインスタンスもそのリージョン内で複数のゾーンへ複製されるが、データはすべて一定の地理的領域内にとどまる。したがってGoogleは、マルチリージョンのインスタンスには99.999%の可用性を約束し、リージョン限定のインスタンスには99.99%の可用性を約束している。
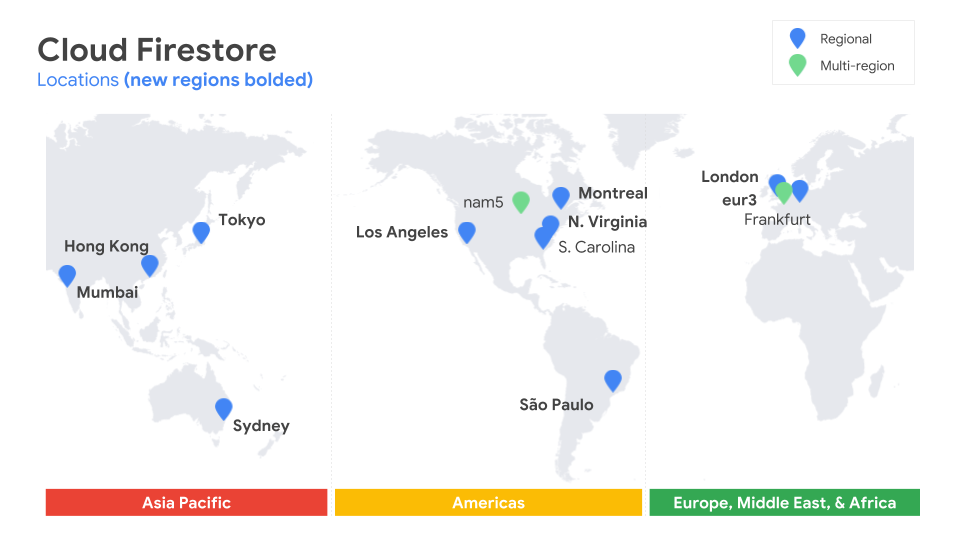
そしてCloud Firestoreは、全世界で10の新しいリージョンで利用できる。Firestoreはローンチ時には一箇所でローンチしたが、ベータのときはさらに二つ増えた。そして今では、Firestoreは13の場所で利用できる(そのうち、North AmericaとEuropeはマルチリージョンだ)。McGrathによると、Googleは現在、今後の配置について検討中だが、現状でも十分に全世界をカバーできる、という。
また今回のリリースで、Google CloudのモニタリングサービスStackdriverとより深く統合され、リード、ライト、デリートをリアルタイムに近い素早さでモニタできる。McGrathによると、今後の計画では複数のコレクションにまたがってドキュメントをクエリできるようになり、また、データベースの値の加増(インクリメント)をトランザクション不要でできるようになる。
なお、Cloud FirestoreはモバイルのデベロッパーにフォーカスしたGoogle Firebaseブランドに属するが、Firestore自身はCompute EngineやKubernetes Engineのアプリケーション用の、通常のクライアントサイドライブラリをすべて提供する。
McGrathは曰く、“従来のNoSQLドキュメントデータベース製品は、管理に関するデベロッパーの負担が大きい。しかしCloud Firestoreなら、データベースの管理はいっさい不要だ。しかもFirebase SDKと一緒に使えば総合的なBaaS(back-end as a service)にもなり、認証なども扱えるようになる”。
Firestoreのアドバンテージのひとつが、オフラインサポートが充実していることだ。それはモバイルのデベロッパーにとって便利だが、IoTにも向いている。Googleがこれを、Google CloudとFirebaseの両方のユーザーのツールと位置づけているのも、当然だ。