
イスラエルのLumigoが今日(米国時間1/22)、800万ドルという大きなシードラウンドを発表し、ステルスを脱して企業によるサーバーレスアーキテクチャのモニタリングを助けていくことになった。投資家はPitango Venture Capital、Grove Ventures、そしてMeron Capitalである。
同社は、Checkpointの役員だったErez BerknerとAviad Morが創業した。彼らは、デベロッパーたちがサーバーレス環境への移行に際して、とくにモニタリングの部分で経験している問題を、自分たちのスタートアップで解決してやろう、と決意した。
サーバーレスコンピューティングではデベロッパーが、下層のインフラストラクチャのことを気にせずにコードを書ける。AWS LambdaやAzure Function、Google Cloud Functionなどのサービスは、アプリケーションをいかなるときでも動かせるだけの十分なインフラストラクチャを提供している。それはデベロッパーにとって、迅速な開発のできる、きわめて便利な仕組みだが、そのアプリケーションを管理しモニタしようとするオペレーションのチームにとっては難題が降りかかる。
そこで、そんなOpsたちを助けるために、Lumigoはビジュアルなマップ(下図)を使って、アプリケーションの中で起きていることをオペレーションの連中に見せる。オペレーションのチームはそのマップの上で、すべてのリクエストを見て理解し、問題の原因を突き止める。トレースはサーバーレスのインフラストラクチャからだけではなく、データベースやストレージなど関連のサービスからも行なう。
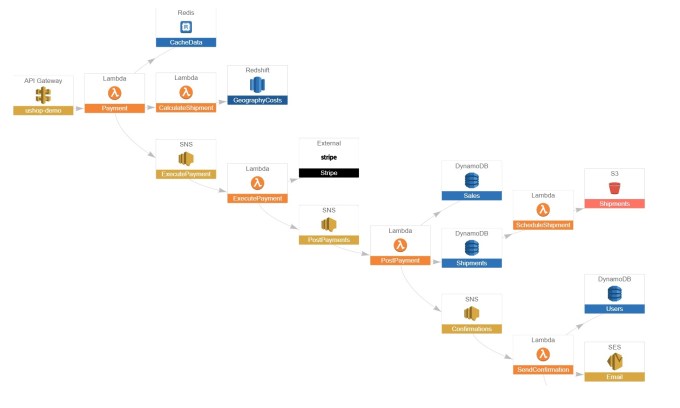
Lumigoのサーバーレスモニタリングマップ
同社がサポートしているのは今のところAWSだけだが、今後はそのほかのクラウドプラットホームもサポートする予定だ。またモニタリングの対象を、サーバーレス以外にも広げたい。今計画しているのは、コンテナと、TwilioやStripeのようなAPIサービスのモニタリングだ。
同社はまだ、きわめて初期の段階だが、すでに社員は8名、顧客は10数社いる。今回得た資金でエンジニアを増員し、製品開発により力を入れたい、と考えている。





{kind=link}
{kind=link}
{kind=link}