
昨日(米国時間9月1日)、パロアルトにある法律事務所の広大な駐車場は、沢山のTeslaで埋められていた。天井の高い会議室には100人のトップ投資家たちが集まった。ここで彼らは、13のスタートアップが、自分たちに注目すべき理由を述べる各4分間のプレゼンテーションに耳を傾けた。
登壇したスタートアップは、みなおよそ起業半年以内のものばかりで、すべて現役の学生または最近の卒業生が率いている。いずれも創設3年のPearによるLaunchpadプログラムのメンバーなのである。Pearは初期ステージベンチャーファームであり、毎年トップ校に通う、会社を作りたいコンピューターサイエンスの学生を募集して、オフィスと同時に、使用目的に制限も義務もない5万ドルを提供している(最近まで、同社Pejman Mar Venturesとして知られていた)。
これまでのところ、Pearはこれらの学生チームを賢く選んできたようだ。1年前にプレゼンテーションを行った8つのグループのうち1つのスタートアップはGoogleに買われ、他に4つがシード資金調達に成功している。Pearが開始された2014年の最初のクラスからも、スタートアップのFancyThatがPalantirに買われている 。
明らかに、昨日集まったベンチャーキャピタリストたちは、熱狂的なようだった。Canaan PartnersのパートナーであるRoss Fubiniはプレゼンテーションの途中で「今年一番のデモイベントに思える」とツイートしている。別の投資家、Lux CapitalのパートナーShahin Farshchiは、イベント後私たちに語った「素晴らしかったね、全ての人に対して何かしらの意味で。消費者向けの会社、分析とAIの会社、そして私のような投資家のためのディープテクノロジーも」。
そこに参加しておらず、おそらく好奇心旺盛な読者のために、以下にその内容を紹介しよう:
Allocate.ai:この会社は、AI搭載のタイムシートを作成している。これは作業チームがどこにどのように時間を使うべきかをより良く理解する手伝いをするプロダクトだ。(スタンフォード大学とカリフォルニア大学サンタバーバラ校出身の)創業者たちによると、米国では4500万人がタイムシートに記入していて、これによる時間的損失は金額にして110億ドルに達するとの推定である(その時間に価値がありながら、1日15分以上を請求に必要な情報収集に使っている弁護士のことを想像してみると良い)。彼らはそれをより効率化し、市場をさらに大きなものにすることができると主張している。もしあなたが同意し、彼らに連絡をとりたい場合は、founders@allocate.aiまで。
BlackSMS :この技術を使ってユーザーは、暗号化されパスワードで保護され、自己消去を行うiMessagesを送信することができる。メッセージは偽の代替テキストの内に隠したり保護したりすることができる。これは様々なケースで有効だろうと私たちを感心させた。これについて私たちが正しいことを願おう。その20歳の創設者、Tyler Weitzman – 中学時代から30あまりのアプリを構築してきたと言う – は、「BlackSMSにすべてを賭ける」ためにスタンフォード大学を中退した。
詳しく知りたければ、TCが今年の前半に書いたより長い記事を、ここで読むことができる。Weitzmanに連絡するには、founders@black-sms.comに電子メールを送れば良い。
Capella Space:このデータ会社は、靴箱サイズの衛星群を介して宇宙から持続的かつ信頼性の高い情報を提供することができると言っている。他のスタートアップの衛星とはどのように異なるのだろうか?その技術は合成開口レーダー(SAR)を使っている。これが意味することは、雲を通り抜ける電波の反射を使い太陽光の反射を必要としないため、夜や厚い雲に覆われているときでも、地球の表面に向けて電波を送り画像を得ることができるということだ。(他の多くの衛星群はその代わりに、光学技術に依存している)。
Capellaには競合他社がいて、Ursa Space Systemsもその1つである。 Ursaは現在、旧来の(つまり大きくて嵩張る)衛星に搭載された合成開口レーダーを使って得た情報を顧客に売っていて、そして独自の衛星群を開発することを計画している。しかし、現時点では勝負の行方はまだ見えていない。founders@cappellaspace.comで創業者に連絡することができる。

DeepLIFT Technologies:この会社は、入力を観察し繰り返されるパターンや他のものを識別することによって、任意のディープラーニングプロセスを理解し説明することができると言う、一連のアルゴリズムを開発した。
なぜ彼らのように、機械学習が上手くいく理由をわざわざ掘り下げるのだろう?1つの理由は、規制当局が「ブラックボックス」技術に対する押し戻しを始めているからである。最も顕著なのは、最近EUが機械学習モデルが、EU市民に影響を与える判断に利用される場合、その内容について「説明を受ける権利」を保証する法案を制定させる条項を導入したことだ。
創設者は、同社は資金を調達していないと言っている(私たちがこれを信じるかどうかは別として)。彼らはまた、現在彼らの技術は全米8箇所のゲノム研究室で使用中で、既にGoogleのモバイル開発チームとAlphabetのライフサイエンスの子会社であるVerilyを含んだ形で、Alphabet社からの強い関心が寄せられていると語った。彼らへの連絡先はfounders@deeplift.aiである。
Hotline:このスタートアップは、ファンが直接有名人とつながることができる、メッセージングベースのプラットフォームを提供する。今のところ、それはFacebookのメッセンジャー、SMS、およびKikを使って単一のスレッドを介した通信を可能にする。基本的なアイデアは、メッセージングにTwitterのような対話性をもたらすことである。例えば、ランナーのウサイン・ボルトのファンは、おそらくボルトと1分でつながり、すぐにスイマーであるマイケル・フェルプスと、プラットフォームを変えたり他のダイアログボックスを開いたりせずにやりとりをすることが可能になる。
ハーバード大学、アマゾン、マッキンゼー – 創設者たちは印象的な経歴を持っているが、正直このプロダクトにはそのような雰囲気は漂っていない。大切なことかどうかは分からないが、早期のSnapchatのことを思わせることはなかった。彼らへの連絡先はfounders@hellohotline.comである。
Kofa:このスタートアップの技術は、あらゆる場所でアナリストを「スーパーチャージ」する。売り文句はこうだ:アナリストたちは予測モデリングや地理空間分析と膨大なその他の材料を理解しようとして苦労しているが、それは企業における彼らの役割の中心ではない。Kofaは、彼らにこの問題の一部を解決するための再利用可能なポイントアンドクリックのツールを与えると言う。その技術はまた、アナリストが互いの仕事の上に、別の仕事を構築することを可能にする。
私たちは、これがどの程度ユニークなのかはわからないが、Kofaの創設者は以前FancyThatを設立した者たちだ。彼らはPalantirに在籍していたが(前述したようにPalantirはFancyThatを買収した)、今年の初めに同社を離れ再び自分たち自身で起業した。これまでのところは上手くやっているようだ。彼らは既にいくつかのプリシード資金を調達していて、読者がこの記事を読む時には顧客と「6桁の契約を締結しつつある」ということだ。

Motif:このスタートアップが目指しているのは、カスタマーサービス担当者が、簡単かつ即座に助けを求めているユーザーの画面を引き継ぐことである。これらすべてが1行のJavaScriptで実現されている。Motifはまた、事前に定義されたユーザーアクションの前後5分間のユーザーの画面を、サポート企業が記録することができるようにする。もし最初に心に浮かんだことが「プライバシーはどうなる?」ならば、目を閉じて、最後に画面上にあるものについて、電話越しにだれかに説明しようとしたとき、それがどれくらい時間がかかったかを思い出してみよう。Motifが、今後このような苦悩から私たちを救うことができるなら、私たちはそれを受け容れる。
チームの大きさがどれほどかは明らかではない。創業者Allan Jiangは現在スタンフォード大学でコンピュータサイエンスを学んでいて、2018年に卒業予定であることは確かである。彼への連絡はfounders@usermotif.comへ。
Nova:この会社は移民が米国の会社からのローンにアクセスすることを助けようとしている。米国の貸金業者には移民のクレジット履歴に簡単にアクセスする手段がないため、通常移民からのローンの申し込みは不可能ではないにせよ、とても困難である可能性が高い。ではNovaのソリューションは?世界中のグローバルな信用調査会社と貸し手を接続することだ。移民はNovaと提携している金融機関に融資を申請し、貸し手はAPIを経由して得られる情報を使って意思決定を行う。なおAPIで取得されるファイル1件ごとに貸し手はNovaに30ドルを支払う。これで完了だ。
同社は、2ヶ月前に開業し、既に3金融機関と提携している。創業者たち(全員がスタンフォード)に連絡する際にはfounders@neednova.comへ。
Pluto:このスタートアップは、小売業者が顧客を獲得するための新しいチャネルとして、メッセージングアプリを活用することを助ける、SaaSプラットフォームを提供する。例えばトリーバーチのようなブランドは、もはやメールプロモーションや広告だけに頼るというわけにはいかない。Plutoの技術を用いれば、顧客がFacebookメッセンジャーを開けた際に、後で買うためにオンラインショッピングカートに保存してまだ買っていないカラープロックPコートについて、企業から顧客にリマインダーを送ることができる。いままで行われてこなかったことだ。
創業者への連絡はfounders@getpluto.coまで。
Script:写真を撮り、それをオンラインステッカーに変換し、メッセージングアプリを離れることなく送る。または友人や他のコミュニティのステッカー作品にアクセスして、会話を離れることなく、彼らのステッカーを送信する。
Hotlineと同様に、私たちにとってこの会社は、会社としては物足りなく、単なる機能提供のためには過剰のような気がするのだが、しかし機能も増え多くの人びとがこれを「選んで」いるようである。Scriptの創業者チーム(全員がスタンフォードから)によれば、過去4ヶ月間でサービスを知った何千人ものユーザーが、既に320万ステッカーを作成したそうである。役立つ情報かどうかは不明だが、CEOのKatia Ameriは同社を開始する前に、Pearのベンチャーアソシエイトとして2年間を過ごしている。
Ameriと彼女の共同創業者たちへの連絡はfounders@script.meへ。
Synocate:このスタートアップは、大学入学やキャリアアドバイスのための市場を構築中である。まず手始めに入試小論文を提出しようとする高校生のためのエッセイ編集ツールの提供を開始し、1エッセイにつき49ドルで、彼らが入学しようとしている大学の学生からのフィードバックを行っている。
特に目新しいものを聞くことはできなかった:野心的な高校生とその親の要望に応えようとする沢山のスタートアップが既に存在している。そして、それはとても巨大な市場であり、圧倒的に成功しているものは存在していない。創業者への連絡はfounders@synocate.comへ。
xSeer:カーネギーメロンその他のPh.Dのチームによって設立されたこの会社は、数10億のデータポイントを取り込み、直感的に大規模なスケールで可視化を行う洗練されたビジュアル分析ソフトウェアを作成している。例えば保険会社などの顧客企業が、現在ターゲットにしておらず、本来ならばターゲットにするべき人たちを発見することなどを容易にする。
もしもっと詳しい情報のために創業者たちに連絡をしたい場合(彼らはまた秀逸なデモプログラムも持っている)はfounders@xseer.ioへ。
Viz:私たちにとっては、この会社が1番興味深いものに思えた(Farshchiも同意見だ)。一言で言えば、それは一般的には放射線科医や他の技術者の専門知識を必要とする、超音波診断に対するディープラーニングの適用である。不安な患者たちが長い間待ち望んでいたものになる可能性がある。具体的には、そのソフトウェアは、超音波診断画像を他の数百万の画像や動画(ひとりの放射線科医師が一生に見ることのできる以上の数だ)と比較することによって、担当医師が画像を解釈する能力を上げ、迅速な対応がとれるようにする。
これは「熱い」領域だ。数年前、起業家Jonathan Rothbergは、Technology Review誌のインタビューで、新しい種類の超音波画像診断システムの開発に対して1億ドルを投資したと語った。その新しいシステムは「聴診器程度に安価」で「医者の効率を100倍にする」ものだということだった。最初は腰部の診断に焦点を当てているVizは、そのソフトウェアを使って、既存の機械で同じ仕事ができるようにすることを目指している。
創業者たちへの連絡はfounders@viz.aiへメールを送ること。
[ 原文へ ]
(翻訳:Sako)













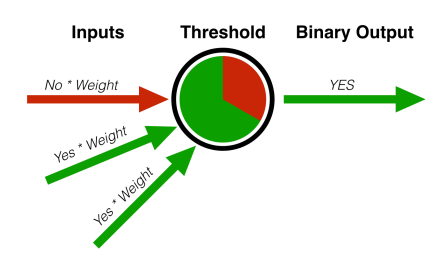
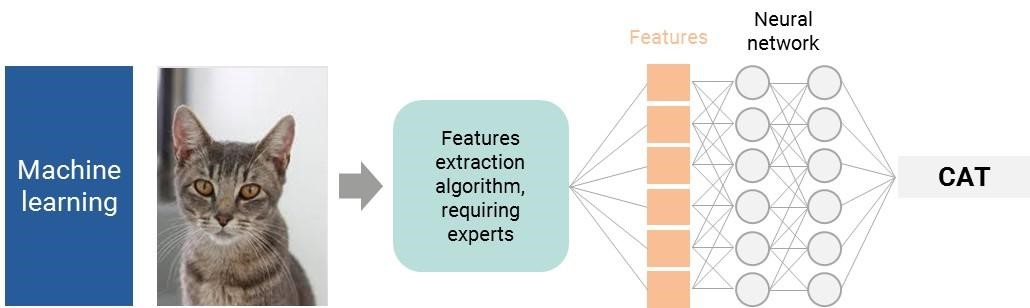
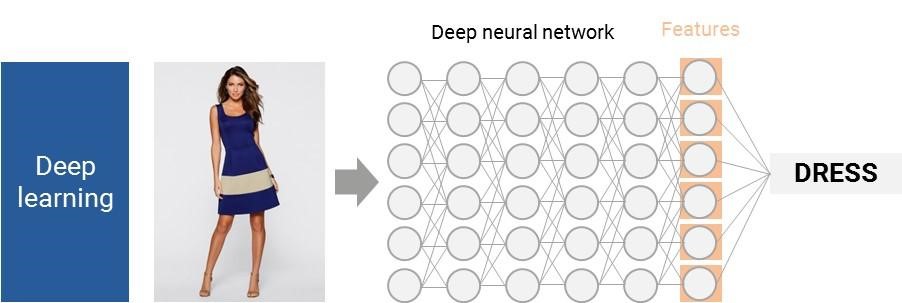
 パーセプトロンは、機械学習の分野で行われた多くの初期の進歩の、ほんの1例に過ぎない。ニューラルネットワークは、協力して働くパーセプトロンの大きな集まりのようなものである。私たちの脳や神経の働き方により似通っていて、それが名前の由来にもなっている。
パーセプトロンは、機械学習の分野で行われた多くの初期の進歩の、ほんの1例に過ぎない。ニューラルネットワークは、協力して働くパーセプトロンの大きな集まりのようなものである。私たちの脳や神経の働き方により似通っていて、それが名前の由来にもなっている。


 2012年設立の日本のスタートアップ企業、
2012年設立の日本のスタートアップ企業、
