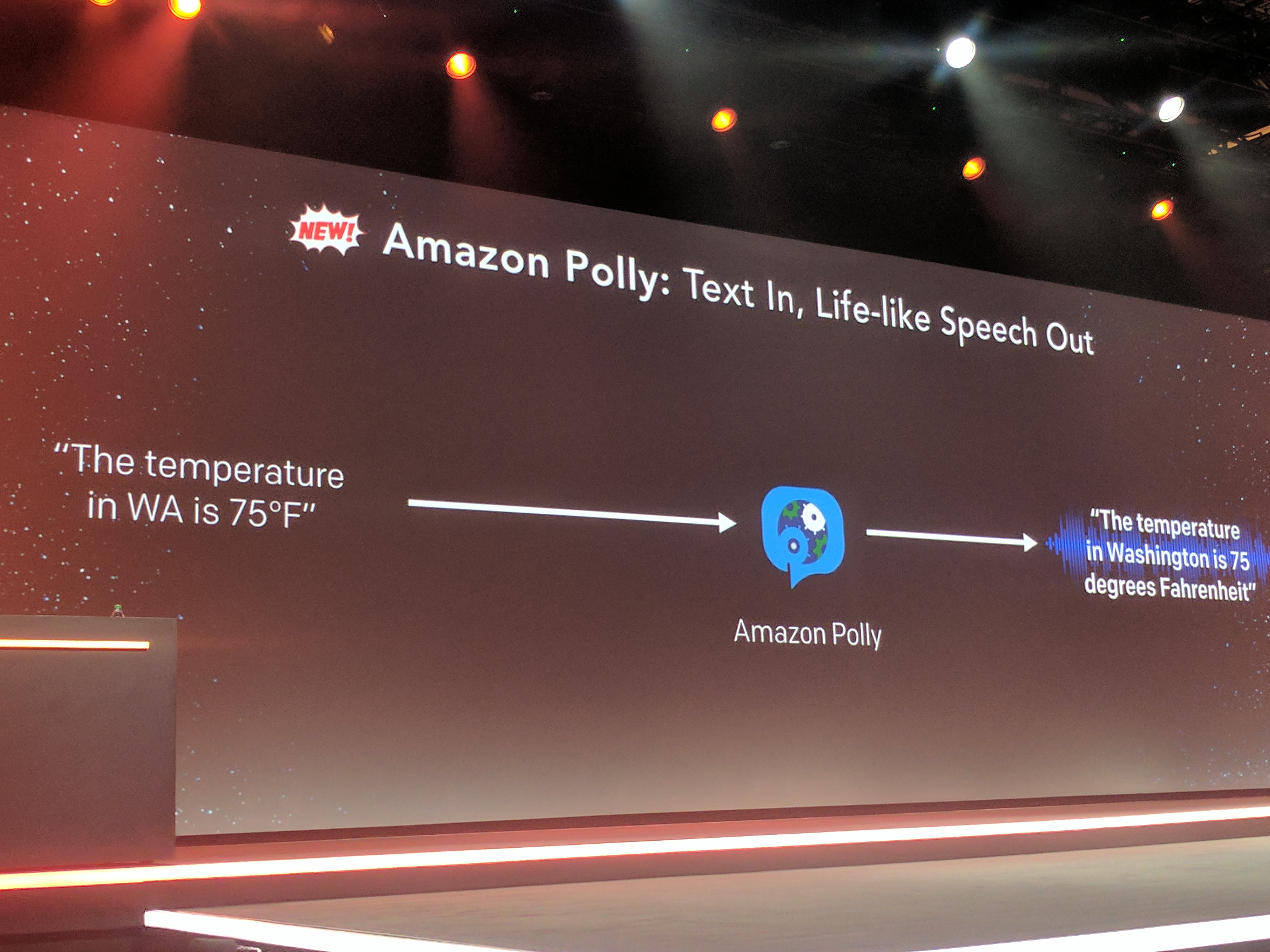
2つ目は Amazon Pollyで、これはテキストを音声に変換するサービスだ。裏では機械学習の知性を多く活用しているという。人が話しているかのような音声が作成できるとJassyは話す。「Pollyは、音声生成でこれまで課題だった部分を解決します。例えば、『live』の言葉の発音は文章によって異なります。『I live(リブ) in Seattle』と『Live(ライブ) from New York』のようにです。Pollyは同形異義語を認識して、スペルが同じでも発音が違うことを知っています」。
“Alexa, ask the fact-checkers did Donald Trump oppose the war in Iraq?”(Alexa、事実確認をお願い。ドナルド・トランプはイラク戦争に反対したの?)
“Alexa, ask the fact-checkers was Hillary Clinton right that her email practices were allowed?”(Alexa、事実確認をお願い。ヒラリー・クリントンが主張した、電子メールの使い方は許可されていたという事実は正しかったの?)
“Alexa, ask the fact-checkers is it true that 300,000 Floridians have lost their health insurance because of Obamacare?”(Alexa、事実確認をお願い。30万人ものフロリダの住民がオバマケアのせいで健康保険を失ったというのは本当なの?)
このShare the Factsプロジェクトからスピンオフしたスキルは、自然音声認識を利用して質問を分析し、プロによって選別を受けた約2000のチェックデータベースから答を引き出してくる。その結果は、タイムリーで、かつパートナーの事実確認サービスの間でもっとも高い同意が得らているものとなるように、調整されている。
ロンドンに拠点を置くShazam Entertainment Ltd.は、ついにようやく黒字に転じたことも発表した。これはデジタル形式での音楽売上に対するコミッションと音楽ストリーミングサイトへのトラフィック誘導による収入に加えて、新たに注力していた広告収入の成果とみられる。
ShazamのCEOがWall Street Journalに語ったところでは、同社は現在もSpotify、Apple Musicなどのストリーミングサービスに毎日100万クリックを誘導し、トラフィックおよび購入があった場合のコンバージョン報酬を受け取っているという。しかし今では広告収入が他の収入源を上回っているとの話だ。
ゆっくりと、しかし着実に、Amazonは音声認識AIソフトウェア「Alexa」の機能を、数ある自社製ハードウェア製品に組み入れつつある。数週間前、Amazonはこの音声アシスタント機能を米国で提供中のTVストリーミング向けハードウェアソリューションに導入すると発表した。ここでいうハードウェアには上位機種のFire TVから、より小型でドングルベースのFire TV Stickなどが含まれる。
Fire TV Stickの新たに発表されたバージョンでは音声認識機能が組み込まれ、「Fire TV Stick with Alexa Voice Remote」という、さらに長くなった新名称での発売となる。このちょっと呼びづらい新バージョンの販売価格は前バージョンから据え置きの40ドルで、音声認識対応のリモコン(以前は単体で30ドルした)が付属している。リモコンからは音声コマンドでアプリの起動、プログラム検索、チャンネル選択などを操作できる。