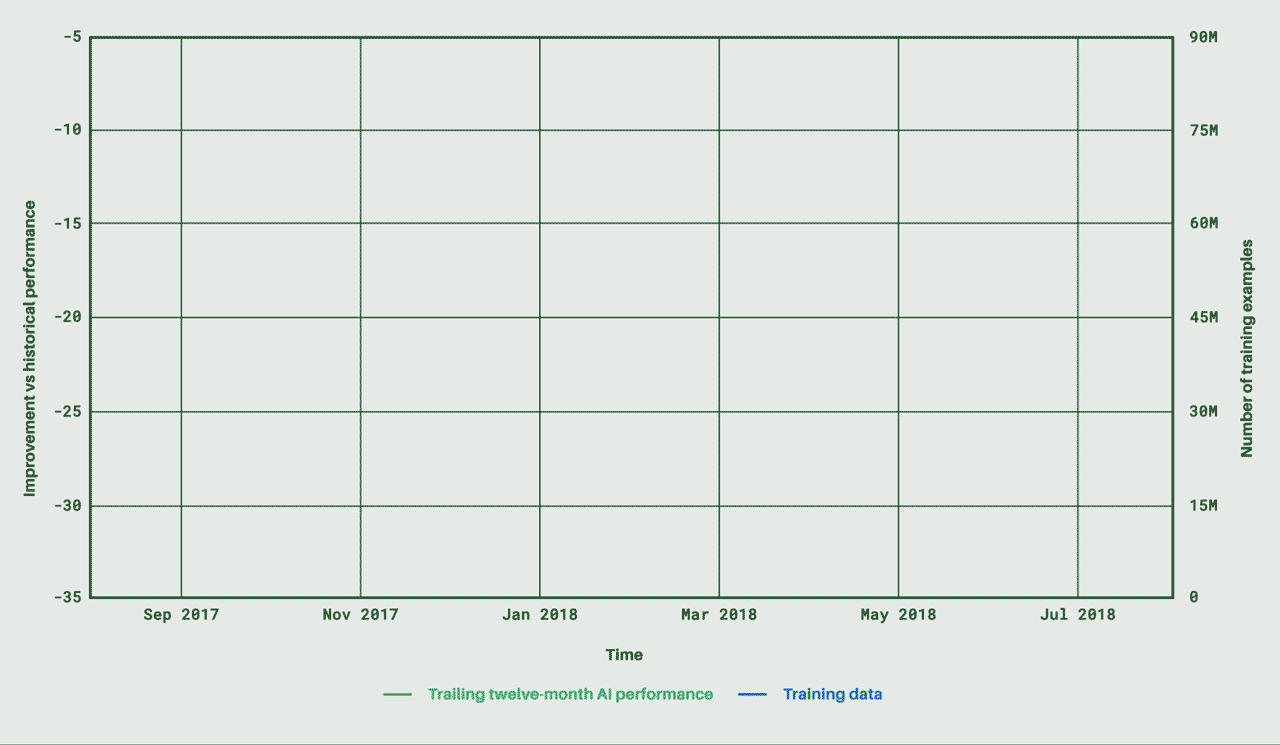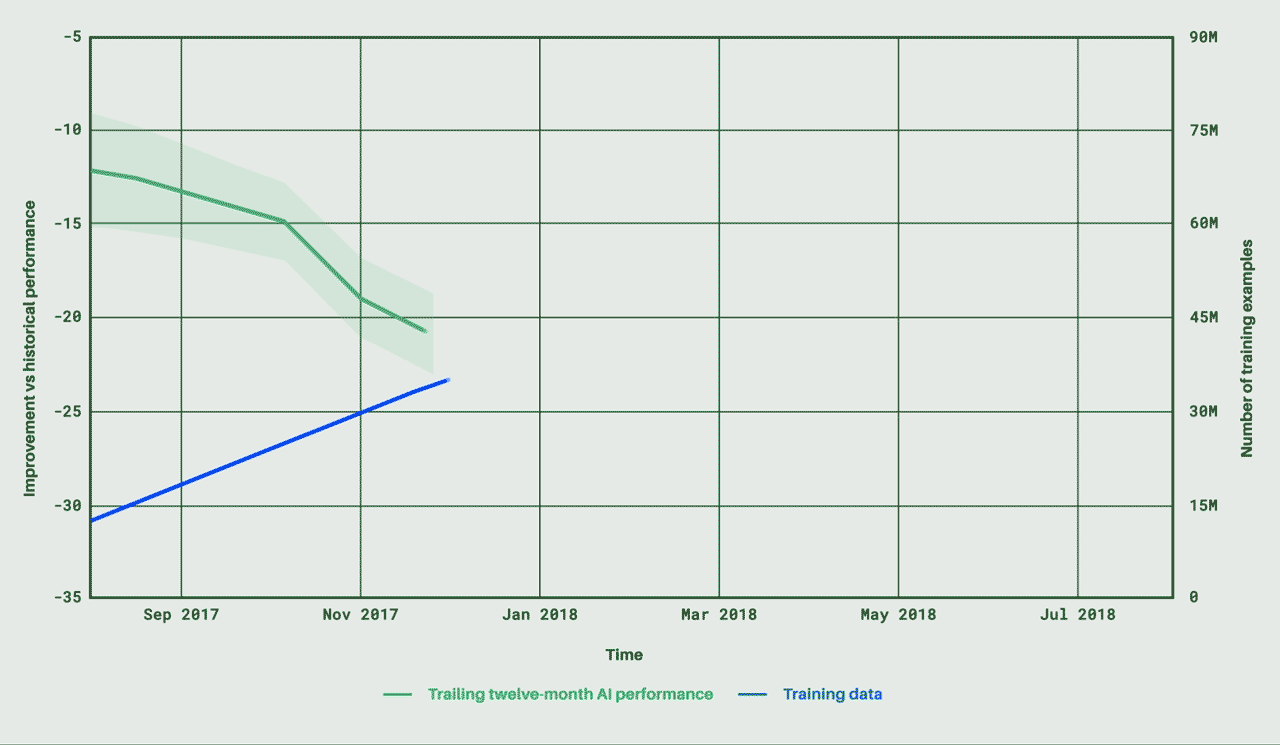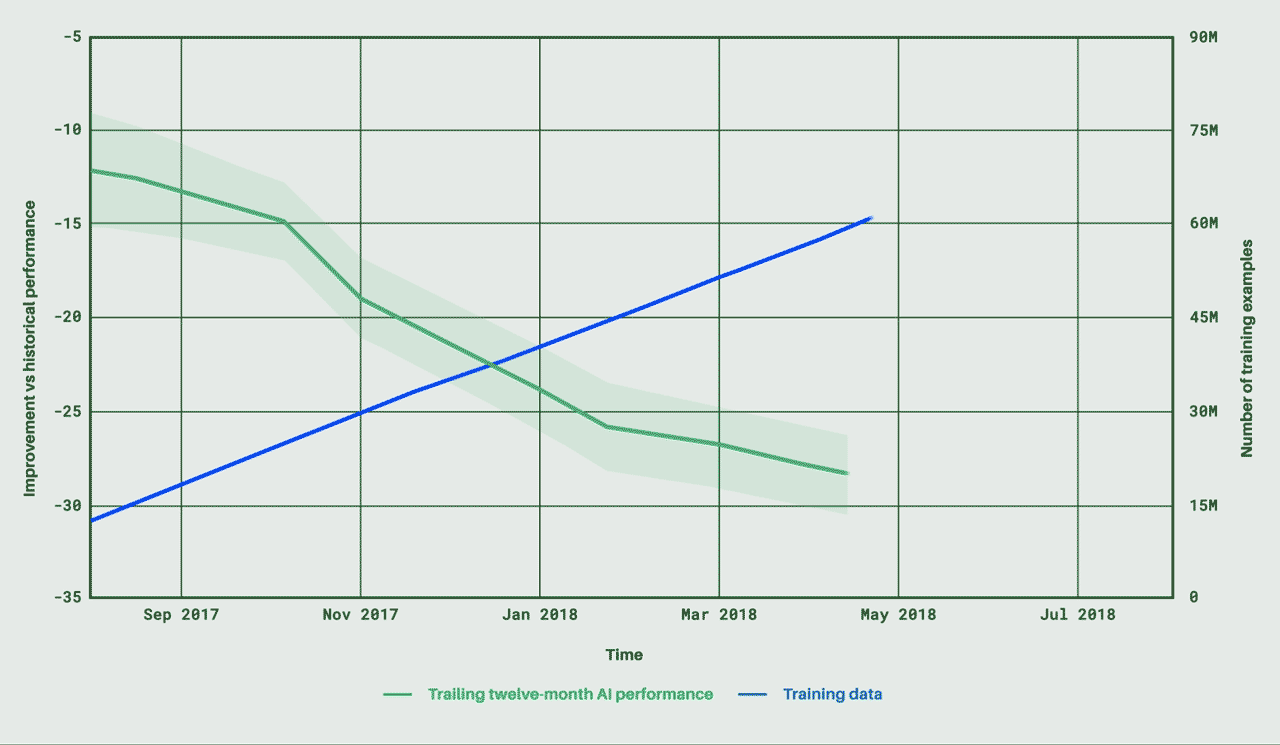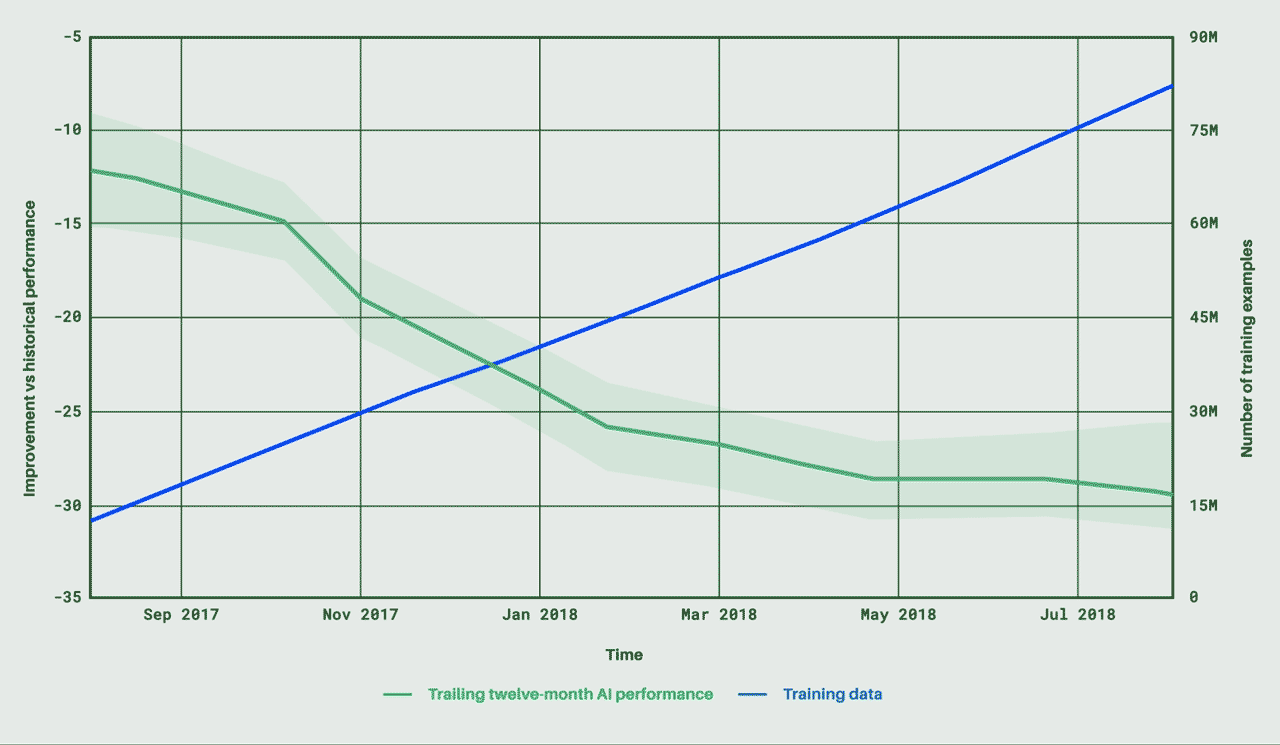
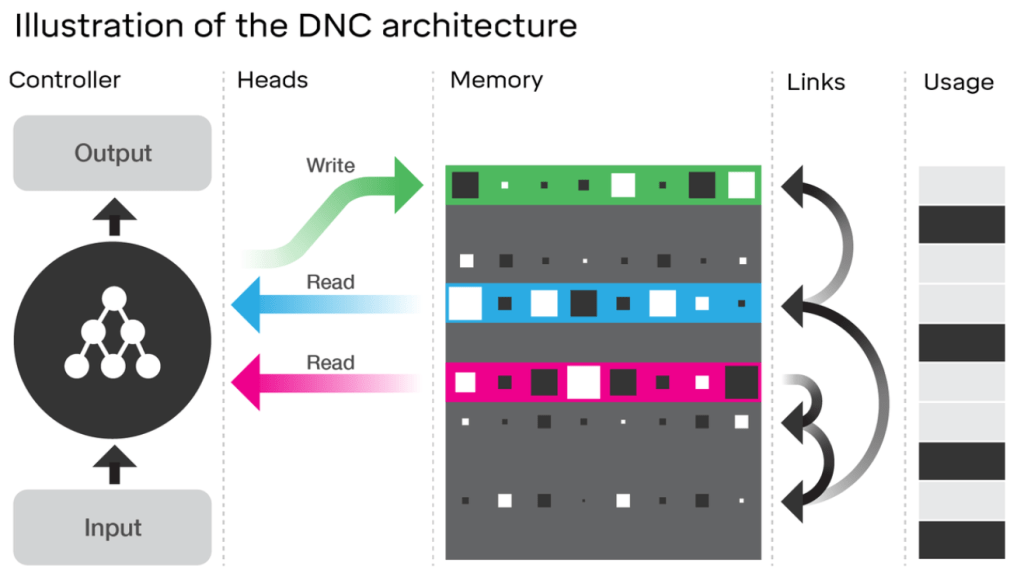
人工知能エージェントの開発現場では、その能力をゲームで測ることがよくあるが、それには相応の理由がある。ゲームは幅広い習熟曲線を提示してくれるのだ。ゲームは、基本的な遊び方は比較的すぐに習得できるが、マスターするのは難しい。しかも、通常は得点システムが備わっているため、習熟度を評価しやすい。DeepMind(ディープマインド)のエージェントは囲碁に挑戦し、リアルタイムの戦略ビデオゲーム「StarCraft」(スタークラフト)にも挑戦した。だが、このAlphabet(アルファベット)傘下の企業の最新の偉業はAgent57だ。Atari(アタリ)の57本のゲームすべてにおいて、さまざまな難易度、特性、プレイスタイルで標準的な人間を負かすことができる。
57本のAtariゲームで人間に勝るとは言え、使用するゲームによって深層学習エージェントの能力測定の基準が偏りそうな気がするが、これは2012年から採用されている標準的な測定法だ。使用されるAtariのクラシックゲームには、Pitfall(ピットフォール)、Solaris(ソラリス)、Montezuma’s Revenge(モンテズマズ・リベンジ)などが含まれる。これらをまとめて使うことで、難易度のレベルが大きく広がり、勝つために数多くの戦略を考える必要が生じる。
1つのゲームをプレイするごとに勝利確率を最大化していく効率的な戦略などを導き出すことが目的ではないため、これは深層学習エージェントの構築には非常に適した課題となる。つまり、こうしたエージェントの開発と、このような課題を与えたそもそもの目的は、種々雑多な、そして常に変化するシナリオや条件から学習できるAIを生み出すことにある。長期的に目指すのは、これまで遭遇したこともない目の前の問題に知性で対処できる、より人間に近い存在である汎用AIにつながるエージェントの構築だ。
DeepMindのAgent57は、Atari57セットの57本のゲームのすべてで人間に勝る能力を示した点で注目に値する。これまでのエージェントは、平均して人間よりも優れているに過ぎなかった。それは、行動と報酬の単純なループで上達できる同タイプのゲームを大変に得意とするものの、Montezuma’s Revengeのような長期の探検と記憶を要する高度なゲームではまったく振るわないためだ。
DeepMindチームは、問題の各側面ごとに個別のコンピューターが取り組むという分散型エージェントを構築し、それに対処した。一部のコンピューターは、新しい報酬(それまで出会ったことがないもの)に注目するように調整し、目新しさの価値がリセットされる時期を、長期と短期の2種類設定した。その他のコンピューターは、どの反復パターンがいちばん大きな報酬を与えてくれるかを基準によりシンプルな報酬を探し出す。これらすべての結果を総合し、与えられたゲームごとに異なるアプローチにおいてコストと利益のバランスを調子するメタコントローラーを備えたエージェントが管理を行う。
そうしてAgent57は目標を達成したわけだが、いくつか別の新しい方法による改善も可能だとチームは言う。1つ目は、演算量がきわめて膨大であるという問題がある。チームは、今後、無駄を省く方法を探る。2つ目は、簡単なゲームでは、もっとシンプルなエージェントに劣ることがあるという問題だ。それでも、従来の知的エージェントに対して上位5つのゲームで勝利している。チームは、他のそれほど高度でもないエージェントに負けてしまう単純なゲームでの能力を、さらに高める策はあると話している。
[原文へ]
(翻訳:金井哲夫)