この記事はCRUNHCH NETWORKのメンバーでEvaのファウンダー、CEOのFaisal Khalidの執筆。Evaは消費者向けモーゲージに関するチャットボットを開発中。
今年に入ってチャットボットについてのニュースをあちこちで見かけるようになった。まずMicrosoftがTayを発表したが、>女性の声でしゃべるのが性差別主義的だと非難されただけでなく、悪意あるユーザーに教えられた通りにあらぬことを口走るようになってしまった。次にFacebookがMessengerのボットをリリースしたが、上々の滑り出しとはみえない。それからAppleのVivが話題となった。一見したところSiri 2.0のように思えたのも無理はなく、開発者はSiriと同じだった。
ニュースだけは賑やかだったが、驚くべきことに、本当に出来のいい製品は一つとしてなかったように思える。
もちろん「本当に出来のよい製品」の定義をめぐって面倒な議論を始めることは可能だ。しかし簡単にまとめれば、素晴らしい製品には3つの特長がある。 (1)機能が分かりやすく使い勝手がいい。 (2) 99%以上の稼働率、(3)なんであれ、ユーザーが厄介だと感じる作業を大幅に肩代わりしてくれる。
そこで最初の問題に戻る。なぜチャットボットというのはああもダメなのだろう? ダメ、というのは、私には広くユーザーから喝采を受けているチャットボットが一つも思いつかないからだ。もっと重要なことだが、アプリよりも使い方が簡単なチャットボットの例も浮かんで来ない。どうしてこういうことになっているのか、少し詳しく検討してみる必要がありそうだ。
あまりに手を広げすぎたチャットボットは失敗する
VivとSiriがこの範疇に入る。どちらも「あらゆる問題に役立つ」ことを目標としたため、個々の問題を解決する能力が落ちてしまった。「すべてに対応する」という目標がなぜ問題を引き起こすのか理解するためにはチャットボットの動作の仕組みを理解する必要がある。
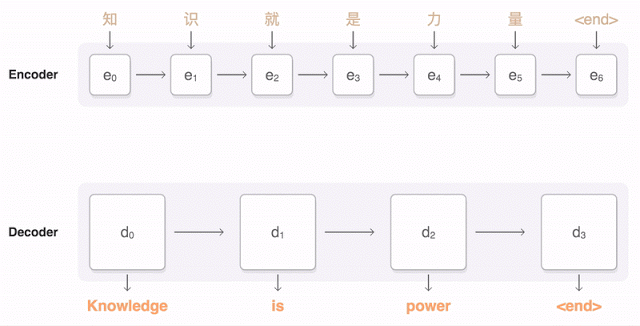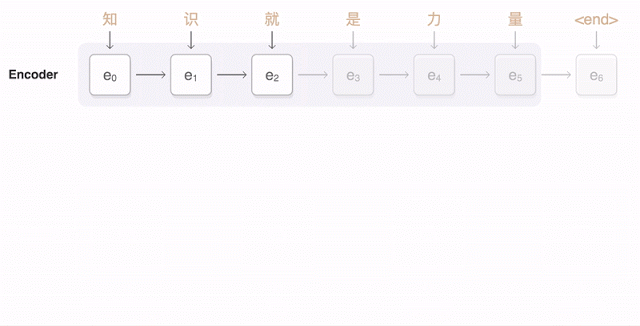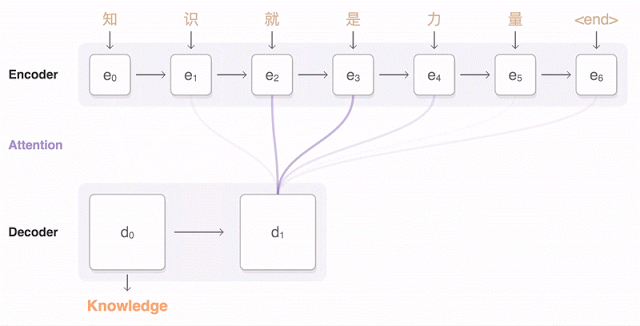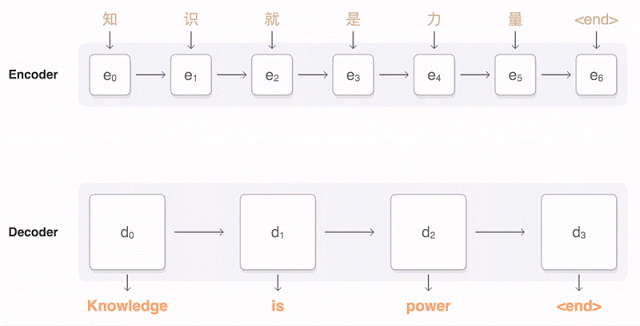
チャットボットは通常、「脳」と「ボディー」の2つの部分から出来ている。
まず「脳」だが、これは自動車を考えると分かりやすい。車にはエンジンが積まれていて車を走らせる。ボディーはユーザーの必要に応じてカスタマイズできる。ほぼ同じエンジンを積んでいてもボディーはSUVであったり、GTであったり、普通のセダンであったりすることが可能だ。
チャットボットも同様で、「脳」はユーザーの人間が発した言葉の意味を受け取り、実行可能なコードを生成する。狭い範囲の目的に特化したボットの場合、人間が発することを予期する言葉も狭い範囲に限定される。
たとえば、飛行機のフライトの予約に特化したボットを考えてみよう。フライト予約に関連して人間が発する可能性のある単語は100語から200語くらいだろう。そこでこうした発言を理解するボットを開発するのは難しくない。そんなボットなら私でも1週間で書けるし、その反応は99%以上適切だろう。しかしもっと広い範囲をカバーするボットを開発しようとすれば、それだけ多数の文が処理できなければならない。Siriのように「どんな場合にも役立つ」ボットであれば、理解しなければならない文の数は無限に近くなる。
「あらゆる文を正しく理解する」というのは信じがたいほど困難な作業だ。ほとんど無限といってよいエンジニアリング上の努力と時間を必要とする。人間の子供が言語を正しく使えるようになるのに数年かかるなら、人工知能が言語を理解できるようになるにもそのぐらいかかるだろう。しかし人間でさえ常に理解が成功するとは限らない。それは自然言語にはきわめて非論理的な側面があるからだ。たとえば6歳の子供は次に何を言い出すか分からない。しかし40歳の大人が相手だったら次に何を言いそうか予測することははるかにやさしい。
チャットボットのもう一つの要素は「ボディー」だ。私が上で述べたように、こちらは比較的「やさしい」部分だ。量は巨大であっても中身は「知識」にすぎない。ターゲットとする分野にもよるが、適切なカスタマイズにはもちろん多大のリソースを必要とする。さきほど述べたようにフライトの予約に役立てたいだけなら知識の量はさほど必要ない。おそらくはTripAdvisorのAPIを使うだけで相当に実用的なチャットボットが作れるだろう。
「なんでもできる」上に「非常に優秀」であるようなチャットボットはまず存在しない
私は金融分野で役立つチャットボットの開発を行っているが、この分野のハードルは非常に高い。必要とされる知識は莫大なもので、それをボットが利用できるように整理するためには非常に時間がかかる。金融サービスのサイトを見てみればわかるが、この分野の言語は特殊だ。チャットボットは、定義上、普通の人間が話したり、しゃべったりすることを理解でき、そのように話したり、しゃべったりできなければならない。金融は当然ながら複雑で理解が難しい分野だ。金融サービスの術語や特異な表現をチャットボットが話す言葉に翻訳するのはおそろしく時間がかかり、ハードルが高い作業だ。
本当に知的な作業ができるボットを作るのも難しい
こう言えば驚く読者も多いだろうが、現行の チャットボットの大半は実は全く知的ではない。ともかく私が使ったことがあるボットは知的ではなかった。チャットボットが知的かどうかは主として次の2つの基準で判断できる。(1) サービスが自己完結的であり、利用を続けるうちに自然と賢くなる。 (2)ユーザーは文字通り自由に文を組み立てて質問ができる。
具体例を考えてみよう。MicrosoftのチャットボットのTayは知的なボットの代表だろう。話しかけれられたことを何でも理解しようと務める様子がみえる。利用時間とともに機能も向上していく、つまりいちいち命令を受けなくても、聞いた言葉からパターンを抽出し、理解できるようになるはずだ。少なくとも理屈の上からは、そうだった。では知的でないボットの例はというと、残念ながらFacebook Messengerのボットの大部分、CNNのボットなどがそうだ。これらのボットが理解できるのは事前に用意された定型的な文だけだ。
ところが注意しなければならないのは、実際に役立つ―つまり予期せぬ動きをしたりぜず期待されたとおりに仕事をこなす―ボットは知的でない製品だ。その理由はこうしたボットは事前に決められた有限の道筋しか辿らないので失敗しないのだ。
デモでクールなチャットボットのUIを書くのは面倒な作業
こkで面白い点がある。われわれが見たチャットボットのデモのほとんどは(たとえばVivなど)こうした面倒な点をまったく無視している。優れたアプリの場合、ユーザー側の入力はほとんど必要ない。何度かスワイプし何度かクリックすれば終わりだ。それで役目は果たせてしまう。キーボードからのタイプはほとんど必要ない。ところがチャットボットではそうはいかない。
チャットボットは物事の説明を練習するには良い―うまく説明できるまで質問攻めにされる
現在のところ、たいていのチャットボットは音声認識をサポートしていない。そこでユーザーはひたすらタイプ入力を強いられる。当然ながらこれはスワイプやクリックに比べて時間を食う作業だ。その結果、チャットボットはアプリよりはるかに効率が悪いという結果となる。直感には反するかもしれないが、これが現実だ。しかも入力した文をボットが理解できない場合、ユーザーは同じ質問を別の表現に変えて再入力しなければならいので、能率はさらに悪くなる。
チャットボットは失敗を運命づけられているのか?
もちろんそんなことはない。その反対だ。しかし現在チャットボットはきわめて初歩的な段階にある。 ブラウザでウェブサイトを使うのに比べて専用アプリのほうがはるかに処理が速く、使用も簡単なことは10年から15年前に分かっていた。モバイル・アプリのメリットは当時から明白だった。
ところが現在チャットボットを利用してみても、メリット―スピードと使い勝手―は明白とはいえない。 またスピードが速く使い勝手がいい場合でさえ、正確性が不足しているために仕事に使えるのかどうか確信が持てない状況だ。
個人的な意見だが、「知的でない」なチャットボットがまず実用になると思う。たとえばカスタマー・サービスでFAQに答えるような場合には役立つだろう。また金融サービスのような複雑な問題をわかりやすく説明するのにも好適だ。もしもっと複雑な問題、たとえばそれまで接触がなかった顧客が家を買おうとするような場合に、必要な情報を細大漏らさず提供できるようなボットができればその価値は計り知れない。
チャットボットは同じ質問に疲れることなく繰り返し繰り返し答えることができる。ユーザーは納得がいくまで細かく質問できるし、ボットはそれに応じて細かい点まえ説明できる。またチャットボットは、長い入力書式を代替するのにも向いていると思う。書式に延々と入力させるのはいかにも非人間的だ。ボットの方がずっと人間味があるだろう。つまり起業家がチャットボットでビジネスを考える場合、適用可能な分野は数多くあるということだ。
最後にVivについて
一部にVivについての誤解があるようだ。まずVivはSiriではない。つまり「なんにでも対応」することぉ目的とする独立のチャットボットではない。先ほどの比喩でいえば、Vivは「脳」ないし「エンジン」の部分に相当する。Vivは回答に当たってサードパーティーのAPIからの入力を前提としている。Vivは他のチャットボットないしチャットボットAPIを作動させる共通のプラットフォーム、いわばチャットボットのOSとなることを目指している。
もしVivが成功するなら、やがてチャットボットのApp Storeのような存在となるだろう。チャットボットのデフォールトのプラットフォームを狙うんはFacebook MessengerやSlack、さらにその他のSNSも同様であり、Vivのライバルになるだろう。
さてチャットボットの将来は以上述べたようになるだろうか? 実のところ私にも確信はない。私はVivのような中央集権的、OS的なチャットボットが存在するのが良いことかどうかについても確信はない。われわれは新しいアプリが必要なときはApp Storeに探しに行く。将来はチャットボットもApp Storeのような場所に探して行くことになるのだろうか? 今は分からないとしか言えない。しかしやがて判明するときが来るだろう。
F画像: photosync/Shutterstock
[原文へ]
(翻訳:滑川海彦@Facebook Google+)