昨年後半は
セマンティック検索関連の記事を多数配信してきたSEO Japanですが、今回、セマンティック検索を検索結果も含めて丁寧に解説してくれたサーチエンジンランドの記事がとてもわかりやすかったので新たに紹介します。「セマンティックネタは小難しいからいい!」といわれそうですが、我慢して3回読むときっとあなたもセマンティック検索通、イコールGoogleを現在と今後を堂々と語れるエキスパートに返信できそうな内容です! — SEO Japan
検索は、変化しており、検索結果(SERP – Search Engine Result Page)も変化している。SERPは、順応性を高め、魅力を増し、有益になり、対話性を高め、そして、パーソナライズされている。
セマンティック検索、そして、セマンティックウェブを効果したSERPの表示形式は、ヤフー!、そして、同社のサーチモンキーの結果で、初めて採用されていた。その後、ヤフー!に続き、今度は、グーグルが、リッチスニペット、そして、ナレッジグラフ、さらには、関連する変化を加えた表示を行うようになった。

消化され、処理されるデジタルデータ
現代の検索エンジンのユーザーは、「ナレッジパネル」、そして、グーグルのナレッジカルーセル内の集められた結果に慣れ親しんでいる。この記事を作成する時点でのグーグルの最新の告知では、同社は、ナレッジグラフの情報が、自然の結果に割り当てられていたスペースの一部に移動する可能性があると指摘している。
グーグルが機能を拡大、および、強化していく中で、この勢いを活用するために、確実に講じておきたい基礎的、そして、重要なステップがある。検索エンジンに対して、最善の方法でコンテンツを提示することが出来るようにするシグナルをグーグルに提供する方法である。
セマンティック SERPを活用する方法を説明する前に、まずはセマンティック SERPとは何かを明らかにしておく。
セマンティック SERPを理解する
セマンティック検索の手法は、検索のプロセスの多くの段階で、検索エンジンによって用いられている。ユーザーの意図を正しく理解するため、または、クエリを変換するため、もしくは、情報を抽出するために、セマンティック検索が用いられる仕組みは、頻繁に取り上げられているものの、検索のプロセスのその他の段階で、セマンティック検索が用いられる仕組みは、あまり語られることはない。この記事では、最後のステージ、つまり、検索結果がエンティティ(コンセプト、または、オブジェクトと呼ばれることもある)として引き出され、続いて、ユーザーに提示される段階に焦点を絞って説明していく。
セマンティック検索は、多くの面で、エンティティ検索と同一視されることが多い。エンティティ検索とは、単純にエンティティのグラフで検索を行うプロセスを差す(もちろん、結果を返すプロセスも含まれる)。
プログラミングの世界に慣れ親しんでいるなら、オブジェクトと見ることが出来る。例えば、製品、場所、人物、レシピ等、オブジェクトが何かによって、オブジェクトが異なれば、オブジェクトに関連付けることが可能な特徴や行動(または、アクションや処理方法)も異なる。オブジェクトを結果として入手していることを考えると、ユーザーに対する結果の提示は、柔軟であり、さらには、実用的である(例えば、製品のタイプのオブジェクト/エンティティが検索クエリの結果として返される場合、関連する行動/メソッド/処理方法は、返された製品の購入が該当する可能性がある)。
SERP内のエンハンストディスプレイ(強化型表示)は、返されるエンティティ/オブジェクトのタイプに左右される。画像、レビュー、価格等は、返されるエンティティ/オブジェクトのタイプに応じた特徴を持つ。このようなオブジェクト/エンティティ内のコンテンツは、ユーザー体験を改善するため、(リッチスニペット等)魅力的にオブジェクトを表示することが可能であり、尚且つ、コールトゥアクションを含めることも出来る。あるイベントに対するコールトゥアクションとして、例えば、イベントのチケットの購入が該当することもある。また、これは、様々なデバイスのタイプ等に順応して表示する結果を促進するメカニズムとしても、当然、理想的である。
セマンティック検索へのシフトチェンジと併せて、ある重要な変換が行われている。最近では、データに照らし合わせた検索(グーグルの場合、内部で収集されたナレッジグラフ)が、文書の照らし合わせた検索(通常、文書にはウェブページが該当する)の代わり、または、連動して行われることが多い。
データに照らし合わせた検索
データに照らし合わせた検索は、通常、クエリに対する直接的な答えを生成する — あるいは、複数の答えが返される場合は、同じタイプの結果のリストが返される。後者は、カルーセルタイプの表示にとても役に立つ。データに照らし合わせた検索は、基本的に、ナレッジグラフの処理と同一視される(グーグルのみに言及する場合)。
文書に照らし合わせた検索
文書(ウェブページ)に照らし合わせた検索は、文書を表示することが多い。グーグルでは、SERP内で結果として、リッチスニペットが表示される可能性がある。リッチスニペットは、ウェブページの結果のエンハンストディスプレイであり、ウェブページから直接メタデータをエンベッドする(当初、ヤフー!が、サーチモンキーで、ビングはタイルで活用した)。
(SEOの観点で考えると)リッチスニペットによる表示を可能にするためには、最低限の量の構造化データをウェブページに盛り込む必要がある点を肝に銘じておくべきである。
セマンティックSERPの変化する状況
検索が、セマンティック検索化への移行をより明確にするにつれ、SERPは、リッチな表示を強化するようになった。以前、私は「エンティティ検索」と呼んでいたが、セマンティック検索と直接関連するため、そして、(ほとんど対処しようのない、味気のない、動かない、退屈な青いリンクと比べて)リッチ & 魅力的な表示が、セマンティック検索の採用と結びつくようになったため、セマンティック SERPと呼ぶようになった。
グーグルやその他の主要な検索エンジンは、SERPの表示を強化する取り組みを常に行い、より有益に、より魅力的に、そして、より双方向的になるよう心掛けている。
コンピュータを、コンセプトの概念を教え込まれた(schema.orgやナレッジグラフ等)何も描かれていないキャンバスと考えると、コンピュータは与えるコンセプトと情報のみに対応する可能性がある。この状況では、認証された、構造化されたソースから得られる情報が多ければ多いほど、当該の情報に対する信頼は強くなる。
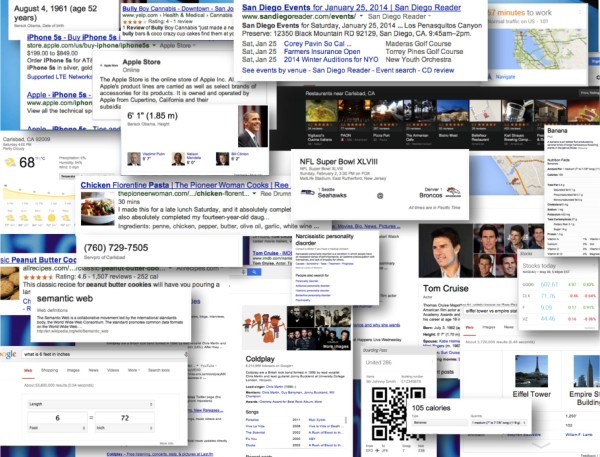
進化するセマンティック SERP
さらにリッチ化するリッチスニペット
リッチな表示は、導入された当時と比べると、遥かに多くの情報、そして、多くの種類の情報を表示するようになっている。その上、表示される情報は、時間の経過と共に進化している。現在、リッチな表示が、クリックスルー率に大きな影響を与えることは、周知の事実である。
エンティティは、完全なエンティティの結果として提示されるためには、十分な量の情報を用意していなければならない点を理解する必要がある。ただし、表示されている既存の「スニペット」をマークアップするだけでは不十分である。適用可能なschema.orgを多く使って、出来るだけ詳しくマークアップしなければならない。また、データが、一貫しており、正確である点を裏付けてもらいたい。例えば、製品のSERPでは、在庫があるなら実際に在庫がある点を、また、ランディングページにリンク切れがない点を確認する。
いずれにせよ、オンページのマークアップを検索エンジンが読むことが可能である点、そして、ユーザーに表示される情報と同じである点をチェックする必要がある。加えて、何らかのデータフィードに、または、APIを介して投稿する情報がマッチしており、検索エンジンとユーザーに提供するその他のデータと同期している必要がある。
リッチスニペットは、さらにリッチ化しているだけでなく、絶えず動いている。この点を意識し、構造化マークアップ形式で、出来るだけ多くの情報をウェブページで提供すると、アドバンテージを得ることが出来る。

リッチスニペットがさらにリッチ化(スクリーンのスペースをさらに獲得 & 流動化)
増加する直接的な答え
直接的な答えは、セマンティック SERP、グーグルナウ、そして、一般のSERPで大幅に増加している。これは「データに照らし合わせた検索」がもたらした結果である。SEO/SEMコミュニティは、グーグルの結果で提供される答えが、サイトへの自然のトラフィック(またはクリックスルー)と競合する点を以前から指摘してきた。
確かにその通りかもしれない。求めている情報が、SERPに掲載されているなら、ユーザーはクリックしてサイトを訪問することはないだろう。
ただし、店舗のオーナーの視点では、コールトゥアクションへの呼応が、それでも起きるケースもある。これは、所謂辞書を調べる検索(複数の認証されたソースからデータが表示される)よりも、インフォメーショナル検索(クエリに対する直接の答えによって、電話をかける)に該当する。

SERP内の答えが増加中
同様のアイテムの分類、または、検索結果の収集
エンティティのタイプが似ている際に行われる、検索結果の収集は、カルーセルの表示に向いている。[San Diego Universities](サンディエゴ大学)、[restaurants in Atlanta](アトランタのレストラン)、あるいは、[events in Chicago](シカゴのイベント)等の検索は、グーグルのSERPで、カルーセルタイプの表示をもたらす。
表示されるアイテムのタイプ(例えば、イベントの日時やレストランの評価)によっては分類のオプションが提供されており、活用されるケースが増えている。カルーセルの利便性を説明するため、今週の火曜日、グーグルは、ホテルのカルーセルで日時の選択ツールを表示する取り組みを始めたと告知していた。
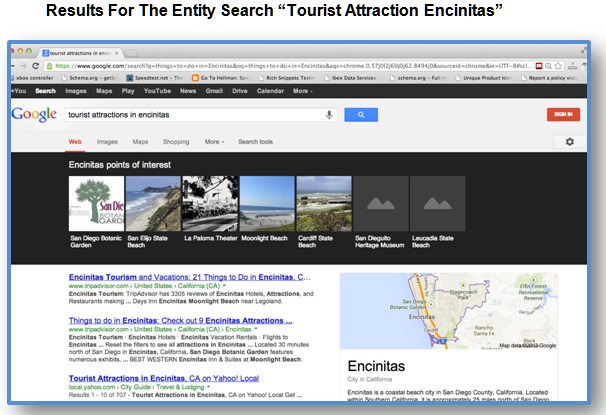
下の例では、SERP内に表示されたナレッジグラフは、ナレッジグラフ内の「things to do」(オブジェクトのタイプ「tourist attraction」(旅行者向けのアトラクション)にマッチする)に対する結果のリストを描いている。別のカルーセルは、クエリ「Events in San Diego」(サンディエゴのイベント)に対する、結果を表示している。このようなイベントは、(旅行者向けアトラクションと比較して)一時的な特徴があり、イベントの開始時間(および終了時間)と日付が特定されている。

イベントとアトラクションを描写するナレッジカルーセル
ナレッジグラフが自然なSERPのスペースを侵食中
最近まで、ナレッジグラフの結果は、スクリーンの上部、そして、スクリーンの右側に「パネル」として、掲載されていた。先程も申し上げた通り、グーグルは、先週の告知で、ナレッジグラフの一部の情報が、自然なSERPに盛り込まれるようになると指摘していた(詳細はこの記事を参考にしてもらいたい)。
この取り組みのインパクトは、下のスクリーンショットを見れば一目瞭然である。これは、「Nikon Coolpix camera Y」の自然のSERPを撮影したものである。ナレッジグラフの結果が、もともとはウェブページのみのSERPの領域に侵入している点は明白である。

自然なSERPのスペースに侵入するナレッジグラフの結果
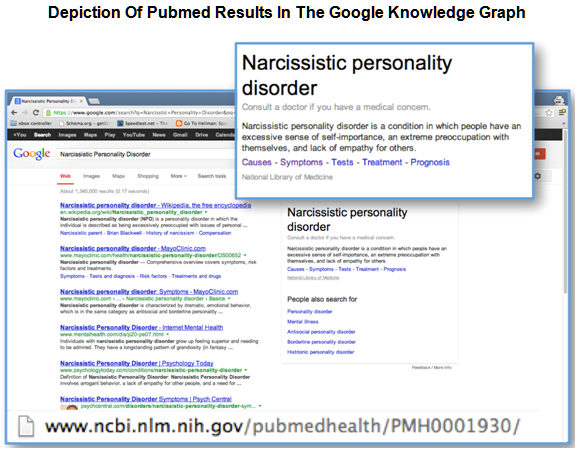
ナレッジグラフのスニペットを優先し、リッチスニペットの情報が、小さく表示される、あるいは、表示されないケースもある。以下の例は、[peanut butter eyeballs]のレシピを検索した際のSERPを描写している。 先週、グーグルがアップデートを行った後、材料はリッチスニペットとして表示されなくなり、代わりに、強化されたナレッジグラフの結果が現れるようになった。

クリックして拡大
schema.orgの構造化データマークアップを使って、出来るだけ多く情報をマークアップする取り組みは、絶対に欠かせない。検索エンジンは、自分が好む情報を選ぶことが出来るものの、出来るだけ多くのアトリビュートをマークアップしておくことで、今後の変更に対して、より有利な立場に身を置くことが出来るようになるためだ。
まとめ
セマンティック検索化への進化が加速する中、SERPも同じように進化を遂げてきた。SERPに対する最適化を行うには、セマンティックマークアップ、そして、ナレッジグラフを考慮する必要がある。
セマンティックマークアップとナレッジグラフの最適化は、グーグルでのウェブページの表示を最適化する上での幾つかの領域と重複しており、その中には、通常のベストプラクティスも含まれる。注目を集めるコンテンツの作成、ポジティブなユーザー体験の提供、または、ユーザーの意図を考慮した最適化等のベストプラクティスとスタンダードは、ここでも守る必要がある。
重要な教訓
1. グーグルボットを常に満足させる — グーグルボットが必要とする形式で、必要とするデータを与える。ボットが読むことが可能であり、すべてのソースにおいて一貫性が保たれている点を確認する。
2. オンページのマークアップが、ユーザーが目にする情報と一致している点、そして、投稿するデータフィードと同期が取れている点をチェックする。
3. 現在サポートされていないアトリビュートであっても、schema.orgを使って、出来るだけ多くデータをマークアップする。こうすることで、セマンティック SERPの変化および変動を活用することが出来るようになる。
4. 検索には順応性があり、また、検索はインタラクティブに行われる点を肝に銘じておく。検索エンジンが提示するSERPと連動するシームレスなユーザー体験を作る。
5. ナレッジグラフの最適化は、今後も留まる可能性が高いため、対応する準備を進めておく。
この記事は、Search Engine Landに掲載された「From 10 Blue Links To Entity SERPs: Is Your Website Ready?」を翻訳した内容です。
重要なトピック毎にわかりやすい説明で技術肌の人以外にも優しい良い記事でしたね。ちなみにタイトルの「奇跡」はGoogle誕生時からSEOに関わってきた人間として今日のセマンティックSERPに敬意を表しての表現ですので、ツッコミ不要です m(_ _)m — SEO Japan [
G+]