
[筆者: Vik Singh]
編集者注記: Vik SinghはInferの協同ファウンダでCEO。それまでの彼はSutter Hill Venturesの正社員起業家。彼は検索やソーシャルネットワークやコンテンツオプティマイゼーションの分野で13件の特許を持っている。
その業界に詳しいDavid Raabの説では、マーケターの三人に二人は既存のマーケティング自動化ソフトウェアに大なり小なり不満である。またBluewolfの調査報告書“State of Salesforce”は、マーケティングソフトへの投資のわずか7%しか、まともなROIを得られないという。この、企業や商店に大きな利益をもたらすはずの自動化マーケティングは今、標準性を欠く乱雑な多様化とユーザの不満が激化しているのだ。
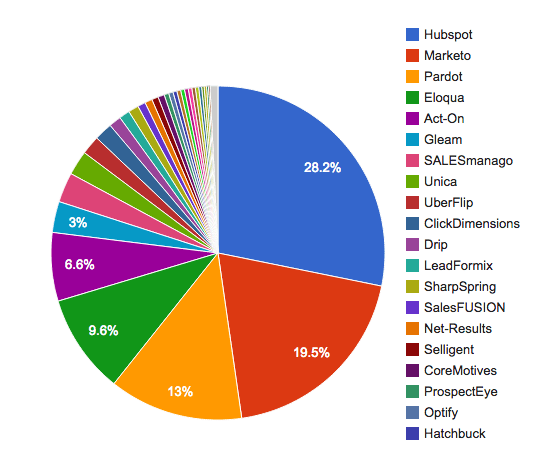
マーケティング自動化サービスのマーケットシェア(出典: Datanyze)
自動化マーケティングがそうなってしまった原因は、そのルーツがメール爆弾であることにある。そういうシステムはユーザのターゲットページや入力フォームやWebのアクティビティデータやトリガや、などなどに長年勝手に貼り付いてきたから、だんだん、やることが多くなって肥大し、ユーザがうんざりするような、口数ばかり多い無能ソフト/アプリケーション/サービスへと頽落した。
たとえば下の図はEloquaのスクリーンショットだが、この積み木ゲーム(Jenga)のような画面を見ると、われわれ自動化マーケティングの連中が今マーケターたちに提供しているものが、どんだけややこしくて脆(もろ)いものであるか、が分かる。われわれ、と言ったのは、こんな面倒な推奨ワークフローをマーケターに提示しているのは、Eloquaだけではないからだ。
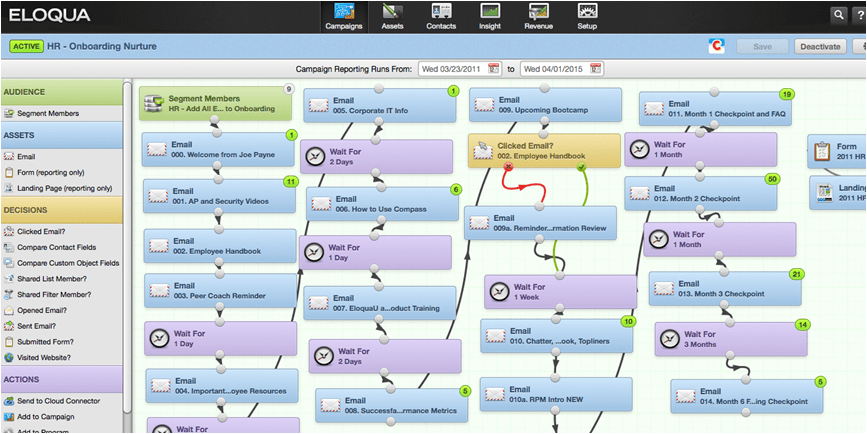
自動化マーケティングが自動化しない
最大の問題は、上図のようなワークフローが、良い見込み客を見つけるための画一的で普遍的な法則とされ、具体的なデータに基づく指針になっていないことだ。
たとえば、こんなワークフローだ: “ユーザがこのリンクをクリックして、そのあと、あのリンクを二度クリックしたら、二日後にこのメールを送りなさい…”。これが、絶対的なルールとして書かれている。ユーザがWebサイトのデザインを変えたら、この(多くの人が無視したであろう)ワークフローは、もう使えない。
こんな低レベルな構成では、多様な現実への対応がほとんどできない。こういうワークフローを作った者がいなくなったら、どうするのだ? ワークフロー地獄は深刻なパフォーマンスの問題ももたらす。
私が実際に見たある企業は、自動化マーケティングシステムのすべてのワークフローを8時間以上もかけて処理してから、やっと見込み客をCRMシステムに渡していた。ネットで見つけた見込み客に営業が接触するまで、8時間以上もかかるのだ。自動化マーケティング約束した、スピードと単純化と、そしてまさに自動化は、どこにあるのだ?
2018年にはどのマーケティングプラットホームが優勢か?
今は、自動化マーケティングを再発明すべき時だ。そのプラットホームは、スケーラブルで応答の速いデータベースと、データに連携したワークフローシステムを提供する必要がある。それは、見込み客や顧客に関するデータを調べることに最適化された、軽いシステムでなければならない。また、サードパーティが特殊な目的の応用システムを構築できるために、クリーンなAPIを提供すべきだ。
そんな方向に向かうための条件は、早くも整いつつある。まず、膨大な量の外部データ、先進的なデータサイエンスと、さまざまな特殊目的に対応するマーケティングアプリケーションの登場。3年後の2018年には、新世代の自動化マーケティングソフトウェアが出揃うだろう。そして2018年に優勢になっているマーケティングプラットホームは、予測能力があって、どんな見込み客に対しても適切なリコメンデーションを出力する、オープンなプラットホームだ。
最初に予測ありき
明日のプラットホームは、何もかも詰め込んだ一枚岩的な自動化マーケティングシステムではなく、インテリジェントで痩身で、多くの小さな専門的アプリケーションに接続できる基幹プラットホームだ。それは豊富なデータに基づいて、顧客とのさまざまなタッチポイント(接触点)に適切なリコメンデーションを配布する。
最新のデータサイエンスと、それに基づくビッグデータ分析や機械学習技術により、そこらにあるさまざまなデータから重要な信号を読み取ることが、できるようになっている(Netflixのムービーのリコメンデーションは一体どうやっているのか、考えてみよう)。またコンピューティングのインフラストラクチャが安価になったので、多様な顧客モデルの作成とそれらに基づく具体的な個人化を、個々の企業に合わせてできるようになった。今ではConversicaやLytics、RelateIQ、そしてInferのような企業が予測分析を誰の手にも届くようにし、見込み客の育成やキャンペーンの最適化、見込み度の判定など、自動化マーケティングのこれまでの課題だった項目に対しても、より効率的で効果的なソリューションを提供している。
予測能力のある人工知能(predictive intelligence)は今、すべての企業がこぞって求めている。それがさまざまなニッチのアプリケーションと結びついたプロダクトやプラットホームは今後、誰にでも使えて、具体的なアクションに結びつくシステムとして普及するだろう。それは使いやすいだけでなく、企業の進化の方向性に即したものでなければならない。そんなシステムは、ワークフローの構成など面倒なタスクも自動化するので、ユーザはパフォーマンスのチューニングとか劣化などを心配する必要がない。こういう予測型のシステムは、一人々々の顧客のアクションについて自分で学び、適応し、そして自分を改良していく。
マーケティングとセールスを循環させるリコメンデーション
(フルサークル (full-circle)リコメンデーション)
一人の顧客や見込み客に、マーケティングとセールスが別々に対応すべきではない。未来のプラットホームは顧客データをめぐる派閥性を解消し、すべての、マーケティング/営業機能を一元化する。今すでにKnoweldgeTreeなどのサービスは、営業とマーケティングとのあいだの風通しを良くすることによって、それを実現しようとしている。次のベストアクションやベストコンテンツが、片方の独断で決まらないようになる。
顧客に関する予測も、営業とマーケティングが共有する。セールスデータの履歴をよく吟味して、良い見込み客とはどんなタイプか、を見つけ出す。そしてその情報を、営業とマーケティングの両方に浸透させる。さらに、その結果に対しても然りだから、この情報活動には循環性がある。そこで‘フルサークル’と呼ぶ。
良い見込み客を拾い上げるための予測モデルを、短期的なCR(コンバージョンレート)重視型から長期お買い上げ重視型に変えることができれば、カスタマーサクセスチームがそれを利用して顧客のロードバランスを図れる。
オープンなプラットホームを目指せ
次世代のマーケティングプラットホームは強力なAPIを提供する。Autopilotがその好例だが、でもどんな企業でも、焦点を絞った、インサイトに満ち満ちた、由緒正しいツールを作ることはできる。それらは今はびこっている、何でも屋のような、インテリジェンスのないプラットホームより10倍も優れている。
たとえば仕込みキャンペーンをやる場合は、予測インサイトと痩身的システムならではのスケーラビリティを利用して、それまで無視してきた仕込み用データベースから見込み客を見つけるだろう。そういうデータベースは、見込み客の見込み度の得点を、彼らのWebビヘイビアに応じて絶えず更新しているから、仕込み客を見つけるのにはうってつけだ。そしてそういう見込み度の高い見込み客に個人化されたメールを送ったり、そのリストをセールスに回すことによって、仕込みキャンペーンが回り出す。
今ではマーケティング関連のサービスが2000近くあると言われる。CRMのSaaS化や自動化マーケティングが流行(はや)ってきたためだが、SalesforceのAppExchangeの影響も大きい。でも自動化マーケティング関連のサービスは、まだ幼児期にあるため、充実したエコシステムやAPIがなく、したがって成功例に乏しい。
でも、個々のアプリケーションのレベルでは、優れたものが現れ始めている。そして今後のオープンなマーケティングプラットホームは、CRM型ではなくデータ型(データ分析型)になるだろう。そもそも、CRMにデータを提供したり、またCRMからデータを拾う側、すなわちデータサイドが、顧客情報を長期的に多く集積しており、それらが効果的に分析されれば、マーケティングに大きく貢献しうるのだ。
クラウドコンピューティングが伸びていくとき、“ソフトウェアの終焉”という言葉が言われたような意味で、予測型プラットホームは自動化マーケティングというカテゴリーに革命をもたらす。未来のマーケティングは、キャンペーンの管理や見込み客の行動調査などを超えたものになる。
新しいプラットホームは、ワークフローとプログラムとアクションの形を、今後ますます強力になる予測インサイトの枠組みの中で変えていく。それらのワークフロー等は、マーケティングとセールスのあいだのギャップを、予測を糊としてCRMと自動化マーケティングをくつける(一体化する)ことにより、橋渡しする。
身軽でスケーラビリティの大きいデータプラットホームというものがまずあり、そこに予測のレイヤを置く。そしてコンバージョンを高めセールスを成功に導く良質なアプリケーションが、予測を活用する。初めに予測ありきのソフトウェアが世界を食べている。今その歯は、マーケティングとセールスに食らいついたところだ。覚悟を決めよう。
〔訳注: 本稿の筆者は、機械学習による予測ソフトのベンダ。自分が前に買ったり調べたりしたものに基づいて、来る日も来る日も、同じようなものの広告ばっかし見せてくれるのは、そういう‘機械的’ソフトが猛威を揮っているから。マーケティングが、その企画者実行者の人間知と人間性と創造力に基づく、クリエイティブな営為、新しいものや新しい発想を作り出す仕事であることは、ここでは完全に無視されている。本当のヒット商品や人気店は、どうやって生まれているのか、考えてみよう。データの集積と分析は重要だが、それらの処理の形や方向性を決め、処理結果から何かに気づくのも、人間性の能力だ。〕
[原文へ]
(翻訳:iwatani(a.k.a. hiwa)














{kind=link}
{kind=link}
{kind=link}