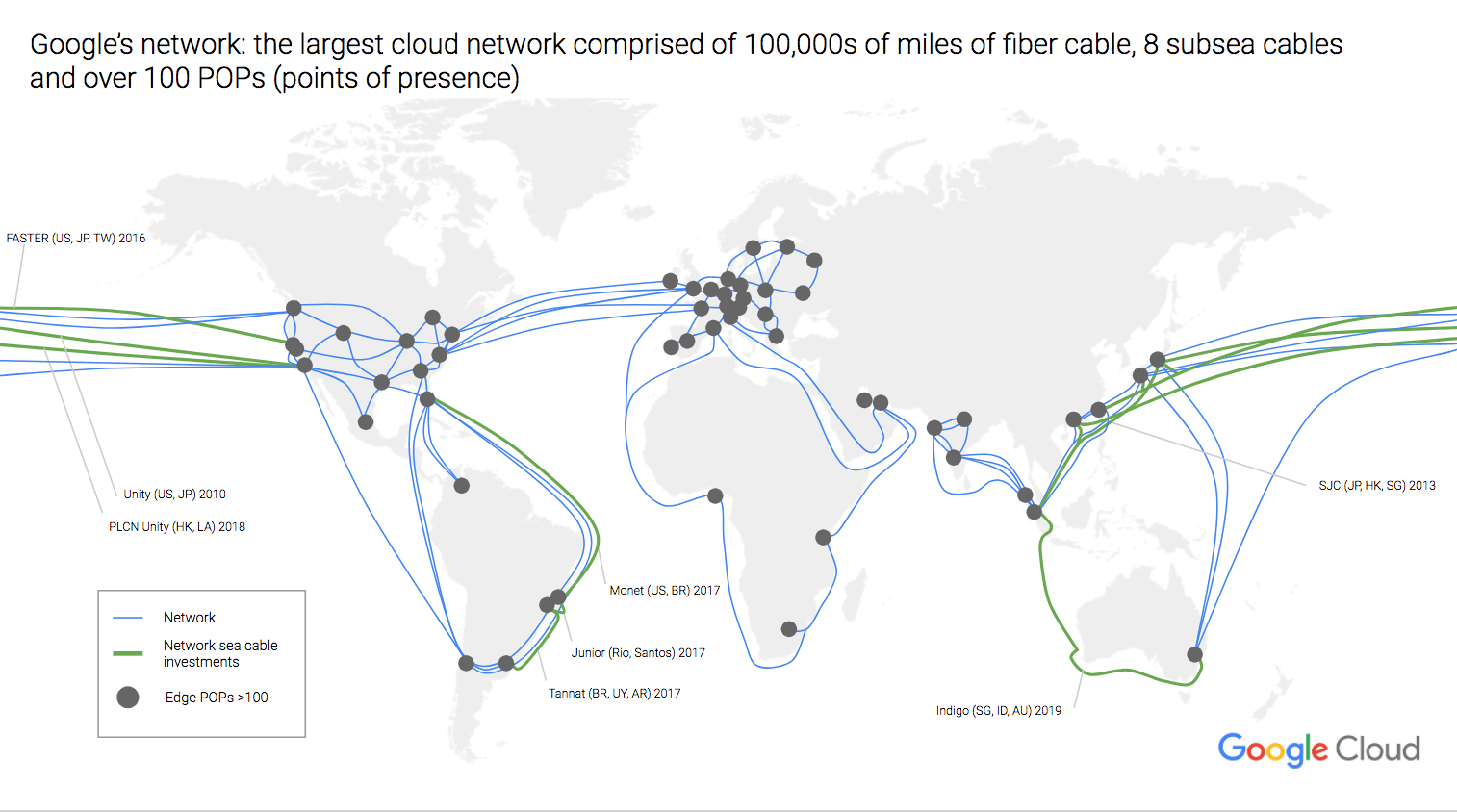
PivotalとVMwareとGoogleがチームを作って、コンテナプロジェクトの開発とデプロイと管理を、十分なスケーラビリティを維持しつつ単純化する総合的サービスを提供していくことになった。
三社はオープンソースのプロダクトをベースとする商用サービスにより、このパートナーシップを構成するさまざまなパーティーと共にそのプロダクトを市場化していく。GoogleはそれをGoogle Cloud Platformの一環として売ることになり、PivotalとVMwareでは彼らの標準の営業品目として売り、両社の親会社であるDell-EMCはハードウェアを含めたパッケージとして売っていく。
彼らの役割分担を整理するとこうなる: GoogleはオープンソースのコンテナオーケストレーションツールKubernetesを提供する。PivotalはCloud FoundryによりPaaSの要素を提供、そしてVMwareは全体をまとめる管理層を加える。
プロダクトの名前にはPivotalが使われ、Pivotal Container Serviceとなる。省略形はPCSではなくPKSだが、たぶん彼らは頭字語という言葉の意味をよくわかっていないのだろう。いずれにしても、三社が肩を組んでやることは、VMwareのvSphereとGoogleのCloud Platform(GCP)をベースとする“プロダクションに即対応する(production-readyな)Kubernetes”を提供していくことだ。そしてそれは継続的に、Google Container Engineとの互換性が確約される。後者はご想像どおり、GCEではなくてGKEなのだ。¯_(ツ)_/¯
以上は説明だが、このプロダクトが実際にベースとするものはGoogleとPivotalが作ったコンテナ管理プロダクトKuboだ。そしてPKSは、PivotalのCloud Foundryによる、デベロッパーにとっておなじみのコンテナ開発環境を提供する。デベロッパーはKubernetesの経験者であることが前提だ。
VMwareは縁の下の力持ちのように管理層を提供し、その上でDevOpsのOpsの連中がコンテナをデプロイし、コンテナのライフサイクルの全体を管理する。以上を総合すると、エンタープライズ級のコンテナ開発〜デプロイ〜管理のシステムの、一丁あがり、となる。
Google Cloudのプロダクトマーケティング担当VP Sam Ramjiによると、昨年Googleに来る前、Cloud Foundry Foundationにいたときすでに、コンテナをプロダクションに持ち込むためのいちばん容易な方法がCloud Foundryだ、と直観していた。そして当時の彼らは、Kubernetesを統合するやり方を研究していた。
一方、PivotalのJames Watersはこれまで、PivotalのツールとともにGoogle Cloudのツールを使っている大企業顧客が多いことに気づいていて、そのツールキットに、人気急上昇中のKubernetesを含める必要性を痛感していた。
VMwareはどうか、というと、Sanjay PoonenらVMwareの連中はこれまで、コンテナの開発環境としてCloud Foundryを使う大企業顧客が多いことと、Kubernetesがコンテナオーケストレーションエンジンとしての勢いを増していること、この二つの支配的な状況を日々、目にしていた。
そして今回、そのような三者が交わったところに出現したコンテナ統合環境(開発/デプロイ/管理サービス)が、今回の三社パートナーシップの成果だ。その供用開始は、今年の第四四半期を予定している。
〔関連記事:
●三社パートナーシップに導いた7つの動向(未訳)
●VMware CloudがAWSからも提供(未訳)
〕
[原文へ]
(翻訳:iwatani(a.k.a. hiwa))