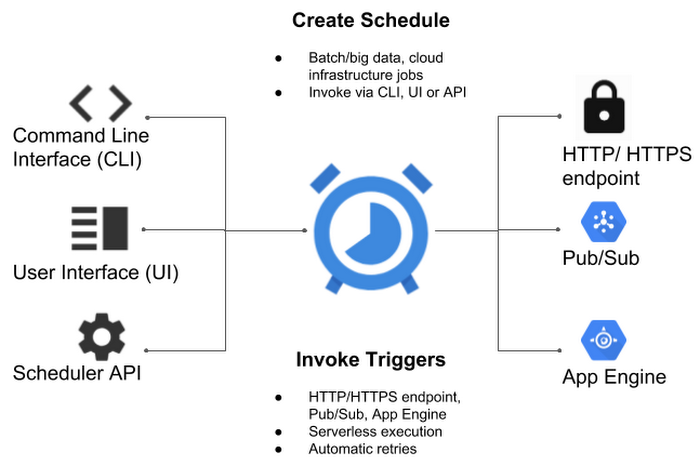
Google Cloudに、バッチジョブを動かすためのマネージドcronサービスが登場する。そのサービスはCloud Schedulerと呼ばれ、たぶんあなたが悪戦苦闘することもあるコマンドラインの標準コマンドcronの、すべての機能を提供するが、クラウドで動かすマネージドサービスとしての信頼性と使いやすさも兼備している。
Cloud Schedulerのジョブのターゲットは、すべてのHTTP/SエンドポイントとGoogle自身のCloud Pub/Subトピック、そしてApp Engineのアプリケーションだ。デベロッパーはこれらのジョブを、Google Cloud ConsoleのUIやコマンドラインインタフェイス、あるいはAPIから管理できる。
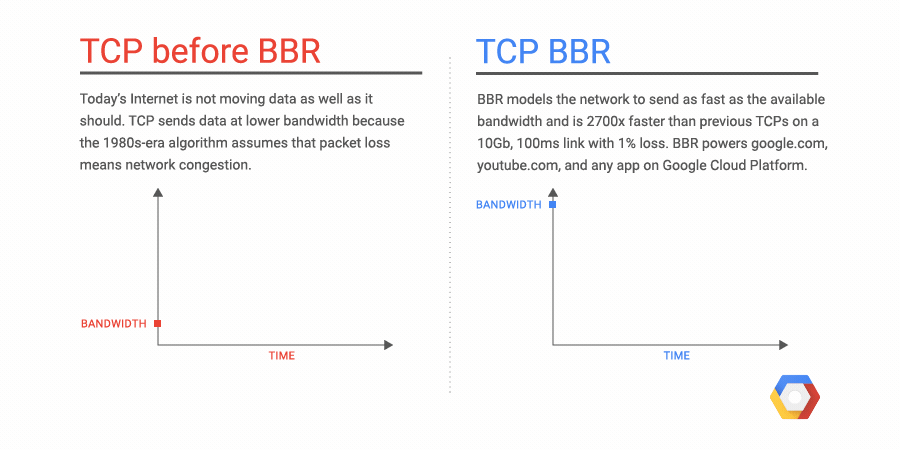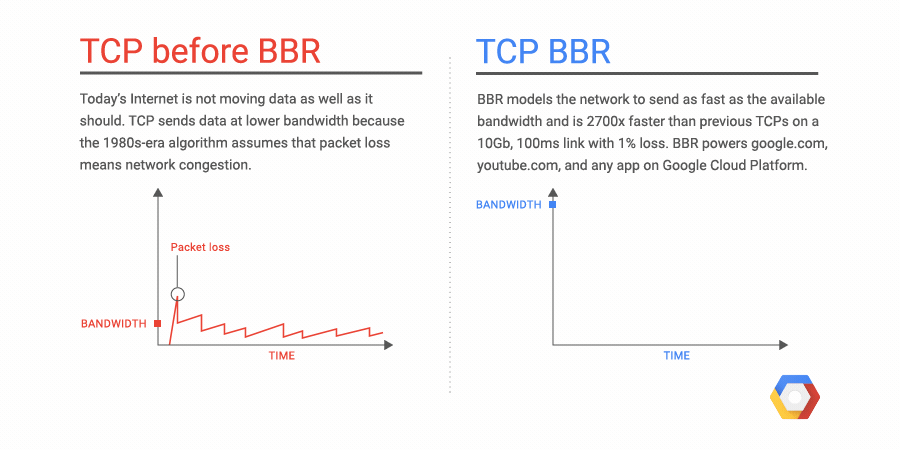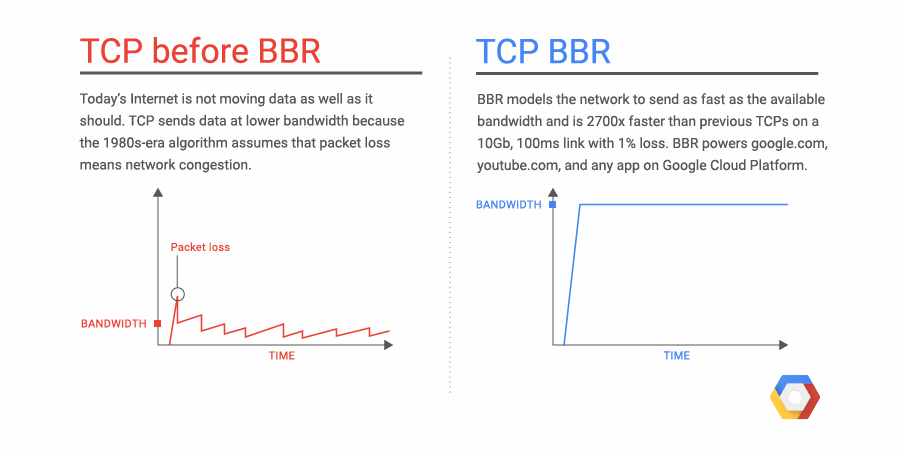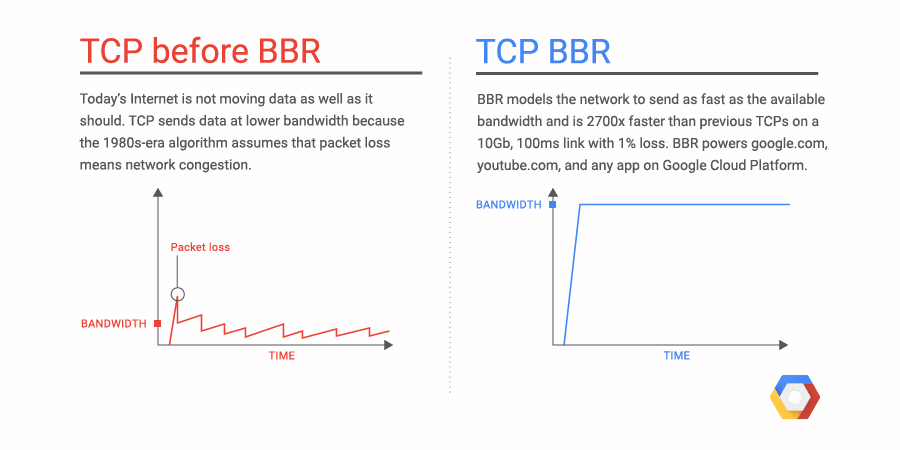
GoogleのプロダクトマネージャーVinod Ramachandranが、今日(米国時間11/6)の発表声明でこう説明している: “cronのようなジョブスケジューラーはどんなデベロッパーの道具箱の中でも主役級の存在で、タスクのスケジューリングやシステムメンテナンスの自動化を助けている。しかしジョブスケジューラーにも、そのほかの従来的なITサービスと同じ課題がある。つまりインフラを自分で管理しなければならないし、失敗したジョブはいちいちマニュアル(手作業)でリスタートしなければならない、そして、ジョブのステータスを目で見ることができない”。
Ramachandranの説明によると、今まだベータのCloud Schedulerは、ジョブをターゲットに確実にデリバリすることを保証する。重要なジョブは確実に始動し、ジョブをAppEngineやPub/Subに送るとサクセスコードやエラーコードが返される。そして同社が強調するのは、何かがおかしくなったらCloud Schedulerに容易にリスタートさせられることだ。
もちろんこのコンセプトはGoogleが初めてではない。同様のサービスを提供しているスタートアップも数社あるし、またGoogleのコンペティターであるMicrosoftにも、同様のサービスがある。
料金は、1か月に3ジョブまでは無料、その先は1ジョブごとに月額10セントだ。