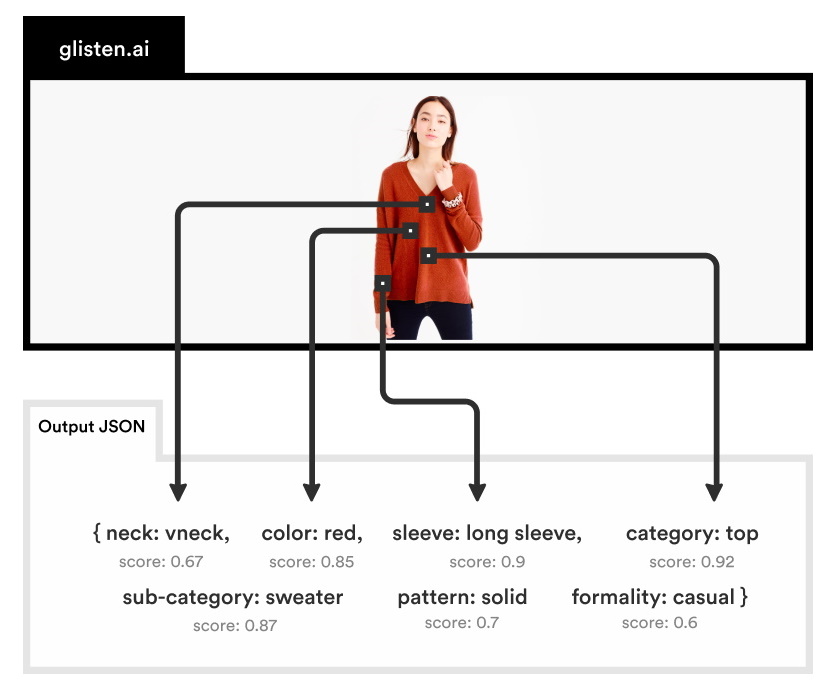
「組み立て作業」と聞けば製造プロセスでの単純な過程を思わせるかもしれないが、組み立て式家具を購入したことがある読者なら、これがいかに腹立たしく複雑な作業になり得るかお分かりだろう。Invisible AIはコンピュータービジョンを用いて、明らかな危険を回避し、安全性と効率性を維持するため、組み立て作業を行う人々をモニターすることを目的としたスタートアップだ。同社は360万ドル(約3億8000万円)のシードラウンドを活用してこの目的を達成する予定である。
Invisible AIは、高度に最適化されたコンピュータービジョンアルゴリズムを用いてカメラに映る人々の動きを追跡する、内蔵型のカメラコンピューターユニットを製造している。作業員の動きを模範的な動き(作業が正しく実行されている場合の様子)と比較することにより、システムがミスを監視したり、不足パーツや怪我などワークフローにおける問題を特定したりすることができる。
このシステムは一見どうみても、労働者が絶えず上昇し続ける人工的な基準を満たせない場合、それを逐一罰するコンピューターの皮を被った冷酷な監督のようなもののように感じられる。おそらくAmazonはすでに採用しているだろう。しかし、共同創設者兼CEOのEric Danziger(エリック・ダンジガー)氏は、そういった意図はまったくないと説明する。
「この製品の最も重要なポイントは、これが作業者自身のために作られたものだということです。これらの労働には熟練した技術が必要とされ、彼らは仕事に対して大きな誇りを持っています。最前線で仕事をしているのは彼らであり、ミスを見つけて修正することはとても重要な部分です」。
「こういった組み立て作業は、かなり肉体的でペースの速い労働です。15ステップを記憶し、その後場合によってはまったく異なるバリエーションのタスクへ進まなければなりません。すべての工程を頭に入れていなければならずとても難しい仕事です」とダンジガー氏は続ける。「目標はリアルタイムでその流れの一部になるということです。作業者が次のパーツに移る際に、同製品が再確認をして『ステップ8をとばしていますよ』という具合に伝えることができる。これにより多大な苦労を回避することが可能です。たとえケーブルを差し込むという程度のことでも、そこでミスを防げるというのは偉大です。車両がすでに組み立てられた後でミスを見つけた場合、再度分解する必要があるのですから」。
このような動作追跡システムは、それぞれ異なる目的のためにさまざまな形で存在する。たとえばVeo Roboticsは、深度センサーを使用して作業員とロボットの正確な位置を追跡し、動的に衝突を防止している。
しかし、この産業全体での課題は「人の動きをどう追跡するか」ではなく「人の動きを追跡した結果をどのようにして簡単に展開し適用するか」である。システムの導入に1か月、再プログラムに数日かかっていては意味がないのだ。そのためInvisible AIは、コーディングの必要がなく完全にエッジベースのコンピュータービジョンを使用して、導入と管理の簡素化に重点を置いた。
「可能な限り簡単に展開できるようにするのが目標でした。コンピューティングやすべてが組み込まれたカメラを購入し、それを施設に設置し、プロセスのいくつかの例を示してから注釈を付けるだけです。想像されるよりもずっと簡単です」とダンジガー氏。「1時間足らずで稼働を開始できます」。

カメラと機械学習システムをセットアップしたら、そこからはそれほど難しい問題ではない。人間の動きを追跡する機能は、最近のスマートカメラにとってかなり簡単な作業であり、それらの動きをサンプルセットと比較することも比較的簡単だ。動画のキャプション付けや手話の解釈に特化したAIで見られるような(どちらもまだ研究コミュニティーで開発途中である)、人が何をしているのかを推測したり、ジェスチャーの膨大なライブラリーに一致させたりするなどの「創造性」は必要ない。
プライバシーに対する課題や、カメラに常時映っているという事実に不安を感じるなどの可能性については、このテクノロジーを使用する企業がしっかりと対応する必要がある。ほとんどの新しいテクノロジーと同じく、善となる可能性と同様に悪となる可能性も備えている。
Invisible AIを早い段階でパートナーとした企業の1つはトヨタだ。トヨタはアーリーアダプターではあるが、同時にAIと自動化に関して慎重派である。複数の実験の後に到達した同社の哲学は、専門労働者に力を与える、というものだ。このようなツールは、労働者らがすでに行っていることに基づき、体系的な改善を提供する良い機会である。

非情なまでの最適化のため、労働者が非人間的な割り当てを満たすように強いられるAmazonの倉庫のような場所にこのシステムが導入されるというのは簡単に想像がつく。しかしダンジガー氏によると、すでに同社と協同している企業の話では労働者自身による作業改善を促す結果となっているとのことだ。
何年もの間、来る日も来る日も製品を作り続けている従業員は正しい製造方法について深い専門的知識を持っているが、その知識を正確に伝えるのは難しい場合がある。「ボルトで締める際に自分の肘が邪魔にならないよう、こうやってパーツを持つように」とトレーニングで指示するのは簡単だが、それを身につけるのは一筋縄ではいかない。Invisible AIの姿勢と位置の検出機能は、そういったことに役立てることができる。
「個人の一連の作業に要する時間にフォーカスするのではなく、ステップの合理化や反復ストレスの回避などが見られています」とダンジガー氏。
重要なポイントは、この種の機能が、結果を送信するためのイントラネット以外に接続を必要としないコードフリーのコンパクトなデバイスで提供できるということだ。分析するためにビデオをクラウドにストリーミングする必要はなく、必要に応じてフッテージとメタデータの両方を完全にオンプレミスで保持することが可能だ。
世間の魅力的な新テクノロジーと同様に不正使用される可能性も幾分あるが、Clearview AIのような取り組みとは異なり、同製品は悪用を目的として作られたものではない。
「そこには微妙な境界線があります。同製品を導入する企業の性質を反映するでしょう」とダンジガー氏は言う。「弊社とやり取りする企業は、従業員を本当に大切にしており、彼らができるだけ尊重され、プロセスに関与することを望んでいます。そういった事には大いに役立ちます」。
360万ドル(約3億8000万円)のシードラウンドは8VCが主導し、iRobot Corporation、K9 Ventures、Sierra Ventures、Slow Venturesなどの投資家が参加している。
Category:人工知能・AI
Tags:コンピュータービジョン 機械学習 Invisible AI
[原文へ]
(翻訳:Dragonfly)