
昨日サンフランシスコで開催されたハードウェアの発表イベントで、Alphabetは、更に幅広く消費者の個人データ(それも、これまで以上に個人的な性質の情報の)収集に向かう野心を表明した。この先コンピューティングが静的なデスクトップやスクリーンを離れ、相互結合したデバイスのクラウドと合体し、更なるデータの生成に向かう動きを加速するためである。
新しい2種類の「Googleデザイン」旗艦Androidスマートフォン(Pixel)と共に、同社のAIアシスタント(Google Assistant)が最初からインストールされたAndroid、そしてユーザーの写真とビデオをGoogleのクラウドに吸い上げる容量無限のクラウドストレージも提供され、また厄介な家庭内のインターネット接続をすべて引き受けるGoogle Wifiルーターもある; Google Homeは常に接続されたスピーカーを通して耳を澄ましていて、Google Assistantを介して声で制御され、またサードパーティ製のIoT機器(たとえばフィリップスのHue電球)を制限付きだがサポートする;新しくなったChromecast(Ultra)は任意の古いTVパネルをインターネット利用可なものにする;そして、Googleの使い捨てではない携帯VR再生機、別名ソフトタッチDaydream Viewヘッドセット がある ‐ 万一消費者の目がデータ収集型スマートホームの外へさまよい出たいと思ったときに、逃げ込むための仮想現実を提供するために。
GoogleブランドのためにAlphabetが描く野望は明快だ:Googleの情報整理頭脳を家庭の中心に埋め込みたいのだ ‐ すなわち、消費者たちにとって高度な個人データを定常的にそこに流し込まない選択肢を選ぶことが不可能になるということだ(もちろん、Google Homeにはミュートボタンがついている、実際にはそれが音量を喋ることを止めるためにボタンを押す必要があるが…)。
言い換えれば、あなたの日々の活動が、Googleの活動そのものなのだ。
「私たちはモバイルファーストの世界からAIファーストの世界に移りつつあります」と、昨日のイベントのキックオフでCEOのサンダー・ピチャイは語った。そしてAIは、もちろん、これまでの技術が持っていなかったようなデータへの食欲を持っている。機械学習は、自身の有用性を手に入れるために情報を必要とする。手探りでは機能できない、データ駆動型の領域なのだ。
よってAlphabetのハードウェアのためのビジョン「Made by Google」は、消費者たちに対して利便性の誓いを販売することである。そして、全てを接続するデバイスと共にこの販売ピッチが、パーソナルスペースをユーザー情報データベースへと変容させ、この先何十年にも渡って広告エンジンに燃料を供給し続けることが可能になるのだ。

デジタル消費者の大部分の問い合わせと好奇心が1つのGoogleブランド検索エンジンに注ぎ込まれるようになったとき、私たちは現代の情報社会のはるか奥深くに入り込んでしまったことになる。このため、Alphabet(以前はGoogleのブランド名を身に着けていた)はとても長く険しい道をAndoridを広くそして深く普及させるために突き進み、電話を超えて幅広いハードウェアの世界にたどり着いたのだ。
そして今、Alphabetはそのプロセスを、よりシンプルなデスクトップウェブの時代と同様に、Googleを手放し難くすためのAI駆動の消費者向けサービス層を用いて、加速しようとしている。
ということで、昨日の大規模なコネクテッドハードウェアのお披露目大会は、実際には、IoT時代に向けて、Googleブランドを頼りになるキーワードとして再活性化し、位置付けの再確認を行わせるためのものでもあったのだ。
特に、AmazonのAlexaやAppleのSiriといったライバル仮想アシスタント技術とは異なり、Alphabetはしっかりと消費者向けのAI界面の端にGoogleブランド名を保持している。そのスマートホームやAIアシスタントを購入した者に、Googleブランド名を文字通り、毎日毎時間声で与えることを要求するのだ。
「OK Google、子供の寝室のライトを消して…」
うーん。
個人的にはそれだけで十分不愉快だ。しかし本当の意味で「not OK, Google」なのは、急速に浮かび上がってきたプライバシーに関するトレードオフなのだ。そしてアルファベットが、こうした懸念を無視していくやりかたも。
「私たちは、あなたが身の回りの仕事を片付けることのお手伝いをしたい」というのが、Googleブランドのスマートホーム、そしてGoogle AI一般についてのピチャイのピッチだった。
「誰でも、何処でも役に立てることのできるパーソナルGoogleを構築することに私たちは興奮しています」というのが、なりふり構わぬAIへの突進に話を添える、彼のまた別のマーケティングフレーズだ。
その通り – 彼は文字通り、このように言っている…
彼が言っていないことの方がはるかに興味深い。すなわち、お好みのレストランを予測したり、通勤経路上の支障がどのようなものかを尋ねたりできるような「カスタムな利便性」の約束を果すためには、あなたの個人情報、嗜好、嗜癖、ちょっとした過ち、偏見…そうしたことを限りなく収集し、データマイニングを継続的に行うことになるのだ。
AIが、データの要求を止めることはない。気まぐれな人間が関心を失いがちな点である。
なので、「誰でも、何処でも役に立てることのできるパーソナルGoogle」構築の対価は、実際には「誰でも、何処でもプライバシーゼロ」ということなのだ。
なので、「誰でも、何処でも役に立てることのできるパーソナルGoogle」構築の対価は、実際には「誰でも、何処でもプライバシーゼロ」ということなのだ。
さてそう考えると「OK, Google」という言葉も、それほどOKには響かないような気がしてこないだろうか。
(同僚の1人が以前、Google Assistantの前身であるGoogle Nowをオフしたきっかけを語ってくれた。彼が日曜の夜に時々行くバーへの到着時刻を、頼まないのに教えてくるようになったからだ。彼はこう付け加えたそうだ「おまえにそんなことまで知っていて欲しくない」)。
なので私たちは、ピチャイの「パーソナルGoogle」ピッチの中にセキュリティとプライバシーに関する言及が全く無かったということに驚くべきではないし、消費者がハードウェアと引き換えにプライバシー(と現金を)渡す際に、彼らが実は決心しなければならない巨大なトレードオフについてGoogleが説明し損なったことを見逃すべきではない。
徐々に親密な関係をGoogleとの間に築いていくこととの引き換えに、消費者が期待する巨大な「利便性」に関しては、まだほんのわずかの実体しかない。
「まだほんの初期段階ですが、全てが一体として動作したときに、Google Assistantはあなたが仕事をやり遂げるお手伝いをすることができるようになります。必要な情報を、必要なときに、どこにいたとしても、取り寄せることができるのです」とピチャイは書いている。頼りにならない曖昧な約束ランキングとしては高得点をつけるに違いない。
彼は「次の10年の間に、ユーザーに対して驚くようなことを提供できる」ことに関しては「自信がある」と付け加えた。
言い換えればこうだ、あなたのデータの扱いに関しては私たちを全面的に信頼して欲しい!
ううーん。 …
今週EFFも、いかにAIがユーザーのプライバシーと衝突するかについてGoogleを非難している、特に最近のプロダクトAlloメッセージングアプリがその対象だ。そのアプリにはGoogle Assistantも組み込まれていて、ディフォルトでAlloはAIを利用するので、アプリはエンドツーエンドの暗号化をディフォルトでは提供しない。単なるオプションとして提供されるだけだ。この理由は勿論、Google AIがあなたのメッセージを読むことができなければ、Google AIは機能することができないからだ。
Alloがエンドツーエンドの暗号化を「めだたない」ところに押し込んでいるやり方が批判の対象になっていて、EFFはそれをユーザーを混乱させ、機密データの漏洩に繋がるものではと考えている。そしてGoogleを「ユーザーに対して暗号化というものは、たまに使えばいいものだという考えを植え付ける」として非難しているのだ ‐ そしてこのように結論付けている:「より責任あるメッセージングアプリは、機械学習とAIではなく、セキュリティとプライバシーがディフォルトであるべきである」。
さて、それがGoogle HomeなのかGoogle Alloなのかはともかく、Googleは消費者たちに比類なく便利なAI駆動の魔法体験を約束している。しかしそのためには厳しい問いに答えなければならない。
このアドテックの巨人は、そのプロダクト体験を支配してきたように、物語を支配しようと努力している。GoogleのCEOは「驚くべきこと」がパイプを下って、皆がGoogleを信頼しデータを委ねる世界にやってくると語っただけで、小説1984のビッグブラザー(監視機能を備えたAI)の世界に迫っていると言ったわけではないが、Googleのプロダクトは同じくらい不誠実なものだ;ユーザーにより多くを共有させ、より考えることを減らすことを促すようにデザインされているという意味で。
そして、それは本当に責任ある態度とは逆のものだ。
だからノー。Not OK Google。
[ 原文へ ]
(翻訳:Sako)













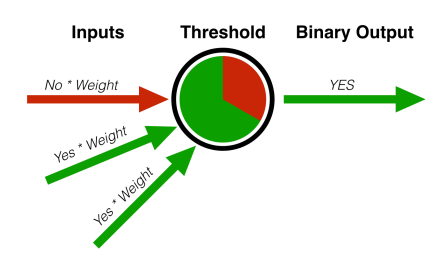
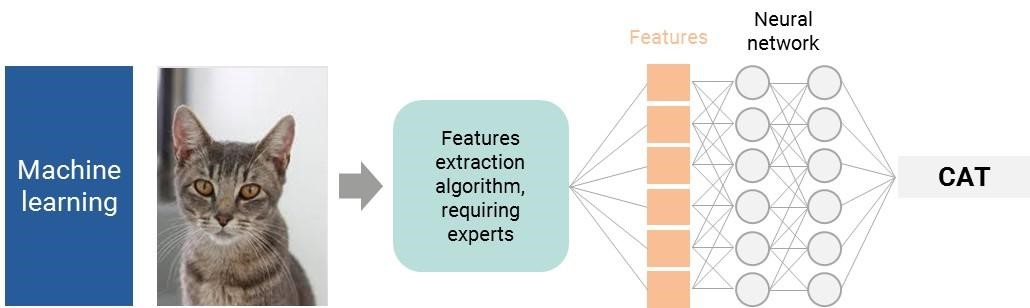
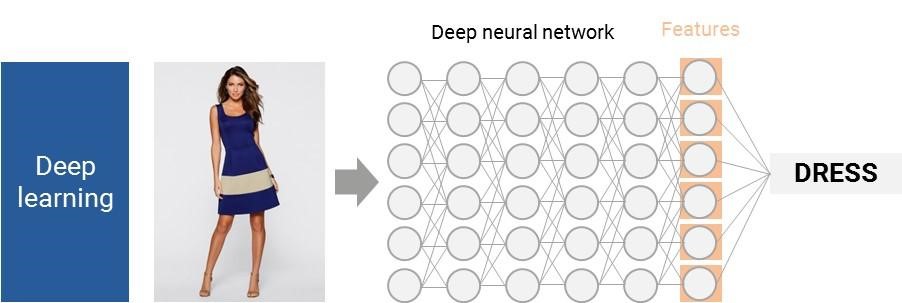
 パーセプトロンは、機械学習の分野で行われた多くの初期の進歩の、ほんの1例に過ぎない。ニューラルネットワークは、協力して働くパーセプトロンの大きな集まりのようなものである。私たちの脳や神経の働き方により似通っていて、それが名前の由来にもなっている。
パーセプトロンは、機械学習の分野で行われた多くの初期の進歩の、ほんの1例に過ぎない。ニューラルネットワークは、協力して働くパーセプトロンの大きな集まりのようなものである。私たちの脳や神経の働き方により似通っていて、それが名前の由来にもなっている。














{kind=link}
{kind=link}
{kind=link}