(日本語版注:本稿は、Jocelyn GoldfeinとIvy Nguyenにより執筆された記事。Jocelyn GoldfeinはZetta Venture Partnersの業務執行取締役。 Ivy Nguyenは、Zetta Venture Partnersの共同経営者。)
ソフトウエアの開発が以前に比べて簡単になったことで、ソフトウエア・ビジネスにおいて身を守ることは、以前よりも難しくなっている。そのため、投資家や企業家が、データに新しい競争力の可能性があると楽観視するのは不思議ではない。データは「新しい石油だ」と称賛する人間もいる。私たちは、ビジネスに関する問題を解決してくれるデータやAIを活用するスタートアップへの投資に力を入れているため、たしかに、そうした声を聞くわけだが、石油に例えるのは少し違うと思う。
ビッグデータへの関心は非常に高いが、すべてのデータが同等に作られているわけではないという事実は見落とされがちだ。スタートアップも大手企業も、口を揃えて、テラバイト級だとか、米国議会図書館に収められている情報より多くのデータを保有しているとか、自分たちが集積したデータの量を自慢するが、量だけで「データモート」(Data Moat:データの堀)を築くことはできない。

データ戦略の変遷 左から「ワークフロー・ツール(データなし)」「データ集約」「データ駆動型好循環(AI / ML)」「データモート」
その理由のひとつには、生のデータは、問題解決に利用できるデータと比べて価値が遙かに劣るということがある。それは、公開市場を見るとわかる。ニールセンやアクシオムなどのデータの収拾や提供を業務としている企業は、ネットフリックスやフェイスブックのようにデータをアルゴリズムや機械学習(ML)と組み合わせることで製品を生み出している企業と比較すると、企業評価は数分の一をなんとか維持している程度だ。新しい世代のAI系スタートアップは、その違いをよく心得ていて、収拾したデータから価値を抽出するためのMLモデルを採用している。
MLベースのソリューションにデータが利用できたとしても、そのデータセットのサイズはまた別の話だ。データセットの価値、つまりデータモートの強さは、文脈による。アプリケーションによっては、顧客に何らかの価値を提供するために、非常な高精度にトレーニングしたモデルを必要とするものがあるかと思えば、ほんの僅かなデータ、あるいはまったくデータを必要としない場合もある。独占的に所持できるデータもあれば、すでに複製されているデータもある。時間とともに価値が失われるデータもあれば、永久に価値を保ち続けるデータセットもある。アプリケーションがデータの価値を決定するのだ。
「データ欲」の範囲を規定する
エンドユーザーに価値ある機能を提供するためには、MLアプリケーションは、幅広く大量のデータを必要とする。
MAP閾値
クラウドの分野には、実用最小限の製品(MVP)という考え方が根付いている。初期顧客を探し出すのに必要な機能だけを備えたソフトウエア郡だ。インテリジェンスの分野では、私たちはデータやモデルから見られるアナログの部分に注目している。採用を正当とするに足る最小限の精度を持つ情報だ。これを私たちは最低限のアルゴリズム性能(MAP)と呼んでいる。
ほとんどの場合、アプリケーションで価値を生みだすのに必要な精度は、100パーセントでなくてもよい。たとえば、医師のための生産性向上ツールがあったとしよう。最初は、健康状態を電子的に記録するシステムのデータ入力を補助する役割を果たすが、時が経つにつれて、どの医師がシステムに入っているかを学習して、データ入力を自動化するようになる。ここではMAPはゼロだ。使い始めた最初の日から、そのソフトウエアの機能が価値を発揮するからだ。インテリジェンスは後から付加される。しかし、AIが中心になっている製品(たとえば、CTスキャナーから脳卒中を特定するツール)の場合は、生身の人間が行うときと同等精度のソリューションが求められる。MAPは人間の放射線科医の能力と同等になり、製品として成立させるまでには、恐ろしいほど大量のデータが必要とされる。
成績の閾値
100パーセントに近い精度があっても、すべての問題が解決できるわけではない。あまりにも複雑すぎるため、最先端の技術を駆使したモデルを必要とする問題もある。その場合は、データは特効薬とはならない。データを増やすことで、モデルの成績は徐々に向上するだろうが、すぐに限界利益の減少に直面してしまう。
反対に、追跡すべき次元が少なく、結果の幅も小さく、比較的単純にモデリングできる問題の場合は、ほんのわずかのトレーングされたデータセットで解決できてしまう。
早い話が、問題を効率的に解決するために必要なデータの量は、状況によって変わるということだ。実用的なレベルの精度に達するために必要なトレーニングされたデータの量を、私たちは「成績の閾値」(Performance Threshold)と呼んでいる。
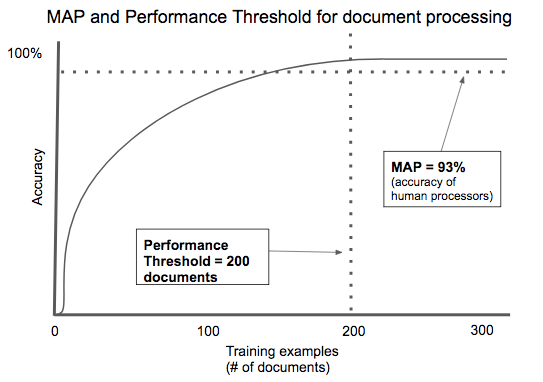
書類処理におけるMAPと成績の閾値の関係 縦軸は精度、横軸はトレーニング用の実例(ドキュメントの数)。 左「成績の閾値=ドキュメント数200」、右「MAP=93%(人間による処理の精度)」
AIを使った契約処理は、成績の閾値が低いアプリケーションのよい例だ。契約書のタイプは何千とあるが、そのほとんどには、契約に関わる人たち、価値を交換するアイテム、期限など、共通する要点がある。住宅ローンやレンタル契約などの書類は、規制に準拠しなければならないため、ほとんど定型化されている。わずか数百種類の例を使ってトレーニングするだけで、実用的な精度に高められる自動文書処理のアルゴリズムを開発したスタートアップを、私たちは数多く見てきた。
起業家にはバランス感覚が必要だ。成績の閾値が高ければ、顧客に使ってもらい、より多くのデータを集めるために、十分なデータを集めなければならないという「ニワトリが先か卵が先か」のような問題に行き当たる。低すぎれば、データモートは築けない。
安定性の閾値
MLモデルは、それが利用されることになる現実の環境から例を集めてトレーニングされる。その環境が少しずつ、または突然に変化したとき、それに伴って変化できなければモデルは陳腐化する。つまり、そのモデルの予測は、もう信頼できないということだ。
たとえば、スタートアップのConstructor.ioは、MLを使って電子商取引サイトの検索結果をランク付けしている。そのシステムは、顧客が検索結果をクリックするかどうかを観察し、そのデータを使って、よりよい検索結果を得るための順番を予測するというものだ。しかし、電子商取引の製品カタログは常に変化している。もしそのモデルが、すべてのクリックのウェイトを同じと考えていたら、または一定の時間のデータセットだけでトレーニングされていたとしたら、古い製品の価値を過大に評価したり、新製品や現在人気の製品をそこから除外してしまったりする恐れが出てくる。
モデルの安定性を保ちたいなら、環境の変化の速度に合わせて最新のトレーニングデータを取り込む必要がある。私たちは、このデータ取得の速度を「安定性の閾値」と呼んでいる。
短命なデータでは強固なデータモートは作れない。一方、安定性の閾値が低い場合、豊富で新鮮なデータへの継続的なアクセスは、大きな参入障壁になってしまう。
長期的な防御力で好機を見極める
MAP、成績の閾値、安定性の閾値は、強固なデータモートを築く際に中核となる要素だ。
新しいカテゴリーに飛び込む先行者には、MAPが低い企業があるが、ひとたびカテゴリーを確立して、そこを牽引するようになれば、後から参入する者たちの敷居は、先行者のときと同じか、それよりも高くなる。
成績の閾値に達するまでに必要なデータと、成績を維持するため(安定性の閾値)に必要なデータの量が少なくて済む分野では、防御が難しい。新規参入者はすでに十分なデータを持っているので、先行者のソリューションに簡単に追いついたり、追い越したりできてしまう。その一方で、成績の閾値(大量のデータを必要としない)と低い安定性の閾値(データが急速に古くなる)と戦っている企業でも、他の企業よりも早く新しいデータを取得できれば、データモートを築ける可能性がある。
強固なデータモートのその他の要素
AI系の投資家は、データセットは「公開データ」と「独自データ」に分けられると熱弁するが、データモートには、それとは別に次の要素がある。
- アクセスのしやすさ
- 時間 — どれだけ早くデータを収集してモデルに活かせるか。データには即座にアクセスできるか、または取得や処理に長い時間がかからないか。
- コスト — そのデータを入手するのに、いくらかかるのか。データを使用するユーザーがライセンス権のために金を払う必要があるのか。または、データのラベリングのために人件費を払う必要があるのか。
- 独自性 — 同じ結果を導き出すモデルが構築できる同等のデータが広く公開されていないか。そのような、いわゆる独自データは、「日用データ」(Commodity Data)と呼ぶべきだろう。たとえば、求人情報や、広く普及している形式の書類(機密保持契約書やローンの申請書など)や、人の顔の画像のようなものがそれにあたる。
- 次元性 — データセットの中に、種類の異なる属性がどれほど含まれているか。その多くが、問題解決に役立つものであるか。
- 幅 ― 属性の価値がどれほど多岐に渡っているか。そのデータセットに、極端な事例や稀な例外的事例が含まれているか。データまたは学習が、たった一人の顧客から得たものではなく、幅広い顧客層から収拾され蓄えられているか。
- 寿命 ― そのデータは、長期にわたって幅広く利用できるものであるか。そのデータでトレーニングされたモデルは、長期間使えるか。または、定期的な更新が必要か。
- 好循環 ― 性能のフィードバックや予測の精度といった結果を、アルゴリズムの改良のためのインプットとして使えるか。時を経るごとに性能が磨かれてゆくか。
今やソフトウェアは日用品だ。長期間にわたって競争での優位性を保ちたいと考える企業にとって、データモートの構築はますます重要になる。技術系の巨大企業がクラウド・コンピューティングの顧客を獲得するためにAIツールキットを無料公開する世の中では、データセットは、差別化のための非常に重要な決め手となる。本当に防衛力の高いデータモートは、データを大量に集めるだけでは実現しない。最良のデータモートは、特定の問題分野と強く結びついている。そこでは、顧客の問題を解決するごとに、他所にはない新鮮なデータが価値を生み出すようになる。
[原文へ]
(翻訳: Tetsuo Kanai)