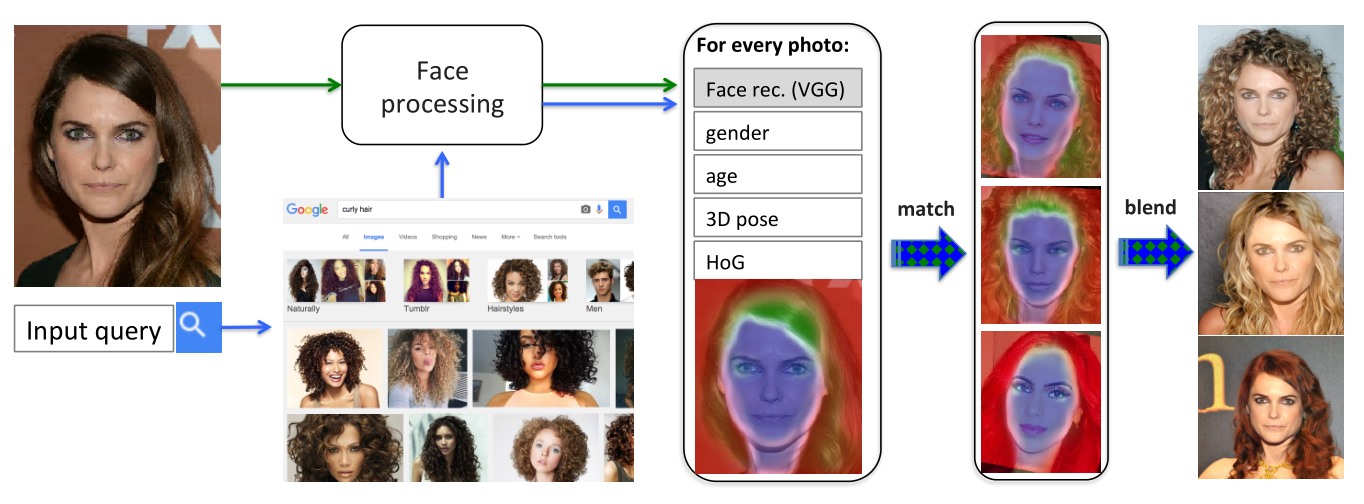
今月、Uberの自動運転車が路上デビューする。予想よりも早かった。これは楽しみなサプライズだ…あなたがドライバーでなければ。ロボットに起因する失業問題は、いずれ他の業界にも波及するだろう。
100万人のUberドライバーはどうなるのか? 全米350万人のトラックドライバーは?そして、世界中でバスやタクシーを走らせている無数のドライバーたちは?
そういう仕事が一夜にしてなくなることはない。20年はかかるだろう。しかし、こうした労働環境変化への備えができなければ、たとえ多くの人々に利便を提供したとしても、一部の人々に苦難を強いることになる。

自動運転車が〈未来〉であることに疑いはない。何といっても安全だしリラックスできる。交通量を削減し、炭素排出量を削減する。そして、運転席で費やされていた知識労働者の時間を、生産的な時間へと振り向ける。
しかも車を走らせるための人件費より、ずっと安くつく。
Bloombergが次のように書いている。「通常料金の1マイル当たり1.30ドルが今は無料だ。将来的にも、[Uber CEOのTravis ]Kalanickによると、料金は低く抑えられる予定だという。それは郊外の長距離ドライブでさえも、1マイルあたりのコストは無人Uber車の方が自家用車より安いからだ」。そしてつい最近Uberは、自動運転トラック会社を買収したことを発表した。
落伍者
問題は、運転というものがレジ係やファーストフードのアルバイトと並ぶ非熟練労働であることだ。そういう仕事には必ずロボットがやってくる。テクノロジーは職を失う人たちに新しい仕事をもたらす、と言う意見もある。しかしその新しい仕事が、熟練を要さない仕事を失った人々によってなされる可能性は低い。
こう考えてみてほしい。自動車が発明された時、それまで人や物資を運んでいた低熟練労働者たちは脅かされた― 馬である。下のビデオを見れば、「より良いテクノロジーは、より良い仕事を馬に与える」という考えが滑稽であることがわかるだろう。「馬」を「人間」に置き換えても楽観的にはなれない。
こうした自動化へのシフトが経済にどう影響を及ぼすのか。置き換えられた低熟練労働者の収入は、自動運転車や料理ロボットやロボットレジ係のオーナーやデザイナーの手に渡る。これはマルクス主義者の悪夢だ。
ソフトウェアはすでに似たような現象を起こしているが、自律ロボットが増殖すれば、この革命はビットを越えて、原子の世界に侵略してくる。
次期大統領が今から国民に準備をさせ始める必要があるのはそのためだ ― できればイノベーションのスピードを損なうことなく。教育、職業訓練、就職支援サービスの充実は不可欠だ。いや、問題を認識して話題にするだけでもスタートとしては悪くない。
長期的には、テクノロジーが仕事を生み出すより、テクノロジーが仕事を取って代わる方が早い時代に、資本主義がいかに機能するかをじっくり厳しく見つめなおす必要がある。全員にフルタイムの役割が必要なのか?非効率や不況に陥ることなく、頂点の富を再分配して底辺を飢えさせないようにできるのか? 市民の感情というものは、どれだけパンを与えられたかではなく、どれだけ稼ぎだしたかに価値を見いだすものだろう。
これは決まった答えのない複雑な問題だ。答を見つけるためには膨大な時間が必要だ。しかし今日Uberは、その〈未来〉の到着時刻が予定よりずっと早まったことをはっきりと示した。