Microsoft(マイクロソフト)は米国時間8月25日、Microsoft 365の利用者全般に向けた新しい音声文字起こしサービス「Transcribe in Word(トランスクライブ・イン・ワード)」を開始(Microsoftブログ)したことを発表した。現在、この機能は、Word(ワード)のオンライン版で使用できる。他のプラットフォーム用のものは、後日追加される。さらに、新しい音声認識機能もWordに追加された。例えば、文章のフォーマット調整や編集が声でできるようになる。
その名前が示すとおり、この新機能は会話を文字に変換してくれる。その場で話した会話にも、録音にも対応し、聞き取った文章はそのままWord上で編集が可能だ。これにより、MicrosoftはOtter(オター)などのスタートアップやGoogle(グーグル)のレコーダーアプリと競合することになるが、どれにも一長一短がある。
画像クレジット:Microsoft
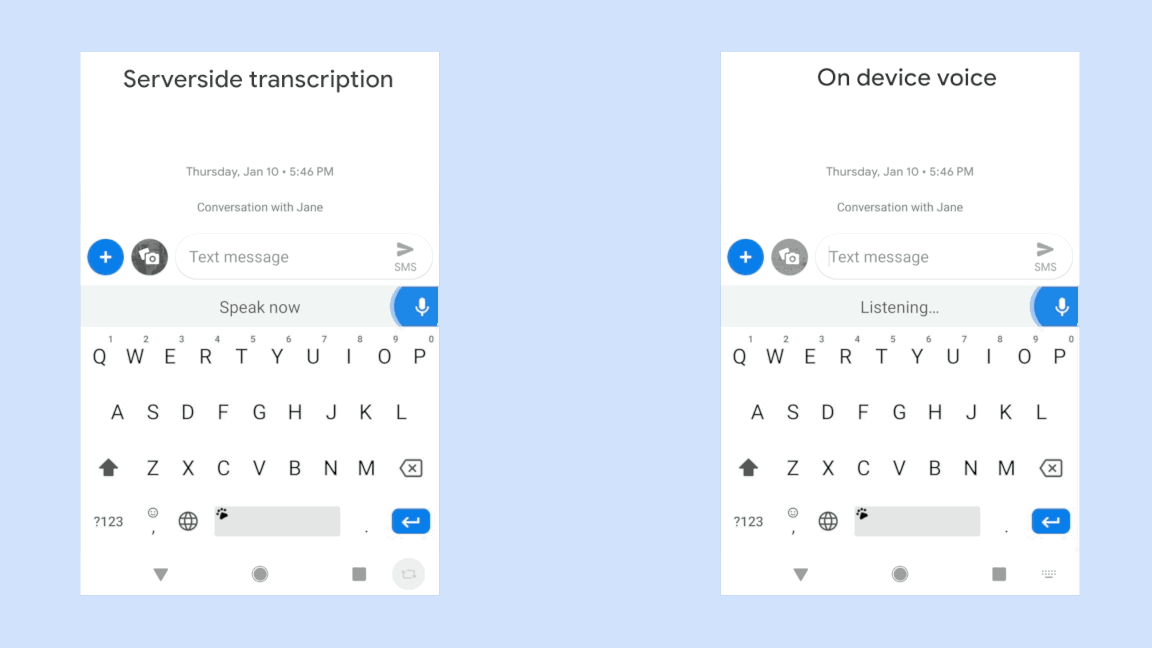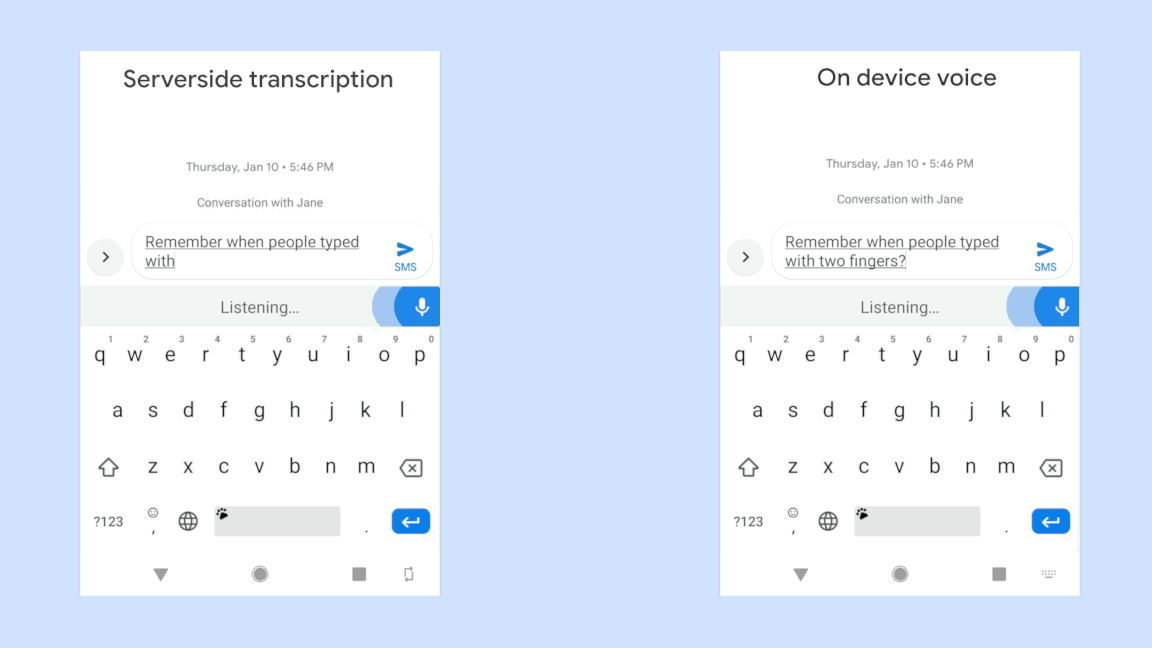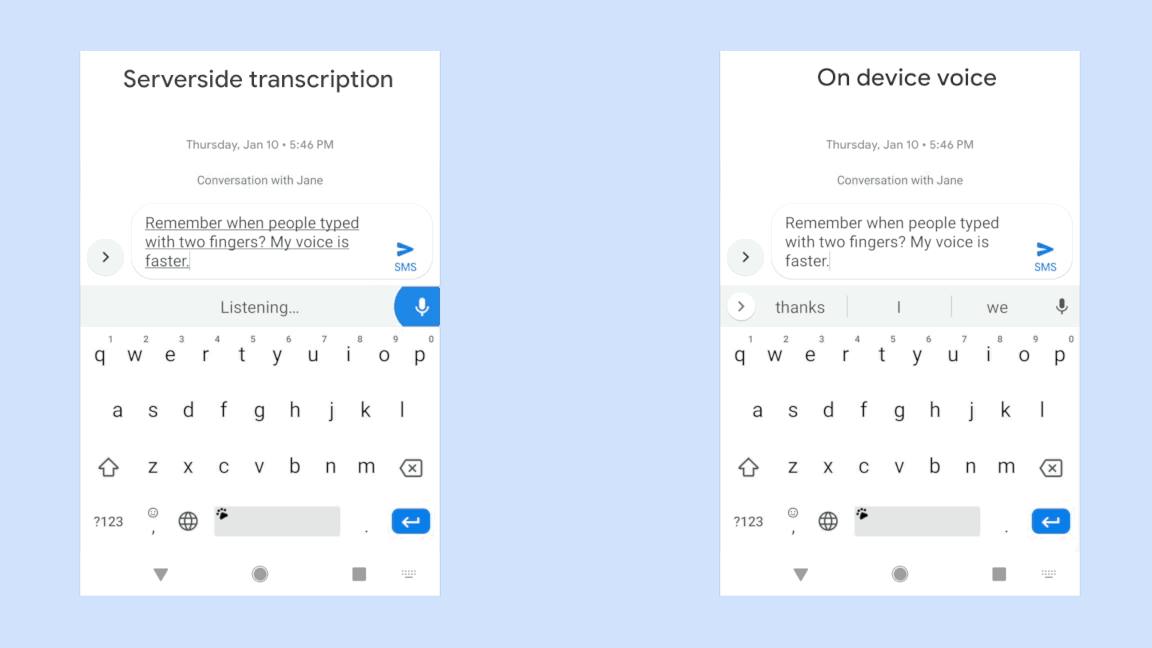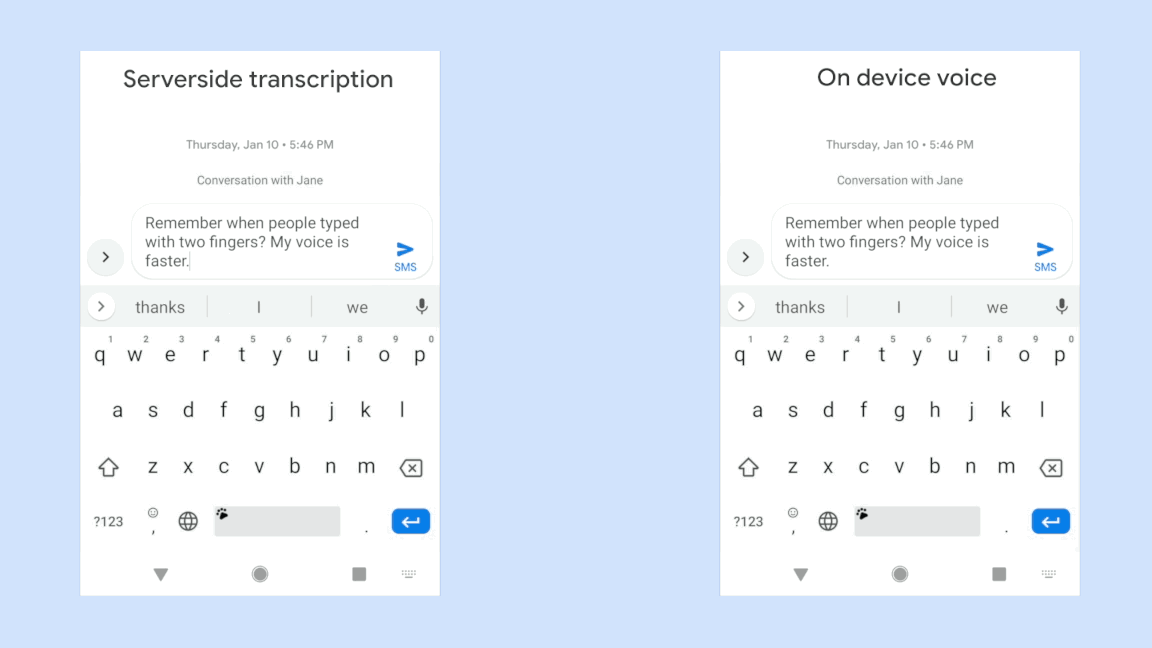
Transcribe in Wordを使うためには、メニューバーの「Dictate」ボタンをクリックし、続けて「Transcribe」をクリックするだけだ。後は、そこで交わされる会話が録音される。例えばスピーカーフォンやノートパソコンのマイクから直接録音できるが、別の方法で録音してからファイルを読み込ませることも可能だ。対応ファイル形式はmp3、wav、m4a、mp4となっている。
マイクロソフトのNatural User Interface & Incubation部門の主席グループPMマネージャーであるDan Parish(ダン・パリシュ)氏は本日の発表に先立つ記者会見で、例えば電話の音声を生で録音するとき、インタビュー中にバックグラウンドで書き起こしが行われると話していた。彼らは、その場で書き起こした文章は、あえて表示させないように決めたという。ユーザーへの調査で、表示させると気が散ると指摘されたからだ。正直にいって、私はOtterやレコーダーがその場で書き起こしてくれるのを見るのが好きなのだが、そんな人間は私だけなのだろう。
他社サービスと同様に、Transcribe in Wordでも書き起こされた文章の段落をクリックすると、いろいろな速度で読み上げさせることができる。自動書き起こしには聞き取りミスが付きものであるため、これは必須機能だ。しかしながら残念なことに、Transcribe in Wordでは個々の単語はクリックできない。
今のところ、このサービス最大の制約は、オフラインで録音した音声ファイルを読み込む際に、長さが300分に限定される点だ。追加料金を払ってこれを延長することもできない。私は、月あたり5時間以上のインタビューを書き起こすことも少なくない。それを考えるとこの上限は低すぎる。Otterなどは、最も安いプランでも6000分の容量がある。Otterは最大が4時間。それに対してマイクロソフトは読み込むファイルサイズも200MBに制限している。ただし、生で録音する場合は制限がない。
もう1つ私が気づいたのは、誤って録音中のWordのタブを閉じてしまうと、録音が中止されるという問題だ。しかも再開方法がどこにも見つからない。
また、読み込んだ音声ファイルの書き起こしにもかなり時間がかかる。録音した会話と、ほぼ同じぐらいの時間になる。だが、結果は極めて良好だ。競合サービスよりも優れていることも多い。さらにTranscribe for Wordは、会話中に話し手が変わったときに区別する能力にも長けている。ただしプライバシー保護の関係上、いつも同じ人間が録音する場合でも、いちいち自分の名前を登録する必要がある。
OneNote(ワンノート)などにも、同じような機能があったらいいと思う。マイクロソフトはいずれ、同社のメモアプリにもこの機能を追加するだろうと私は考えている。私には、そちらのほうが使い慣れているのだ。

画像クレジット:Microsoft
Wordの新しい音声認識機能は、例えば「最後の文章を太字に」といったコマンドを出したり、「パーセンテージのマーク」や「アンパサント」というように声で記号を入力することが可能になる(Wordでそんなノリの文章を書いている人の場合は「笑った顔」なども入力できる)。
音声の書き起こしはそれほど必要ないという人もいるだろうが、この新機能には、同社のサブスクリプションサービスに新しいプレミアムな機能を追加することで、無料プランのユーザーを有料プランに誘うための役割もある。有料プランのユーザーにより多くの機能を提供しているMicrosoft Editor(エディター)やこの書き起こしサービス、またはExcel(エクセル)やPowerPoint(パワーポイント)に新たに搭載されたAI機能などのツールが、有料プランにユーザーを乗り換えさせる役に立たなかったとしたら、むしろ驚きだ。特に今は、利用者のためにOffice 365をMicrosoft 365に統合したところだ。その結果、Grammarly(グラマリー)とOtter(オター)を個別に契約するほうが、Microsoft 356よりもかなり高額になっている。
画像クレジット:Jeenah Moon/Bloomberg via Getty Images / Getty Images
[原文へ]
(翻訳:金井哲夫)