
編集部:この記事はJohn Ramptonの投稿。 Ramptonはオンライン請求サービス、DueのファウンダーでCRUNCH NETWORKのメンバー。
この筆者にようる過去記事:The broken world of mobile payments and how to fix it, What Zuckerberg And Gates Teaming Up Really Means For Clean Energy In 2016
SEOは完全に違うものになった
将来を見通すという困難な仕事にかかる前に、まずGoogleのサイト評価アルゴリズム、RankBrainがSEOをどう変えたかを考える必要がある。私はカーネギーメロン大学の同窓生で友達のScott Stoufferとこの問題について話し合った。彼は Market Brewの共同ファウンダー、CTOだ。この会社はFortune 500掲載の大企業のSEOチームにランキングのモデルを提供している。検索エンジンの専門家としてStouffer過去10年間に検索エンジンがどう進歩してきた知る絶好の位置にいる。
以下に述べるのは、SEOビジネスにとってGoogleの人工知能がどんな意味を持つかについてのStoufferの意見をベースにしている。
現在の回帰分析には深刻な欠陥がある
SEOビジネスでこれは現在最大の誤謬だろう。Googleのランキング・アルゴリズムが大きく変更されるたびに「それはこういう影響をもたらす」と解説する予言者が大勢現れてきた。誰でも知っているような有名企業のデータサイエンティストやCTOが最新のGoogleアルゴリズムについて「詳しく知る立場にある」と主張する。これはアルゴリズムのアップデート以前のランキング・データを調べ、次にアップデートの内容が適用されたならこれこれの変化があるとあらゆる種類のサイトについて予測するという手法だ。
現在の回帰分析のアプローチでは、データサイエンティストは(良きにつけ悪しきにつけ)ランキング・アルゴリズムに影響を受けるタイプの特定のサイトのグループに着目する。そしてこうしたサイトのランキングの変動はしかじかのアルゴリズムの変更(コンテンツ関連、バックリンク関連、その他)によって引き起こされた可能性が高いと結論する。
ところがGoogleはアルゴリズムのアップデートに当たってもはやこうした考え方を採用していない。 GoogleのRankBrainは極めて強力な機械学習、あるいはディープ・ラーニングのシステムであり、そのアプローチはまったく異なる。
Googleのランキング・アルゴリズムにはコアとなる考え方が存在する。RankBrainはまずこのコア・アルゴリズムを理解し、現実のサイトに適用された場合、どのようなアルゴリズム組み合わせによってベストの検索結果を得られるかを決定する。たとえばRankBrainは、あるタイプのサイトではもっとも重要性の高いシグナルはMETAタグのtitleの内容だと判断する。
META titleの重要性が高いのであれば、ここに検索エンジン向けの記述をすることで検索結果に好影響を与えることができる。しかし常にそうであるとは限らない。別の種類のサイトではtitleタグは検索結果に破壊的な結果をもたらすことがある。
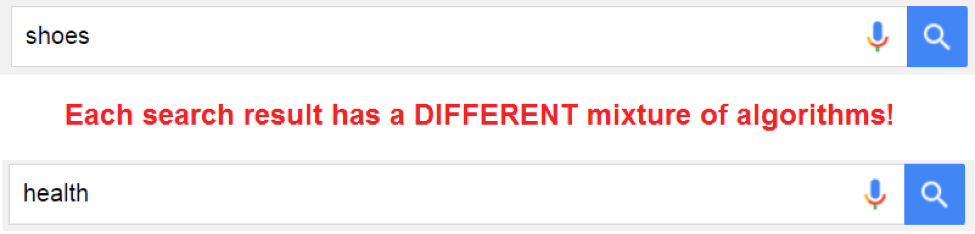
重要なポイントは、それぞれの検索結果はまったく異なるアルゴリズムの組み合わせだということだ。この点に注目すれば、サイトのタイプや検索のコンテキストを無視した単なる回帰分析がいかに深刻な問題をもたらすかがわかるだろう。
つまり回帰分析は個別の検索ごとに行われなければ意味がない。 最近、Stoufferは検索モデル分析というアプローチについて書き、Googleのアルゴリズムの変更は、正しい分析を行えば定量的に確認できると論じた。第一に、過去に特定のキーワードに対する検索結果のスナップショットにもとづき、Googleが検索アルゴリズムルをどのように調整しているはずであるか、モデルを作成して推定する。ランキング決定に変化があった場合、新旧のデータの差異からモデルを再調整し、Googleが検索アルゴリズムにどような変化を加えらたかを明らかにする。 このようなアプローチを採用した場合、ランキング結果の変化がどのアルゴリズムのウェイトの増大あるいは低下によるものであるかを推定できる。
人間が未来を予測するときの誤りは、その意義を過小評価することだ
こうした知識をベースにすれば、われわれは特定の検索に対する体験を改善するためのSEOを始めることができる。ただし同じようなSEOアプローチが他のタイプの検索に対しても適用できると期待してはならない。前にも述べたようにRankBrainは検索結果(つまりキーワードのレベル)に対して最適化されているからだ。RankBrainは文字通りアルゴリズムをカスタマイズしてそれぞれの検索結果を表示している。
分類エラーを防ぐためにはニッチを出るな
Googleはディープ・ラーニング能力を利用してRankBrainに「良いサイト」と「悪いサイト」がどのようなものであるかを教えることができるのを発見した。個々の検索ごとにアルゴリズムをカスタマイズするのと同様、Googleはそれぞれのジャンルのサイトで典型的な「良し悪し」のサインがあることに気づいた。それぞれのジャンルには異なる顧客管理モデル、異なるテンプレート、異なるデータ構造があるのだから適用すべき基準も異なるのは必然的だ。
RankBrainは実行される特定の環境ごとに自らの「正しい設定」を学習する。繰り返しになるが、「正しい設定」はサイトのジャンルごとに異なる。たとえば健康ビジネスではGoogleはWebMD.comは信頼すべき優秀なサイトであることを知っており、検索結果のトップ付近にこのサイトが来るよう検索インデックスが調整されている。そしてWebMDに類似、あるいは関連したサイトは「良い」と判断される。同様に健康ビジネスでスパムを乱発しているサイトに類似するサイトは「悪い」と判断される。
RankBrainがディープ・ラーニング機能を利用してジャンルごとに大まかな「良いサイト」と「悪いサイト」という区分を作っているなら、数多くのジャンルの内容を含むサイトを運営している場合、どういうことになるだろう?
まずディープ・ラーニングの仕組みをもう少し詳しく知る必要がある。「良い」と「悪い」という2つの大きなバケツにサイトを分類する前にRankBrainはそれぞれのサイトが「どんなジャンルに分類されるか」を知らねばならない。Nike.comやWebMD.comの場合は簡単だ。これらは大きなサイトなので数多くのサブセクションがある。しかし全体としてNikeはスポーツ用品メーカーであり、 WebMDがヘルス・ビジネスに属することに変わりはない。こうしたサイトは容易に分類可能だ。
しかしサブセクションがそれぞれ異なるジャンルに属するようなサイトの場合はどうだろう? たとえば、ハウツー・サイトなどがよい例だ。こうしたサイトはきわめて広いジャンルのサブセクションを持つことになる。するとディープ・ラーニング・システムは十分に機能できなくなる。こうしたサイトを分類するためにGoogleはどんなトレーニング・データを用いたらよいだろう? あまりにジャンルが広い場合は有効なトレーニング・データを作成することはできない、というのがその答えだ。トレーニング・データは特定のジャンルを前提とする。Wikipediaにように極めて有名なサイトの場合、Googleはディープ・ラーニングによる分類を諦め、サイト自体を対象から除外している。こうした著名なサイトを含めることによってディープ・ラーニング・システムを混乱させることを防止するためだ。Wikipediaについていえば、「大きすぎて〔RankBrainを〕失敗させるわけにいかない」という例だろう。
SEOはきわめて高度なテクノロジー分野となりつつある
しかしWikipediaほど有名でないサイトの場合は話が違ってくる。残念ながらこちらの答えは「そんなことは誰にも分からない」だ。ディープ・ラーニング・プロセスはサイトを同ジャンルの他のサイトを比較する前に、どのジャンルに属するかを決めなければならなないはずだ。そのとき、ハウツー・サイトがたまたまWebMDサイトに酷似していたら、たいへん幸運だ。
しかし、Googleの分類プロセスがそのサイトを「スポーツシューズに関連している」と判断するなら、WebMDではなくNikeのサイトと構造を比較するだろう。もしハウツーサイトが、尊敬すべきWebMDではなく、スパム・サイトとして知られる靴サイトに似ている場合、Googleはこのサイトに「スパム」の烙印を押しかねない。もしハウツー・サイトがジャンルごとに別のドメインに分割されていれば、RankBrainがそれぞれのドメインをそれぞれのジャンルの他のサイトと比較するのは容易になる。つまりこれが「ニッチにとどまれ」という理由だ。
バックリンクにご用心
上に述べたようなジャンルへの分類が行われた後の段階となるが、次にバックリンク(被リンク)の影響について考えてみよう。サイトが「関連あるコミュニティーに留まる」ことの重要性はますます高まっている。RankBrainはジャンルごとの通常のバックリンクのプロフィールを知っており、これと異なるような状態を検知できる。
ある会社が靴のサイトを運営していたとしよう。上で説明したとおり、RankBrainはこのサイトを靴サイトにおける「良いサイト」、「悪いサイト」と比較する。当然ながらバックリンクの内容も「良いサイト」、「悪いサイト」と比較されることになる。
「良い靴サイト」はおそらく次のようなジャンルからのバックリンクを持っているはずだ。
仮に靴会社のSEOチームがこれと違った新しい分野のバックリンク獲得に力を入れ始めたとしよう。 CEOチームの1人が優秀なエンジニアであり、また前職の関連で自動車産業に強かったとする。するとこのチームは「自動車の新規リースで靴を1足、無料進呈」というようなクロス・マーケティング・プロジェクトを始めるかもしれない。このプロモーションが自動車サイトに掲載されれば、靴サイトは大量のバックリンクを獲得できる。うまい話だろうか?
RankBrainは突然バックリンクが増大したことに気づき、他の評判の良い靴サイトのバックリンク・プロフィールとまったく性質が異なると判断する。それどころか、最悪の場合、RankBrainは靴のスパムサイトが自動車サイトから大量のバックリンクを得ていることを発見するかもしれない。これは非常にまずい事態だ。
そういう次第で、RankBrainは、それが正しい手段で得られたバックリンクかどうかに関わりなく、検索結果にとって「良い」リンクであるか「悪い」リンクであるか区別しようとする。その結果、この靴サイトには警告フラグが立ち、サイトの努力もむなしくオーガニックなトラフィックも急降下するということになりかねない。
SEOの未来と人口知能
以上見てきたように、RankBrainなどの人工知能は、ある時点でその能力が人力を超えてしまう。その後人口知能がどこへ向かうのか人間には正確に判断できなくなる。
しかし確実なこともある。
- それぞれのキーワードは独自に検索の文脈を検討される
- 誤った分類を防ぐために、多くのサイトはニッチな分野に留まることが必要
- 自サイトが属する分野でもっとも信頼されるトップサイトの構成を模倣することが安全
ある意味でディープ・ラーニングはSEOの仕事をやりやすくしてくれる。RankBrainなどのテクノロジーは人間のやることに非常に近い。どういう意味かといえば、もはや「手っ取り早い抜け穴」などはないということだ。
もちろん困難になった面もある。その一つはSEOが極めて高度なテクノロジー分野になっていくという傾向だ。アナリティクスとビッグデータは単に今日のバズワードであるだけでなく、あらゆるSEOエンジニアが学んでおかねばならない基礎でもある。学ぶためにはたいへんな苦労をするかもしれないが、こうしたテクノロジーを使いこなせるエンジニアは高給を期待してよい。
画像::Maya2008/Shutterstock
〔日本版〕この投稿は長文のためGoogle RankBrain等に直接関連ある後半を訳出した。人工知能全般を論じている前半は原文を参照。
[原文へ]
(翻訳:滑川海彦@Facebook Google+)





















 Googleのニュースに目を見張っている人にとっては、Alloの発表自体には特段の驚きはなかっただろう。昨年12月のWSJの
Googleのニュースに目を見張っている人にとっては、Alloの発表自体には特段の驚きはなかっただろう。昨年12月のWSJの 絵文字機能や、文字のサイズを変化させてメッセージの内容を強調できる「ささやき(Whisper)/大声(loud)」モードのほかにも、たくさんのAIベースの機能が備わっているのだ。
絵文字機能や、文字のサイズを変化させてメッセージの内容を強調できる「ささやき(Whisper)/大声(loud)」モードのほかにも、たくさんのAIベースの機能が備わっているのだ。




















