Sylvain Kalache
Crunch Network Contributor
本稿を執筆したSylvain KalacheはHolberton Schoolの共同ファウンダー。Holberton Schoolは高技能ソフトウェア技術者を養成する2年制の学校だ。また、10年以上にわたってアントレプレナーやソフトウェアエンジニアたちと仕事をしてきている。CIOやVentureBeatにも寄稿している。
How to join the network
気づけば身の回りには人工知能だらけといった状況だ。車にも家にも、もちろんポケットの中にも人工知能がある。IBMはWatson(ワトソン)に「理屈」を教え、さらに自らも「理屈」を学び得るように育てている。情報を知識に変え、たとえば医療分野で情報に基づいたさまざまな判断を下せるようにしているのだ。
トップ企業がプロダクトにAIを埋め込み(Siri、Alexa、Googleアシスタントなど)、スマートフォンをより便利にし、さらに急速に広がりつつあるホームアシスタント市場で存在をアピールしている。
そうした人工知能ツールは、次第により適切な解答を出すことができるようになりつつある。ひいては、利用者がよりスマートに振る舞えるようになってきているのだ。ところで、常に大量の情報やインテリジェンスが自分の手元に存在する時代を迎えて、教育は変わらなくて良いのだろうか。事実や数字を覚えこませるのではなく、そうした情報を発見する方法を教えるようにすべきなのではないか。現在AIに対して行うようになっているように、「どのように学ぶのか」を教えていく必要があると思うのだ。
残念ながら、今のところの教育スタイルは時代に追いついていないと言わざるを得ない。何百年も続いてきた旧来の方法に拘泥し、学校や教師は知識を与えるものだとされている。しかし、生徒自らが、たとえばAlexaを通じて必要な情報を何でも入手できる時代に、学校や教師の役割が旧態依然としたもので良いのだろうか。時代の流れを把握して、ただ情報を与えるだけの教育システムを変えて移行とするフィンランドのような国もある。生徒たちはグループで課題に取り組み、そして問題解決の方法を学んでいくのだ。教師の役割は、生徒自らが学んでいくのを手助けすることになる。そうして思考の柔軟性を身につけ、さらに学び続ける能力を身に着けていくこととなるのだ。世界経済フォーラム(The World Economic Forum)は、小学校に入学する生徒の65%は現在存在しない職につくことになるとしている。そうした時代への対応力を磨く教育が必要となっているのだ。
コンピューターのちからを利用して、人間の知性がクラウド化するような時代を迎えつつある。意識しているか否かに関係なく、私たちは「バイオニック」な存在になりつつあるのだ。私たちの感覚や身体的機能は、コンピューターやスマートフォンと連携して強化されることとなっている(記憶やデータ処理の一部を代行して、脳の負担を軽減してもいる)。AIは確かに人類をスマート化しつつある。人間のちからだけでは不可能だった情報処理能力を与えてくれているのだ。
AIトレーナーの目標は、コンピューターが自身で学び始めるシンギュラリティに到達すること。
ほんの少し前まで、何か情報が必要であれば図書館に出かけて司書や書籍のインデックスを頼って探すしかなかった。参考になりそうな本を見つけ、その本に探している情報が記されていることを願いながらページを繰っていたのだ。膨大な時間をかけて、マイクロフィルムで記事や写真を探したりもした。現在ではパーソナルアシスタントに尋ねれば、あっという間に情報が手元にやってくるようになった。
ただし、パーソナルアシスタントでは対応できない問題というものもある。そうした場合には自らが検索エンジンを利用して情報を探すこととなる。ここで、アクティブ・ラーニング(self-learning)が重要となってくる。検索エンジンを活用する場合、まず正しい語句を使って検索するテクニックが必要となる。そして役に立ちそうな情報を取捨選択して、情報の正しさをきちんと判断しなければならないのだ。「インターネットで見つけたから正しい」などということはなく、情報の正しさや有用性を判断するのは、検索者の側にまかされているのだ。
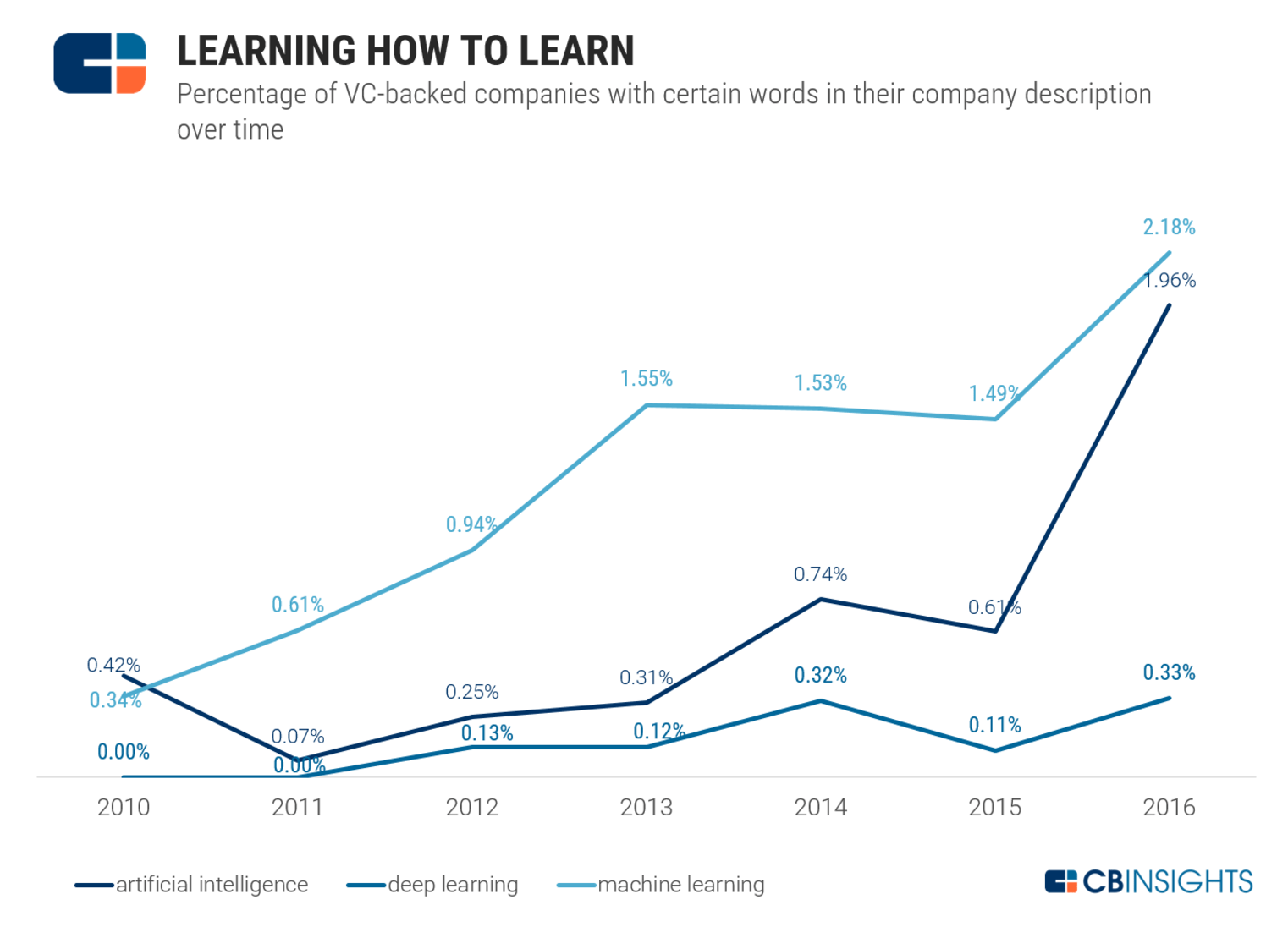
コンピューターの能力は高度化して、そして価格は安くなっている。また大量のデータも入手できるようになった。そうした中でAIの分野が大いに賑わってきているのだ。ディープラーニングの成功を導くのに必要な、ニューラルネットワークの構築が効率的に行えるようになってきているのだ。CB Insightsの情報によれば、ベンチャーキャピタルが投資する企業の2%が、AIアルゴリズムの強化に携わっているのだそうだ。「いかに学ぶかを学習する」という点に、多くのベンチャーが注力しているのだ。その方法を学んでこそ、アクセス可能な膨大な情報の中から正しく学ぶことが可能となるのだ。
しかしGlobal Future CouncilでAIおよびロボット部門の共同議長を務めるMary Cummingsによると、「人工知能は期待に沿う能力を発揮できていない」としている。自ら学ぶ能力は未だ発展途上で、現在のところは人間が手を貸して、仕事効率を挙げる程度の使い方に留まっているというのだ。確かに、それが現在の状況だろう。ニューラルネットワークのちからを存分に活用するGoogleの検索エンジンも、人がそれを活用してこそ仕事に役立つようになっている。
ホモサピエンスが最初に道具を創りだして以来、私たちは生活のために新しい道具の使い方を学習し続けてきた。ときに、作業は完全にテクノロジーにより行われるようになったものもある。人類はそうした状況にも適応し、自分たちの能力を発揮する方向を見つけてきているのだ。ただ、現代になって変化のスピードは急速に上がっている。
AIはシンギュラリティを目指している。人工知能自らが情報を取捨選択して学習を続けていくような世界の実現を目指しているのだ。世界に「スーパーインテリジェンス」を登場させようと狙っているわけだ。そうした時代はまだ少々先のことのようだが、AIに対する教育方法は人類に対しても使えるのではないかと思う。AIに実現させようとしているように、人類の教育でも「自ら学ぶ」ことを強化していく必要がある。そうしたトレーニングを経て、人類は新たなテクノロジーを制御して、それを最大限に活用できるようになっていくのだ。世界経済フォーラムのレポートにもあるように、「創造性をさらに磨き、これから訪れる変化に備える必要がある」のだ。21世紀、AI時代の人材を育てるために、ふさわしい教育システムというものがあるはずだ。
[原文へ]
(翻訳:Maeda, H)