よってAlphabetのハードウェアのためのビジョン「Made by Google」は、消費者たちに対して利便性の誓いを販売することである。そして、全てを接続するデバイスと共にこの販売ピッチが、パーソナルスペースをユーザー情報データベースへと変容させ、この先何十年にも渡って広告エンジンに燃料を供給し続けることが可能になるのだ。
ゆっくりと、しかし着実に、Amazonは音声認識AIソフトウェア「Alexa」の機能を、数ある自社製ハードウェア製品に組み入れつつある。数週間前、Amazonはこの音声アシスタント機能を米国で提供中のTVストリーミング向けハードウェアソリューションに導入すると発表した。ここでいうハードウェアには上位機種のFire TVから、より小型でドングルベースのFire TV Stickなどが含まれる。
Fire TV Stickの新たに発表されたバージョンでは音声認識機能が組み込まれ、「Fire TV Stick with Alexa Voice Remote」という、さらに長くなった新名称での発売となる。このちょっと呼びづらい新バージョンの販売価格は前バージョンから据え置きの40ドルで、音声認識対応のリモコン(以前は単体で30ドルした)が付属している。リモコンからは音声コマンドでアプリの起動、プログラム検索、チャンネル選択などを操作できる。
今日(米国時間9/28)、上述の5社は共同で発表を行い、AIにおける新たな提携を発表した。このPartnership on AIは人工知能に関する研究及びベストプラクティスの普及を目指すという。現実の活動して考えると、この5社の代表は頻繁にミーティングを行い人工知能の進歩を促進するための議論を交わすことになる。またこのグループは企業の垣根を超えてコミュニケーションを図る正式な組織も結成する。もちろんメンバー各社は日々のビジネスでは人工知能をベースにしたサービスやガジェットの開発をめぐって激しく競争しているライバル同士だ。
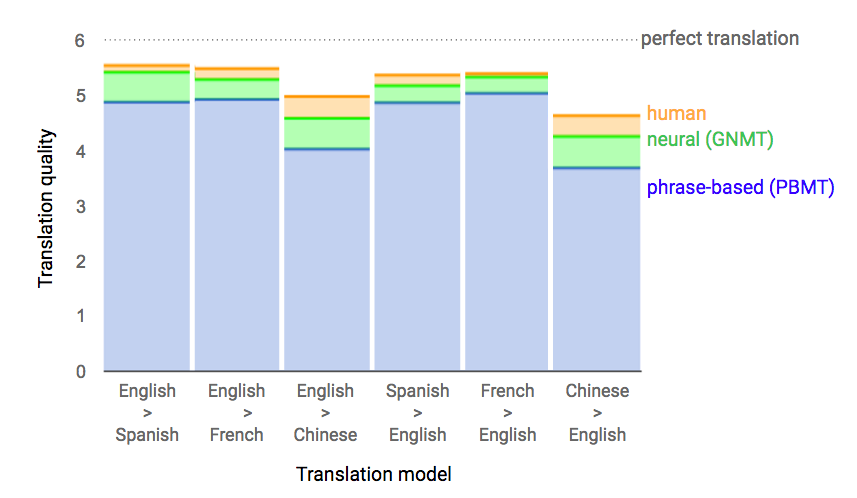
言語は語句の組合せで成り立っているので、論理的に考えて、自動翻訳の次のステップはできるかぎり大量の語句とその組合せの簡単なルールを収集し、翻訳作業に適用することだ。しかしそのためには非常に多量のデータを必要必要とする(単なる二ヶ国語辞書ではとうてい足りない)。たとえば同じrunという動詞一つ取ってもrun a mile〔1マイルを走る〕、 run a test〔テストを実施する〕、run a store〔店を運営する〕ではまったく意味が違ってくる。この違いを見分けるためには膨大な例文の統計的処理が必要になる。しかしコンピューターはこうした処理が得意だ。そこで必要なデータとルールが収集されれば語句ベースの自動翻訳を実用化することができる。
IBMのデータ分析担当VP Rob Thomasによると、企業はこのツールを活用することによって、人件費を大幅に節約できる。またデータ分析に関して、企業の特定部門の人間を教育訓練する苦労もなくなる。さしあたり、リテールや金融、通信などの分野が主な顧客層になるが、しかしThomasによると、中小企業のうち‘中’の方の企業も今すでにこのシステムに関心を示している。
「ここで大切なのは私たちのテクノロジーではありません」クロージングとしてナデラはこう語った。「私にとって本当に大切なのは、皆さんの情熱、皆さんの想像力、そして私たちが作成した技術を使って皆さんができることです。一体どんな社会問題を、そしてどんな産業を、みなさんは再構築してくれるのでしょうか。それこそが本当に私たちが夢見ていることなのです。かつて私たちが皆さんの指先に情報を連れてきたように(訳注:かつてビル・ゲイツはInformation at Your Fingertipsという標語を掲げていた)、私たちはAIを皆さんのものにしたいのです」。
あなたが高校生であろうとNFLのチームオーナーであろうと、誰もがSMS(テキスト)を使っている。1st and Future competitionのファイナリストであるReplyBuyは、SMSを使ってスポーツイベントの購入ができるようにしようとしている。1st and FutureはNFL、スタンフォード大のビジネス大学院 、TechCrunchの共催によるスポーツ中心のスタートアップコンペティションだ。
同社が設立された2011年以来、彼らは265万ドルを調達してきた。また最近同社は、Sports Business Awardsの主催する「Best in Mobile Fan Experience」アワードにノミネートされた、またTicketing Technology Awardsでも「Move to Mobile」部門と「Product Innovation」部門にノミネートされている。
私たちは、TechCrunchイベントの同窓生がそれぞれの業界で輝きを放つことを見られることに興奮している、そして来るDisrupt London 2016のStartup Battlefieldでどのような次世代スタートアップ群を見られるのかが待ちきれない思いだ。Battlefield参加申し込みは現在受付中で10月5日が〆切である、もしあなたの会社が応募資格を満たしているなら、Battlefieldにはここから申請することができる。
Disrupt London 2016は12月5-6日に 、ロンドンのCopper Box Arenaで開催される。素晴らしいイノベーター、投資家、そしてハイテク愛好家たちに会える日が待ちきれない。
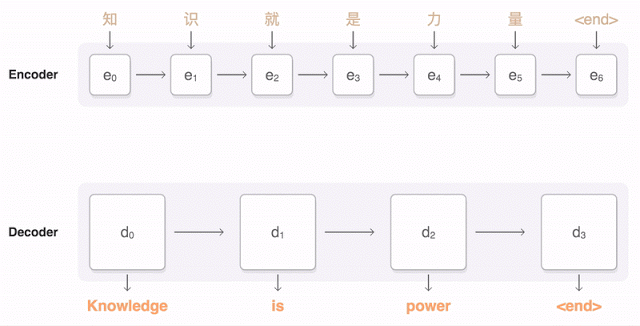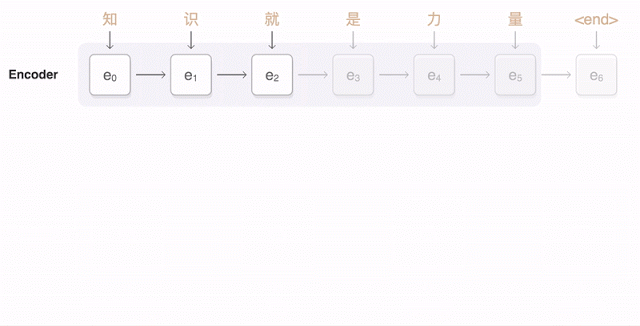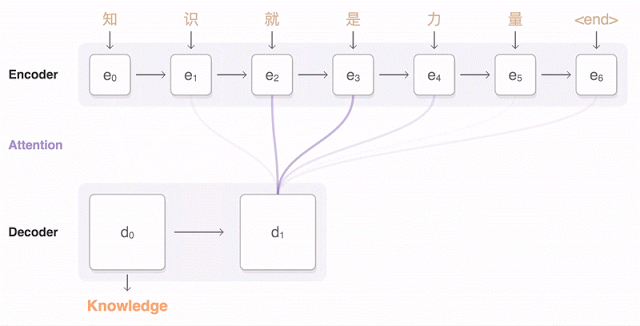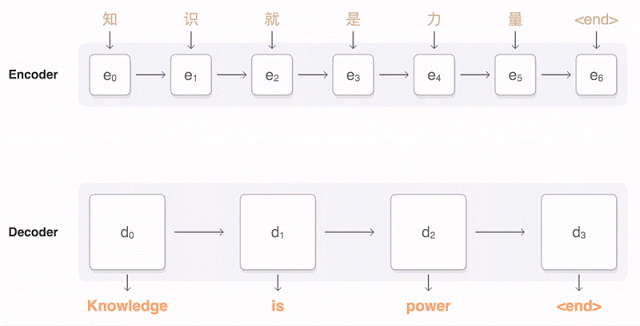
コンピューターと違って人間には、まあまあのコミュニケーション能力がある。だれかが、“the girl saw a man with the binoculars”と言ったら、われわれは文脈的知識を動員して、「女の子が双眼鏡で男を見た」のか、それとも「女の子が双眼鏡を持ってる男を見た」のか、どちらであるかを正しく判断できる。
ロボットに同じことをやらせるのは、とても難しい。誰かが“get me a lift”と言ったらそれは、「同乗(相乗り)させてくれ」と言ってるのか、それとも「(Uberのライバル)Lyftを呼んでくれ」と言ってるのか? こういう曖昧さが加わると、同じひとつのことを言うのに、無限に多くの言い方がある。コンピューターにとっては、超難題だ。










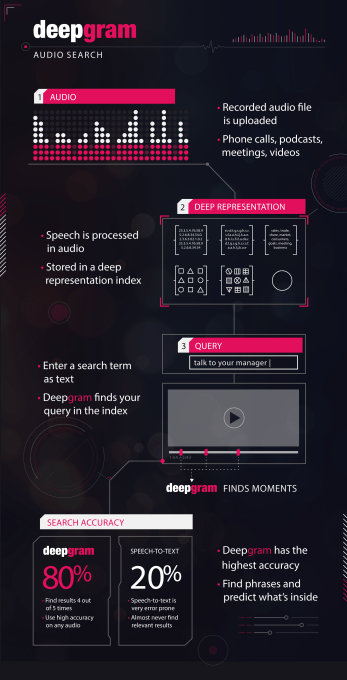 創業者たちによれば、このオーディオ検索テクノロジーは、自然言語処理に依存している他の技術とは相当に異なっているものだということである。「私たちは、モデルが通話の違いを区別できるように訓練しています」と、Stephensonはインタビューで述べている。「それをコンテキストの観点でやっているのです」。
創業者たちによれば、このオーディオ検索テクノロジーは、自然言語処理に依存している他の技術とは相当に異なっているものだということである。「私たちは、モデルが通話の違いを区別できるように訓練しています」と、Stephensonはインタビューで述べている。「それをコンテキストの観点でやっているのです」。














