普通の人はおそらく聞いたこともない技術だろうが、Kubernetesは今年2017年に、コンテナテクノロジーを使うITプロたちの間で、急速に人気を獲得した。Kubernetesは、運用スタッフがコンテナ群を大規模に展開および管理するための基盤を提供するオーケストレーションエンジンである。(コンテナの基礎については、 この記事を参照のこと )。
もっと分かりやすい言い方をするなら、コンテナの数が増加するにつれて、それらの起動や状態を管理するツールが必要になるということだ。コンテナというアイデア自身や、それが可能にするいわゆる「マイクロサービス」モデルが、複雑なモノリシックなアプリケーションを、はるかに小さく管理しやすいものに分解するので、必然的にコンテナの数は時間とともに増加する傾向がある。Kubernetesはこうした際の運用/管理用途に使われる事実上の標準ツールとなっている。
Kubernetesは、元々はGoogleで開発されたオープンソースプロジェクトで、現在はCloud Native Computing Foundation(CNCF)によって管理されている。昨年、AWS、オラクル、マイクロソフトなどを含むテクノロジー界の大企業たちがCNCFに名前を連ねた。もちろんKubernetesの開発に何らかの影響を与えたいという思いが、その動機の大半を占めている。
急速な成長
Kubernetesが勢いを増すにつれ、それはイノベーションとビジネスアイデアのプラットフォームになってきた(人気のあるオープンソースプロジェクトではよく見られることだ)。早期に採用を行った企業たちは、いまや新技術に移行したいものの内部に専門家がいない顧客たちを支援できるチャンスを得ている。支援企業は、このようなツールを使用することに伴う基本的な複雑さを隠すことによって、商業的な機会を創出することができる。
私たちは、Kubernetesでもこの大きな流れを見ることができている。支援企業たちはオープンソースに基づいたブロダクトの開発を始めており、それによってツールの細かな癖に精通せずとも、利用と実装が容易になるパッケージアプローチが可能になる。
利用実績がどれほど急速に伸びているかを知ってもらうために、451 Researchが行ったサーベイを紹介しよう。2015年に行われた調査では、回答企業の10%が何らかのコンテナオーケストレーションツールを使用していた(Kubernetesもしくは他の競合を含む)。ちょうど2年後に行われたフォローアップ調査では、451は、回答企業の71%がコンテナ管理のためにKubernetesを使用していることを報告している。
Googleのプロダクトマネジメント担当副社長であるSam Ramji(以前はCloud Foundry FoundationのCEOだった)は、こうしたことが一夜にして起きたような感じを受けているかもしれないが、他の多くのことと同様に、作成には長い時間を要したのだと語っている。Kubernetesの直接の前身はBorgと呼ばれるGoogleのプロジェクトである。Ramjiは、2014年にオープンソースプロジェクトとしてKubernetesをリリースする10年前から、Googleはコンテナを実運用していたのだと指摘する。
「10年近いコンテナの大規模運用の歴史をGoogleは持っていました。実験ではありません。Borgの上でGoogleのビジネスが大規模に運用されていたのです。Kubernetesはそれらのレッスンに基づいて、ゼロから構築されたものです」とRamjiは語った。
クラウドネイティブコンピューティング
Kubernetesやクラウドネイティブツールを使用する背景にある大きな要因の1つは、企業がリソースの一部をクラウドに置き、一部をオンプレミスのデータセンターに置くハイブリッド環境での運用が増えていることだ。Kubernetesのようなツールは、どこにデプロイされても一貫した方法でアプリケーションを管理できるフレームワークを提供する。
その一貫性が、人気の大きな理由の1つなのだ。IT部門が2つの異なるツール(またはツールセット)を使用して、2つの異なる場所でアプリケーションを管理することを余儀なくされた場合、やがてどのリソースが利用され、データがある瞬間にどこにあるかを把握することが難しくなるような混乱に陥る可能性がある(実際にそのようなことは起こっている)。
クラウドネイティブコンピューティングファウンデーション(CNCF)が、KubernetesファウンデーションではなくCNCFと呼ばれる理由は、Googleやその他の運営メンバーたちが、Kubernetedはクラウドネイティブストーリーの一部に過ぎないと考えているからだ。もちろんそれは「大きな一部」かもしれないが、彼らはより豊かなツールシステムを目指したいと考えている。より広範な名前を付けることで、オープンソースコミュニティ対して、クラウドネイティブのやりかたで、インフラストラクチャ管理機能を拡張するためのツールを構築するように奨励しているのだ。
採用に向かう大企業たち
このプロジェクトへの貢献者のトップ10を見ると、OpenStack、Linux、その他のオープンソースプロジェクトにまたがった、主要なテクノロジープレイヤーたちの名前を見ることができる。それらはGoogle、Red Hat、CoreOS、FathomDB、ZTE Corporation、Huawei、IBM、Microsoft、Fujitsu、そしてMirantisなどだ。
CNCFのエグゼクティブディレクター、Dan Kohnは、これらの企業は、基盤技術では協力を行いながら、高レベルのツールで競争することが、より効果的であると認識しているのだと言う。「Linuxに関するアナロジーを使うことができます。人びとはKubernetesを『クラウドのLinux』と表現しています。企業のすべてが手を携えたり、同じ顧客に対して競合しないことにしたというわけではありません。ただ、コンテナオーケストレーションそのもので競争することには、あまり価値がないと認識しているのです」。
そして、これらの企業の多くは、過去12-18ヶ月間の間に、Kubernetesや、コンテナ、そしてクラウドネイティブ関連企業を買収している。
| 会社名 |
買収企業 |
目的 |
買収日付 |
金額 |
| Red Hat |
Codenvy |
コンテナ開発チームワークスペース |
5/25/2017
|
非公開 |
| Oracle |
Wercker |
大規模クラウドネイティブアプリの運用と展開 |
4/17/2017
|
非公開 |
| Microsoft |
Deis |
Kubernetes用ワークフローツール |
4/10/2017
|
非公開 |
| Mirantis |
TCP Cloud |
連続更新 |
9/15/2016
|
3000万ドル |
| Centurylink |
ElasticBox |
マルチクラウドのアプリケーション管理 |
6/14/2016
|
2000万ドル |
| Apprenda |
Kismatic |
Kubernetesのサポートとツール |
5/19/2016
|
非公開 |
これらのすべてが、2015年7月までにはバージョン1.0に達していなかったツールを中心に構築されたビジネスとなった(その前にもいくつかの 0.x リリースが行われている)。それ以降、採用は順調に増加している。
今年の初め、CNCFは、36社がKubernetes認定基準に合意したことを発表した。以前36社ものハイテク企業が何かに合意したのは一体何時だったろうか?彼らがこれを行った理由は、個々のメンバーは互換性がなかったり一貫していないバージョンを作成することを防ぐためだ。もしこれが満たされないならば、期待に反した振舞が起きたり、あるバージョンから他のバージョンへの移植ができなくなったりするだろう。これは一般的にはフォーク(枝分かれ)という名で知られている現象だ。組織はKubernetesの人気の高まりを認識し、可能な限り不都合が起きないようにしたいと考えている。
エコシステムの構築
Kubernetesを商用化している企業には、Google Kubernetes Engine(以前のGoogle Container Engine)を提供しているGoogle自身、Red Hat OpenShift、Pivotal Container System(正しくない略称のPKSとして知られている)、そしてCoreOS Tectonicが含まれている。AWSは、そのコンテナサービスにKubernetesサポートを追加して流れに飛び乗ったばかりだ。今年の初めには、コンテナのブームを生み出したDockerも同じ動きをみせた。
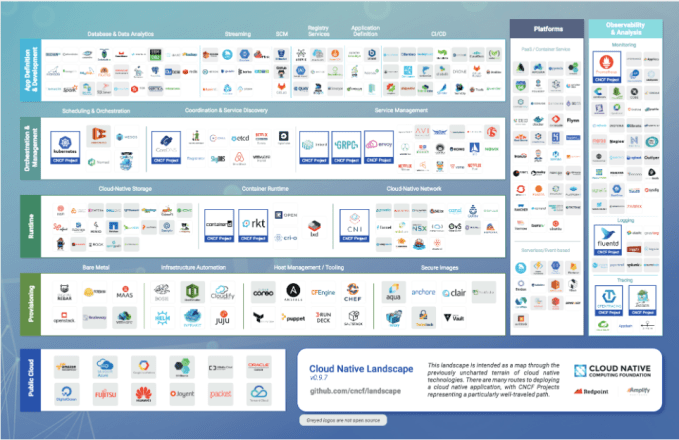
写真:Googleより(クリックして拡大)
Kubernetesのコアなオープンソース版を商用化する方法を探る以外にも、ホスト管理から、セキュアなログ管理と監視に至るまで、少なくないツールが開発されている。
これらがすべて、生まれてわずか2歳のオープンソースプロジェクトの周りに、豊富なツール群を構成している。これがオープンシステムを作成したときに起きることだ。皆がそれを運用するツールアプリケーションを必要とするので、イノベーションが起こる傾向があるのだ。私たちはそれをLinuxで目撃した。同じようにHadoopとOpenStackでも目撃した。そして今やそれがKubernetesでも起きている。今年それは大きな飛躍を果たしたのだ。
[原文へ]
(翻訳:sako)