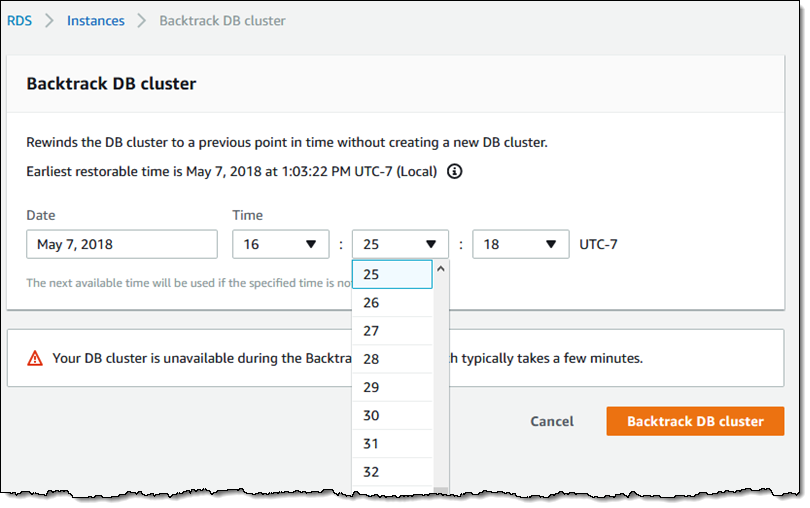
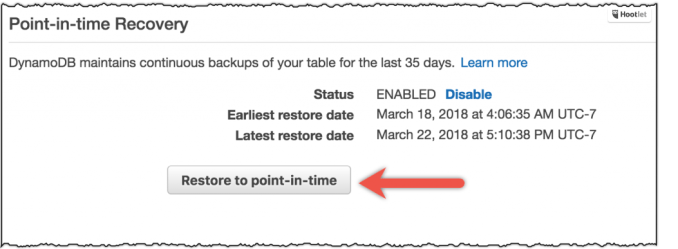
Amazonは常に、AWSを使っているデベロッパーに提供するオプションを増やそうとしている。そして米国時間4月25日、同社はそのためにAMD EPYCプロセッサーによるT3aインスタンスを数多く発表した。これらは最初、昨年のデベロッパーカンファレンスre:Inventで発表された。
しかし今日のは、その一般供用の開始を告げる発表だ。それらはバーストのある特殊なタイプのワークロードに適したインスタンスで、ユーザーの通常の計算力のニーズはそんなに、バースト時ほど高くはないというものだ。
AWSのJeff Barr氏がブログにこう書いている。「これらのインスタンスはバーストに対応できる費用効率のいいパフォーマンスを提供し、常時維持されるコンピュートパワーとしてはそれほど高いパワーを必要としないが、使用時に一時的なスパイクがあるワークロードに適している。そのため、十分に余裕のある、確実に保証されたベースラインの処理能力を提供するとともに、さらなる処理能力が必要なときには、必要十分な時間、完全なコアパフォーマンスにまで透明にスケールアップする能力がある」。
これらのインスタンスは、Amazonが数年かけて開発した特製のネットワーキングインタフェイスハードウェアAWS Nitro Systemを使用する。このシステムの主要な部位は、Nitro Card I/O Acceleration、Nitro Security Chip、そしてNitro Hypervisorだ。
今日のリリースの前身として、昨年発表されたArmベースのAWS Graviton Processorsを使用するEC2インスタンスがある。これもまた、スケールアウトするワークロードのためのソリューションを探しているデベロッパー向けのオプションだ。
さらにこの直前の先月には、低コストのAMDチップを使用するM5およびR5インスタンスが発表された。これらもやはり、Nitro Systemを基盤としている。
EPCYプロセッサーは今日から7つのサイズで可利用になり、必要に応じ、ユーザーが選んだスポットインスタンスやリザーブドインスタンス、あるいはオンデマンドインスタンスで提供される。可利用域はUS East(Northern Virginia)、US West(Oregon)、EU(Ireland)、US East(Ohio)、そしてAsia-Pacific(Singapore)だ。
画像クレジット: Thomas Cloer/Flickr CC BY-SA 2.0のライセンスによる
関連記事: AWSはアグレッシブに世界制覇を目指す――エンタープライズ・コンピューティングで全方位路線
[原文へ]
(翻訳:iwatani、a.k.a. hiwa)




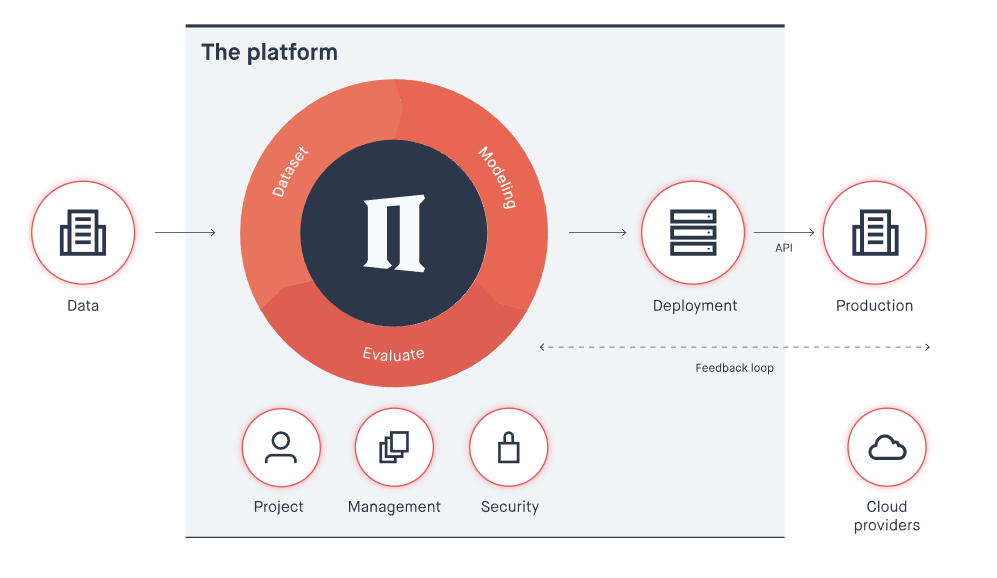
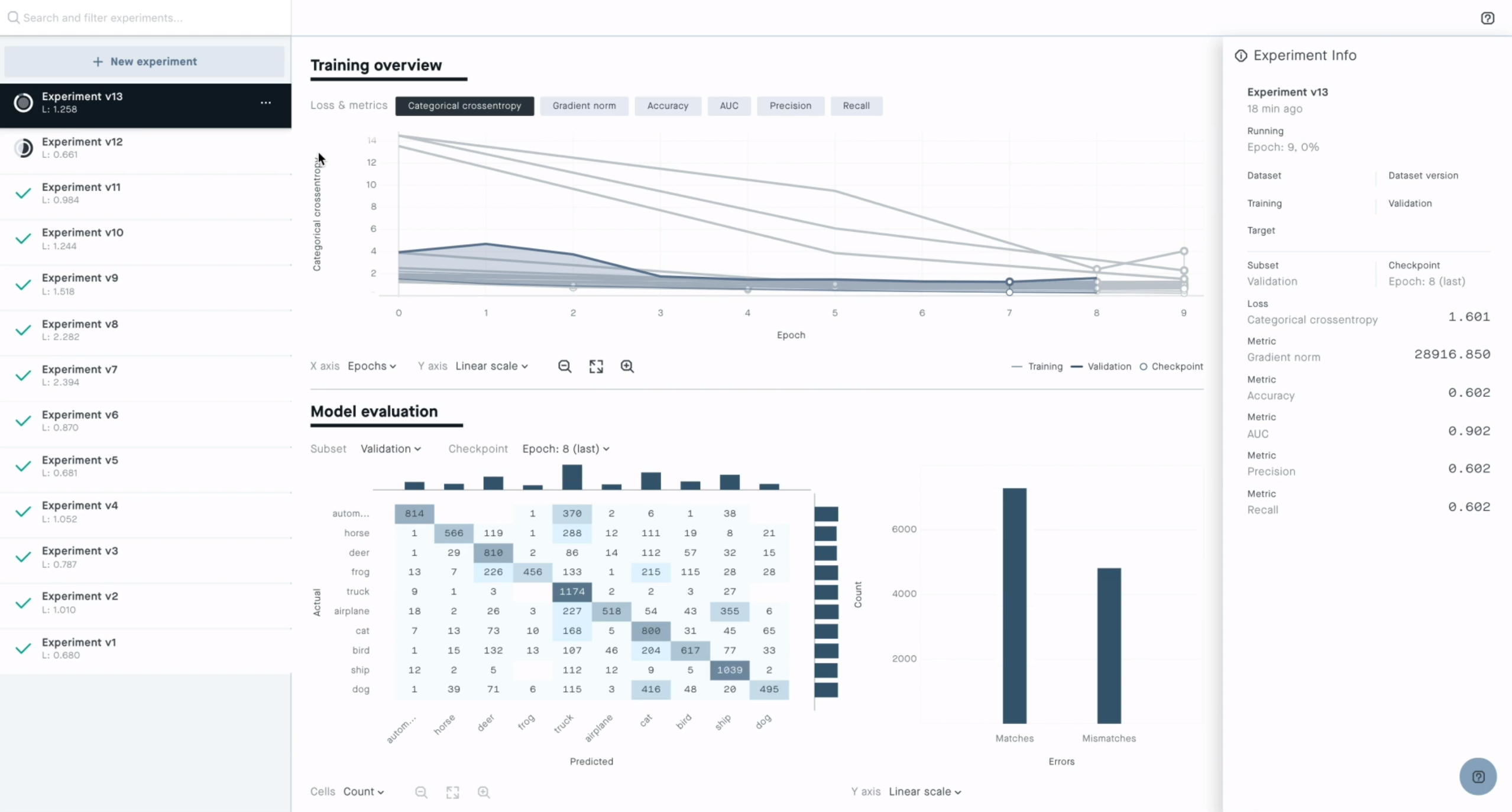
















 それだけではない。開発チームはワークショップの中で、機械学習の経験がまったくないデベロッパーでも既存のテンプレートを簡単に拡張できることを強調していた。ひとつには、DeepLensプロジェクトが2つの部分からなっているためだろう。モデルおよびモデルの出力に基づいてモデルのインスタンスをアクションを実行するLambda機能だ。AWSは、ベースにあるインフラストラクチャーを管理することなくモデルを簡単に作るためのツールとしてSageMakerを提供している。
それだけではない。開発チームはワークショップの中で、機械学習の経験がまったくないデベロッパーでも既存のテンプレートを簡単に拡張できることを強調していた。ひとつには、DeepLensプロジェクトが2つの部分からなっているためだろう。モデルおよびモデルの出力に基づいてモデルのインスタンスをアクションを実行するLambda機能だ。AWSは、ベースにあるインフラストラクチャーを管理することなくモデルを簡単に作るためのツールとしてSageMakerを提供している。