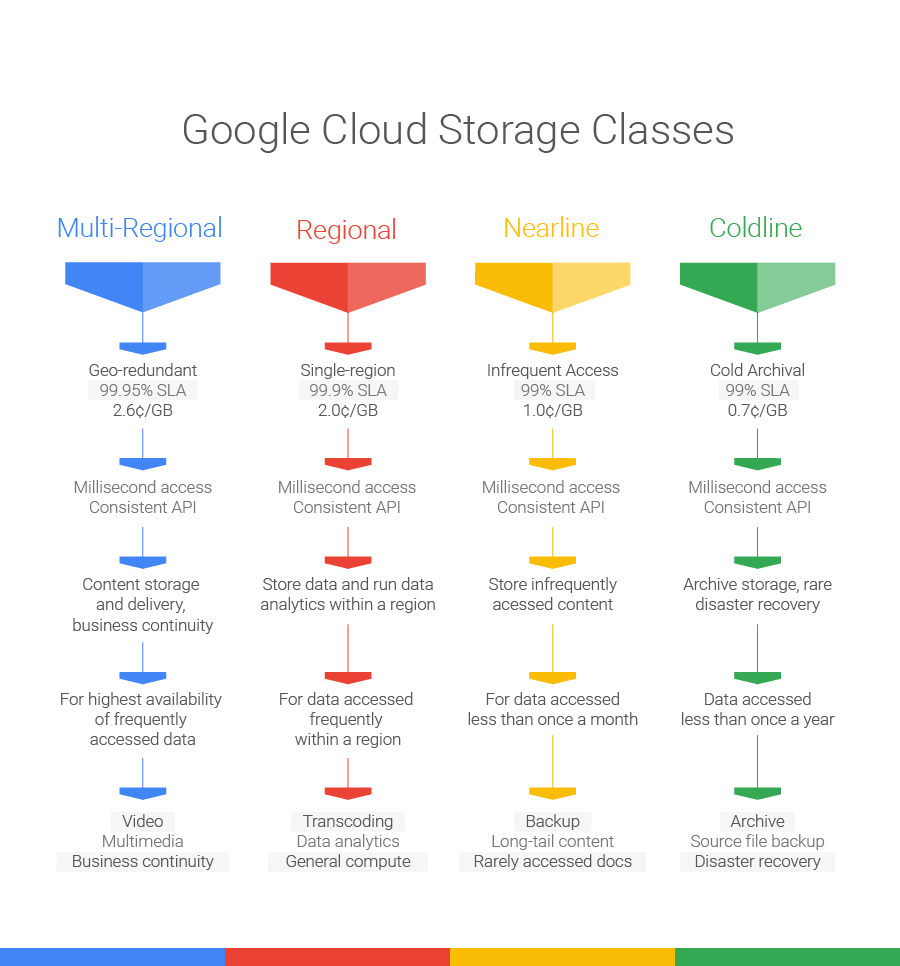
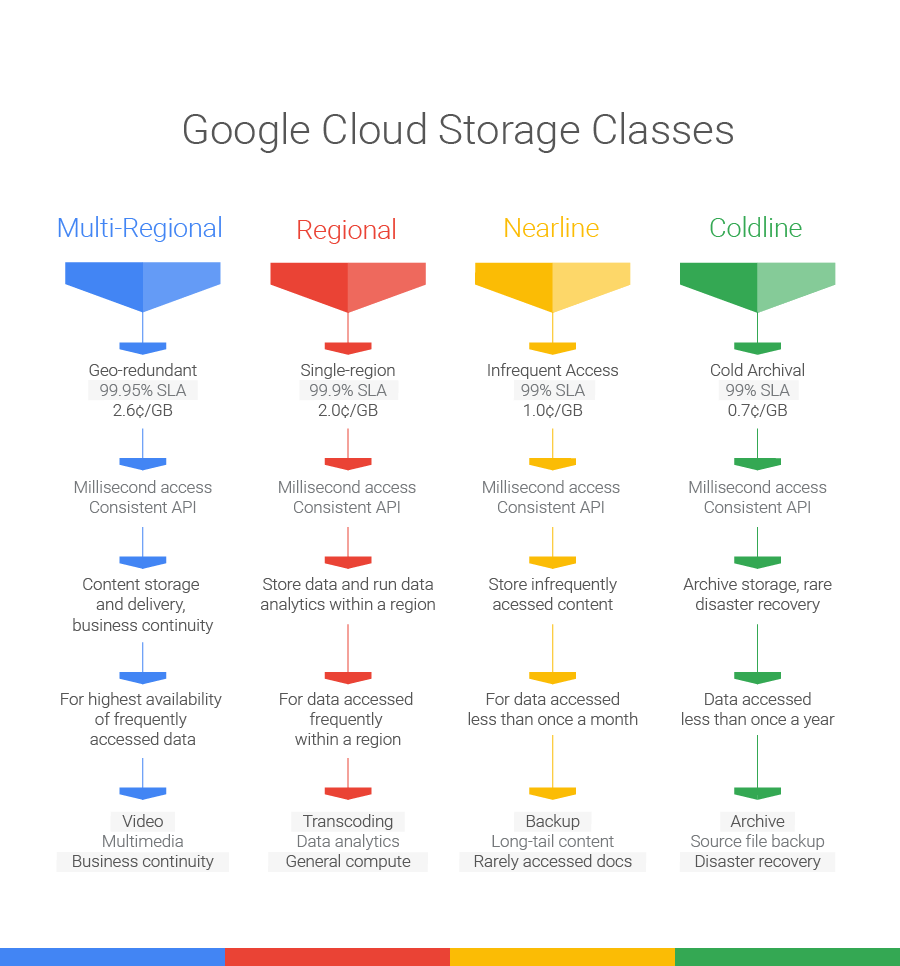
今日(米国時間10/20)ロンドンで行われたイベントで、Googleは同社のクラウドストレージサービスの、二つのアップデートを発表した。中でもいちばん重要なのは、アーカイブ目的のコールドストレージColdlineのローンチだが、ほかにRegionalストレージというサービスも発表された。そして従来のStandardストレージは、“Multi-Region”と名前を変えた(下図)。
すでにGoogle Cloud Storageをお使いの方は、コールドストレージサービスの新たなローンチに驚かれたかもしれない。Googleはすでに、Nearlineという名前で、アーカイブ用ないし災害時復旧用のきわめて安価なサービスを提供しているではないか。ローンチしたときのNearlineは、AmazonのGlacier(氷河)とよく似ていて、きわめて安いストレージサービスだけど、ただしレイテンシ(遅れ)はかなりあるぞ、というサービスだった。でも今年ベータを終えたNearlineは、速度もまあまあになった。3秒から5秒程度のレイテンシはなくなり、データへのアクセスはリアルタイムだ。
今度新設されたColdlineは、これまでNearlineが担っていた、遅れはあるけど安い、という本来のコールドストレージを、あらためて提供する。Coldlineのストレージは月額料金が1ギガバイトあたり0.007ドル(0.7セント)、データの取り出しは1ギガバイトあたり0.05 ドル(5セント)だ。Nearlineの保存料金は月額0.01ドル(1セント)になる。あまり差はないように感じるかもしれないが、膨大な量のデータを保存する場合には、けっこう大きな違いになる。
Googleのスポークスパーソンによると、Coldlineのレイテンシは同社のそのほかのストレージ種別と同じく低い。“Nearlineの低レイテンシが好評だったので、Coldlineの設計でもその特性を重視せざるを得なかった”、そうだ。
Coldlineは、GoogleのSwitch and Save(乗り換えて節約しよう)プログラムに含まれている。企業がこの企画に乗ってデータをGoogle Cloudへ移行すると、100ペタバイトまでは月額のストレージ料金が無料になる。
今回のアップデートで、高速で可用性の高い“standard”ストレージサービスが“multi-regional”と名前を変え、その下に、やや低価格の“regional”サービスが新たに加わる(下図)。
multi-regionalはその名のとおり、冗長性が複数リージョンにまたがる可用性の高いストレージ種別で、あるリージョンがダウンしても、データへのリクエストは別のリージョンへルートされる。その点ではこれまでのStandardストレージサービスと同じだが、multi-regionではその拠点位置がアメリカ、アジア、ヨーロッパの三つになる。
画像提供: Google
つまり既存のStandardストレージで、上記三つの位置のどれかに該当するストレージは、黙っていてもMulti-Regionalに変換され、GoogleのSLAによるとデータの99.95%の可用性が約束される。
そして新たに設けられたRegionalストレージサービスでは、データが単一のリージョンに保存され、SLAによる可用性の約束は99.9%となり、Multi-Regionalよりもやや低い。しかし計算処理とそのためのデータがつねにお互いに至近にあるようなワークロードでは、このやや安いストレージサービスで十分だろう。
ちょっとややこしいのは、既存のDurable Reduced Availability(DRA)ストレージ種別がなくなることだ。それはRegionalにリプレースされるが、しかし既存のDRAユーザーにはサポートが継続する。同社としては、ユーザーのほとんどがRegionalに移行してくれることが望ましいのだ。
以上がGoogleのクラウドストレージの新しい顔ぶれだ。名前が変わっただけ、というものもあるが、総じて今度からは名が体を表しているから、ユーザーにとっても分かりやすいし選びやすいだろう。唯一の新顔のColdlineは、Google Cloud Platform上の初めての本物のコールドストレージサービスだ。それに対して従来からあるNearlineは主に、バックアップやロングテールのコンテンツ*用に使われるだろう。〔*: long-tail content, 種類が非常に多く、個々のアクセス頻度が低いコンテンツ。〕
〔訳注: コールドストレージの“コールド”の本来の意味は、電源が入ってなくて“冷たい”、と言う意味。すなわち、“非常設の”アーカイブ的ストレージ。〕
[原文へ]
(翻訳:iwatani(a.k.a. hiwa))