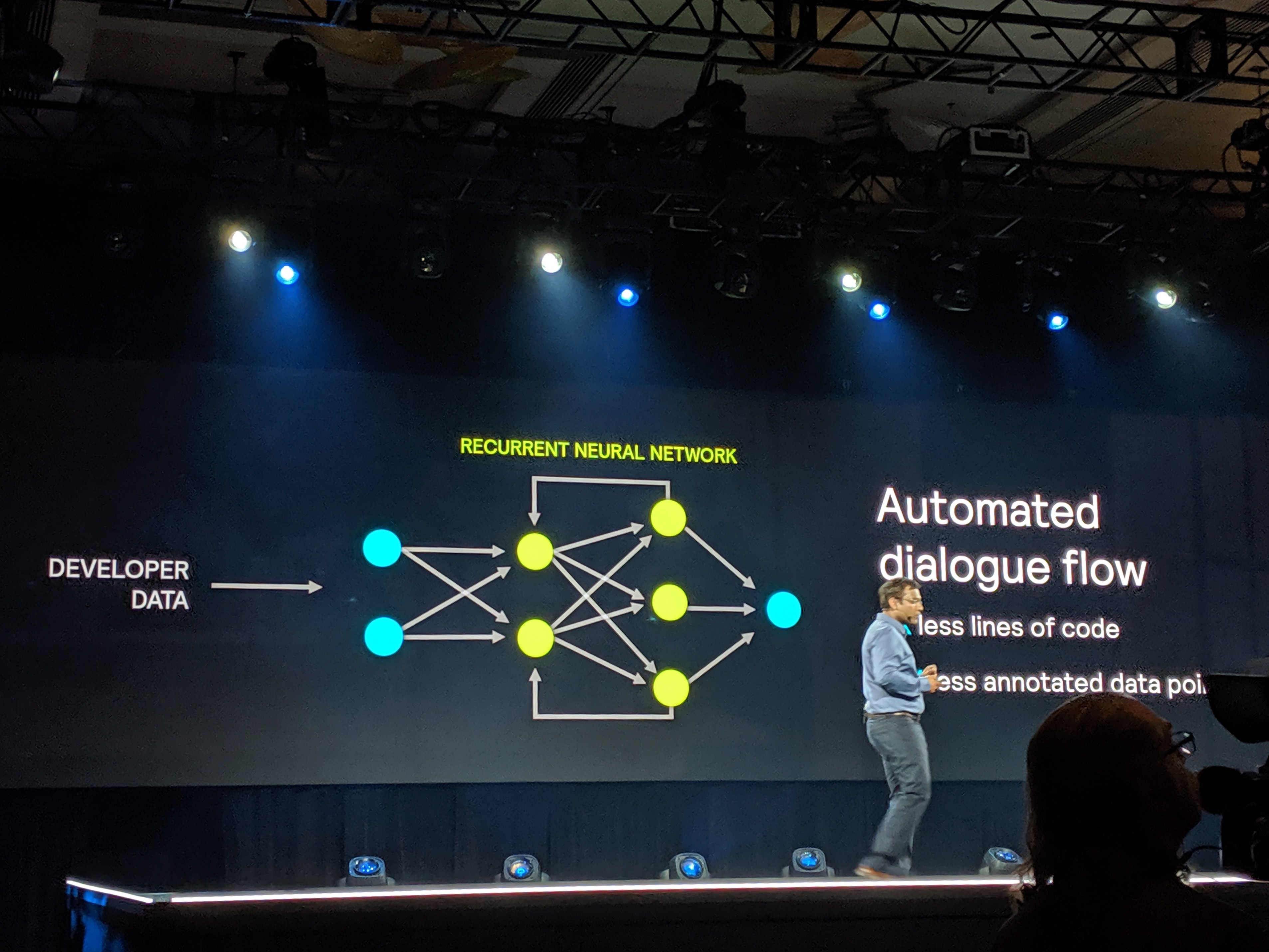
North American Chapter of the Association for Computational Linguisticsに提出された論文によると、アマゾンのAlexa Alの上級応用サイエンスマネージャー、Young-Bum Kim氏のチームは、テストに使用した米国、英語、インド、カナダの4種類の英語について、正確さがそれぞれ18%、43%、115%、57%向上する新しいシステムを設計したという。
すでにAmazon Personalizeを使っているAWSの顧客は、Yamaha Corporation of America、Subway、Zola、そしてSegmentだ。Amazonのプレスリリースによると、Yamaha Corporation of AmericaのIT部長Ishwar Bharbhari氏はAmazon Personalizeについて、「機械学習モデルのセットアップと、インフラストラクチャやアルゴリズムのチューニングに要する時間が、自力でそのための環境を構築構成する場合に比べて最大60%は節約できる」、と言っている。
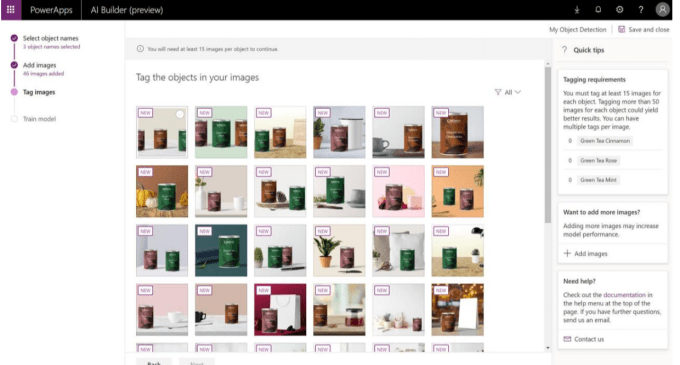
「AI Builderが行うのは、ユーザーのPowerAppsやMicrosoft Flow、Common Data Service、そしてユーザー自身のデータコネクターなどに、人工知能と機械学習を、ローコードもしくはノーコードの手軽さで取り込むことを可能にすることです」とライリー氏はTechCrunchに語った。
スクリーンショット:Microsoft提供
Microsoftのジェネラルマネージャであるチャールス・ラマーナ(Charles Lamanna)氏は、Microsoftはデータモデル構築のために必要な全ての分析と重労働を行うことが可能で、ビジネスユーザーが参入する際の大きな障壁を取り除くのだと言う「基本的なアイデアは、Common Data Serviceの中の任意のフィールドをユーザーが選択して、『このフィールドを予測したい』というだけで済むようにしようということです。そうして貰ったあと、私たちは同じテーブルもしくはエンティティの過去の記録を参照して、(結果を)予想するのです」と彼は説明した。例えばこれは、顧客がクレジットカードに申し込むかどうか、顧客が解約する可能性があるかどうか、あるいはローンが承認されるかどうかなどを予測するために使用できる。
そして、これらの結果すべてを作り出すためにソフトウェアが要した時間は13時間、所要費用は7ドル80セントだった。(訳注: レポート原文より…The language model was trained in under 13 hours on NVIDIA K80 GPUs, costing as little as$7.80 on AWS spot instances. AWSのGPUインスタンスをスポットで使ってモデルを訓練している。)
Robomaは、Facebook、Instagram、Google、Twitterといったプラットフォームの広告アカウントとAPI連携しており、広告アカウントのレポートを自動作成し、費用やCPA(Cost Per Acquisition:ユーザー獲得コスト)などの指標をグラフ化できる。広告費用やコンバージョン単価などが一定の基準を越えた場合に、Slackやメールにアラートを飛ばすことも可能だ。そして管理画面の閲覧権限を広告代理店や社内チームに付与することでスムーズに情報の共有ができる。2018年10月にはマーケターがリアルタイムなROI(Return On Investment:費用対効果)運用を実現できる「ROIレポート機能」が追加された。
Roboma AI導入の実績として、RoboMarketerは、EC通販事業者ではROASが(Return On Advertising Spend:投資した広告コストの回収率)を120から190%にアップした事例、ゲームアプリ運営会社ではアプリのCPI(Cost Per Install:1インストールあたりの広告コスト)を20%以上改善した事例を挙げている。


















 すでに同社が開発中の基礎技術を使った同名の「
すでに同社が開発中の基礎技術を使った同名の「











{kind=link}