【編集部注】本記事はGumGumのOphir Tanz(CEO)とCambron Carter(画像認識チームのトップ)によって共同執筆された。GumGumはコンピュータービジョンに特化したAI企業で、広告からプロスポーツまで世界中のさまざまな分野にAI技術を応用しようとしている。カーネギーメロン大学で学士・修士(いずれも理学)の学位を修めたTanzは、現在ロサンゼルス在住。一方、GumGumで幅広い分野に対応したコンピュータービジョン・機械学習ソリューションの設計に携わっているCarterは、ルイスビル大学で学士(物理学、電子工学)・修士(電子工学)の学位を修めた。
これまでに人工知能(AI)関連の記事を読んだことがある人であれば、ほぼ間違いなく”ニューラルネットワーク”という言葉を目にしたことがあるだろう。ニューラルネットワークとは、大まかな人間の脳の仕組みを模したモデルで、与えられたデータを基に新しい概念を学習することができる。
機械学習の一分野であるニューラルネットワークこそ、長く続いた”AI冬の時代”を終わらせ、新時代の幕開けを告げたテクノロジーなのだ。簡単に言えば、ニューラルネットワークは業界の根底を覆すような、現存するテクノロジーの中でもっともディスラプティブな存在だ。
そんなニューラルネットワークに関するこの記事の目的は、読者のみなさんがディープラーニングについて会話ができるようになるくらいの理解を促すことにある。そのため、数学的な詳しい部分にまでは入らず、なるべく比喩やアニメーションを用いながらニューラルネットワークについて説明していきたい。
力ずくの思考法
AIという概念が誕生してからまだ間もない頃、パワフルなコンピューターにできるだけ多くの情報とその情報の理解の仕方を組み込めば、そのコンピューターが”考え”られるようになるのでは、と思っている人たちがいた。IBMの有名なDeep Blueをはじめとする、チェス用のコンピューターはこのような考えを基に作られていた。IBMのプログラマーたちは、十分なパワーを持ったコンピューターに、あらゆる駒の動きや戦略を余すことなく入力することで、理論上はそのコンピューターが駒の動き全てを予測し、そこから最適な戦略を編み出して相手に勝つことができると考えたのだ。実際に彼らの考えは正しく、Deep Blueは1997年に当時の世界チャンピオンに勝利した*。
Deep Blueで採用されたようなモデルでは、「こうなったらこうして、ああなったらああする」といった感じで、予め膨大な時間をかけて定められたルールに基いてコンピューターが駒を動かしている。そのため、これは強力なスーパーコンピューティングとは言えても、人間のように柔軟性がある学習モデルとは言えない。というのも、コンピューター自体が”考えている”わけではないからだ。
機械に学び方を教える
そこで科学者たちは過去10年のあいだに、百科事典のような膨大なメモリに頼らず、人間の脳のようにシンプルでシステマチックにデータを分析するという、古くからあるコンセプトに再び目を向けることにした。ディープラーニングやニューラルネットワークとして知られるこのテクノロジーは、実は1940年代から存在している。しかし、当時は考えられなかったほどの量の画像や動画、音声検索、検索行動といったデータを入手でき、安価なプロセッサが普及した今になって、ようやくその本当の可能性が花開き始めたのだ。
機械と人間は似たようなもの!
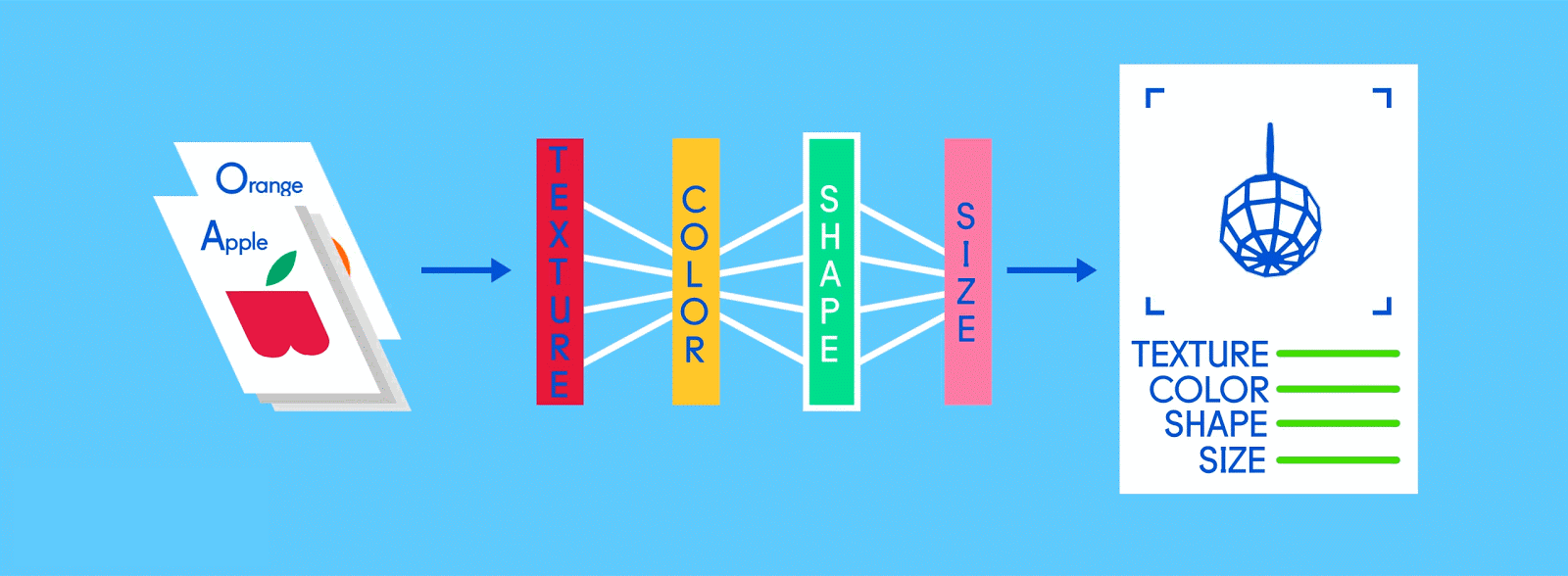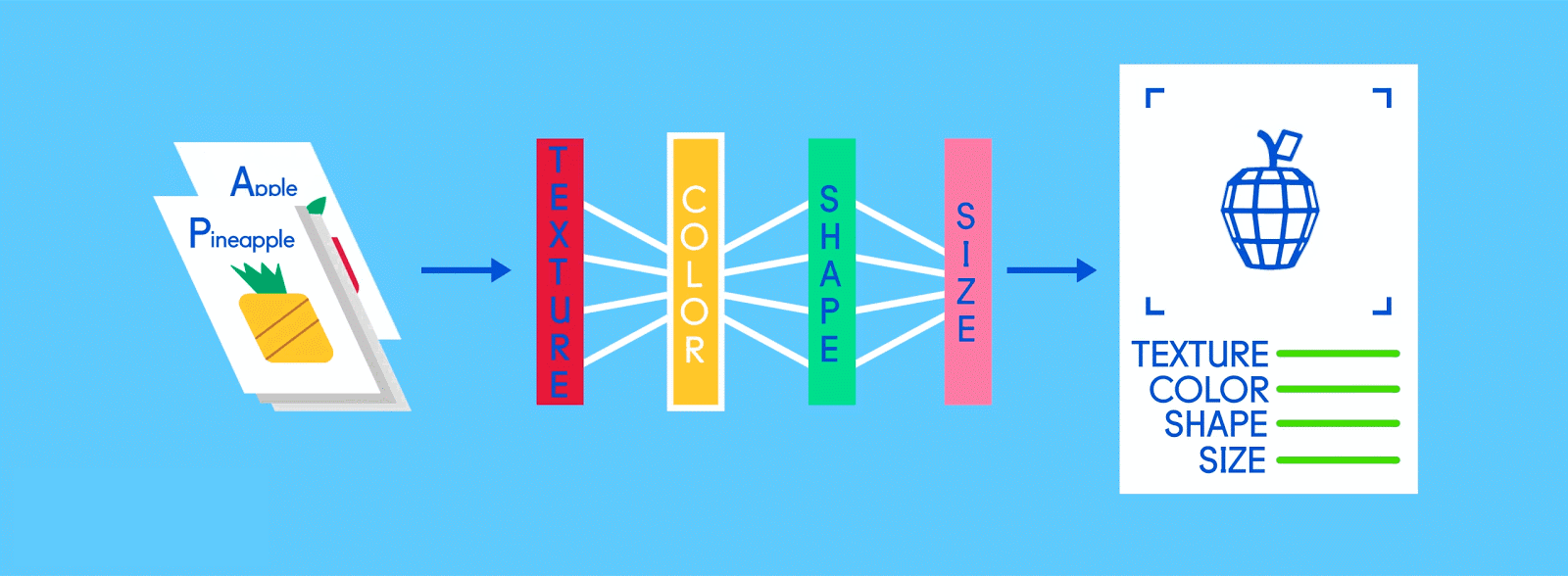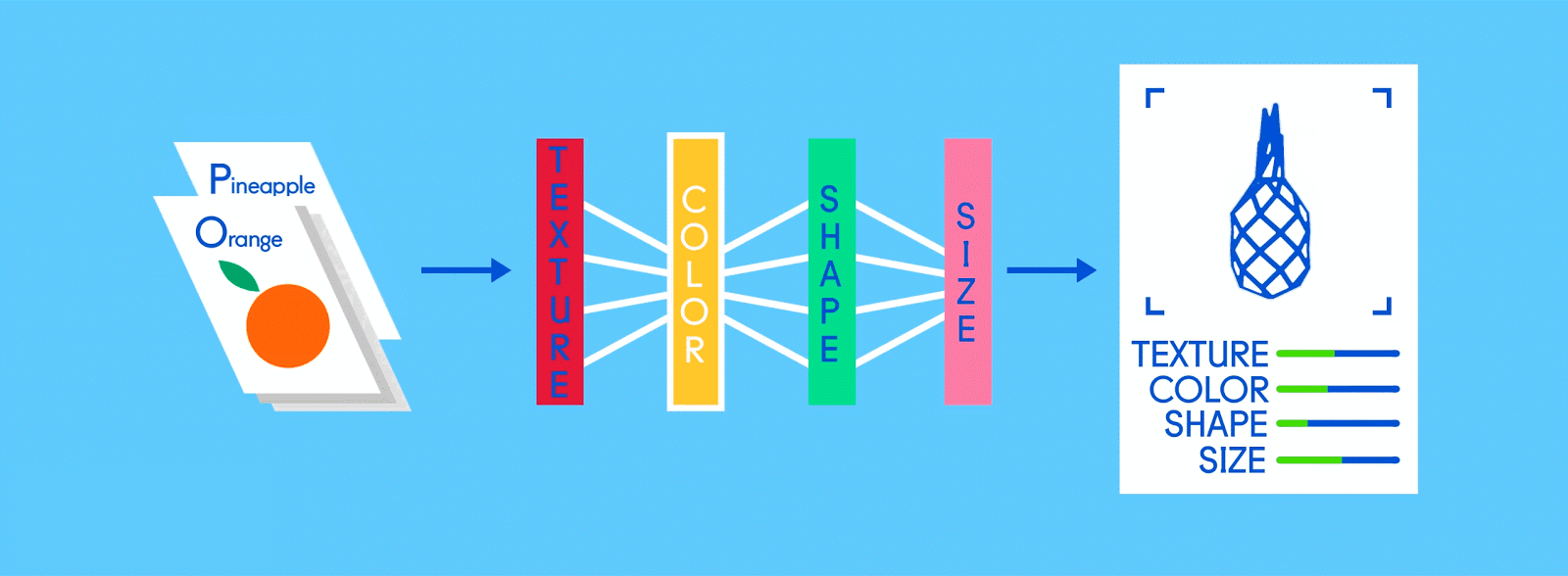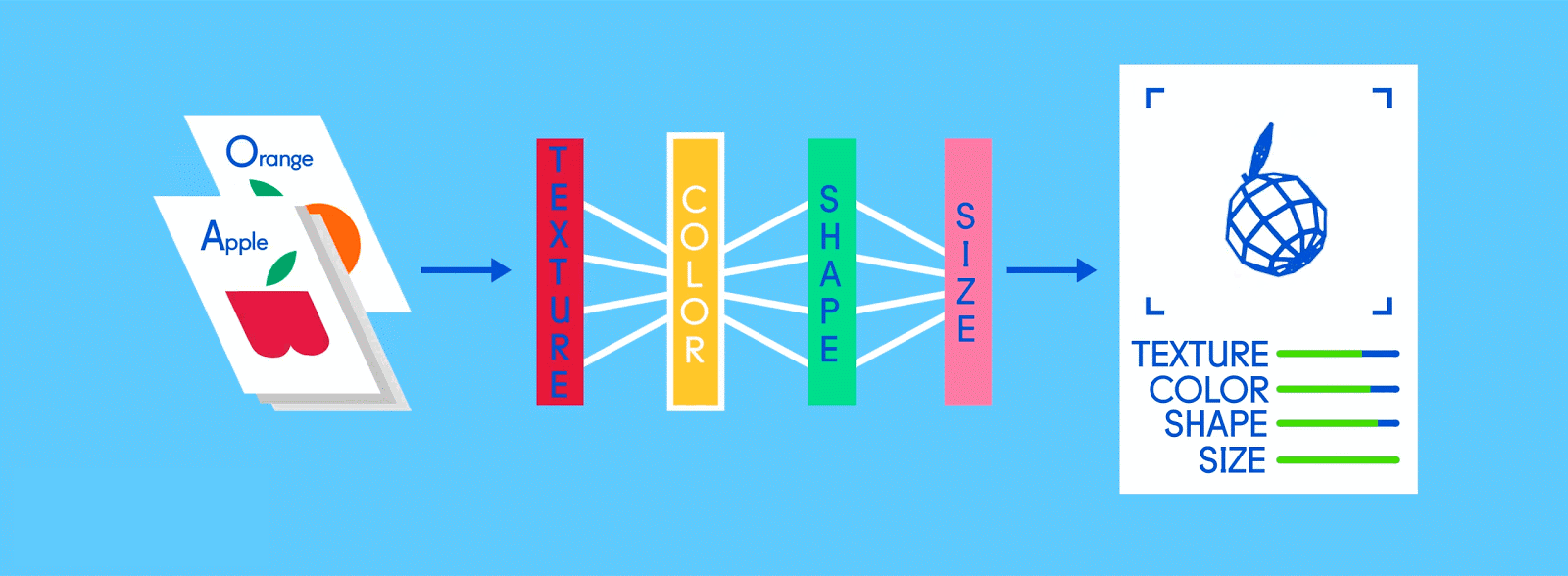
人工ニューラルネットワーク(Artificial Neural Network=ANN)は、音声操作からプレイリストのキュレーション、作曲、画像認識まで、全てをコンピューターに学習させることのできるアルゴリズムだ。一般的なANNは何千という数の人工ニューロンから構成されていて、何百万通りにも繋がりあった人工ニューロンが複数のレイヤー(または層)を形成している。また多くの場合、あるレイヤーと別のレイヤーを接続するときには、入力側か出力側にしか接続できないようになっている(人間の脳内にあるニューロンはあらゆる方向に繋がり合うことができるため、両者にはかなりの差がある)。
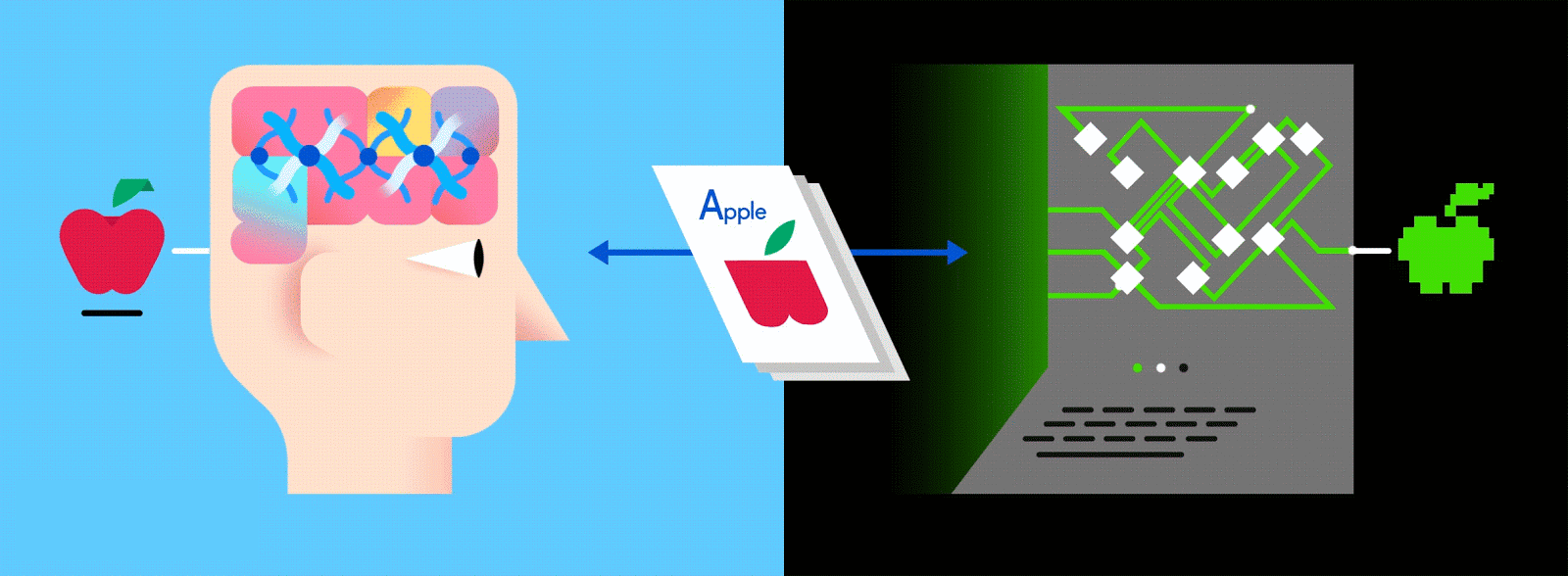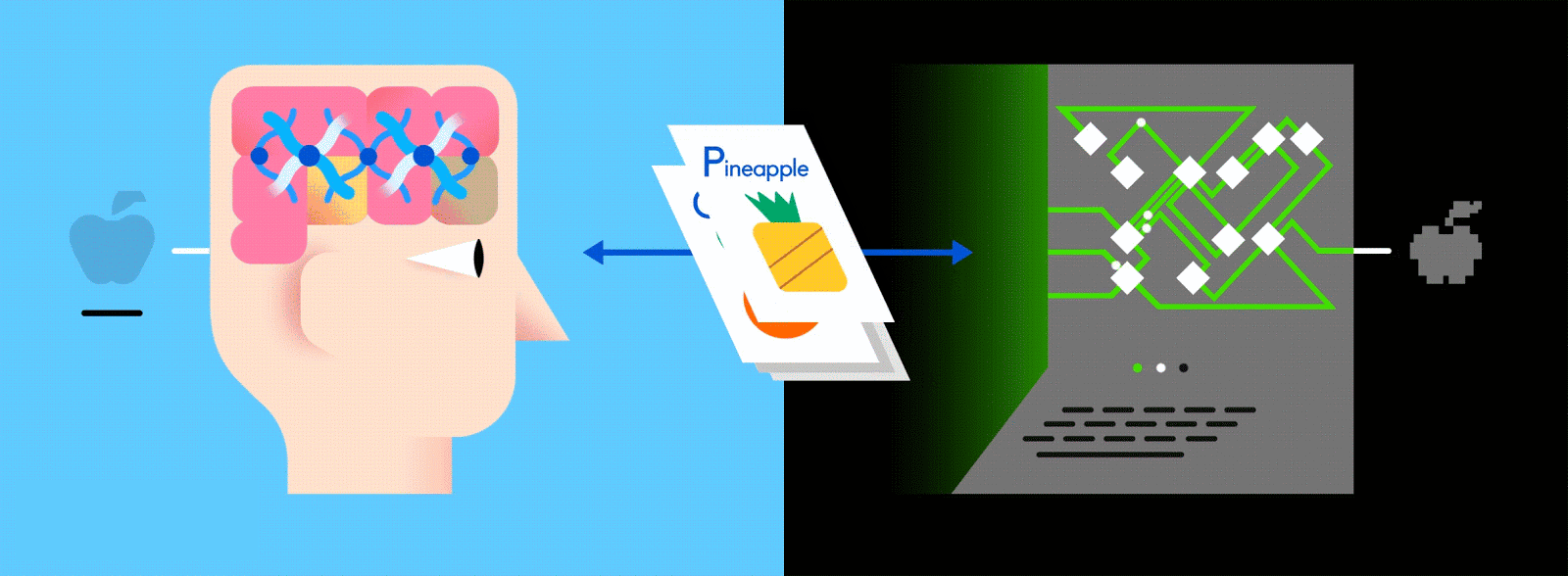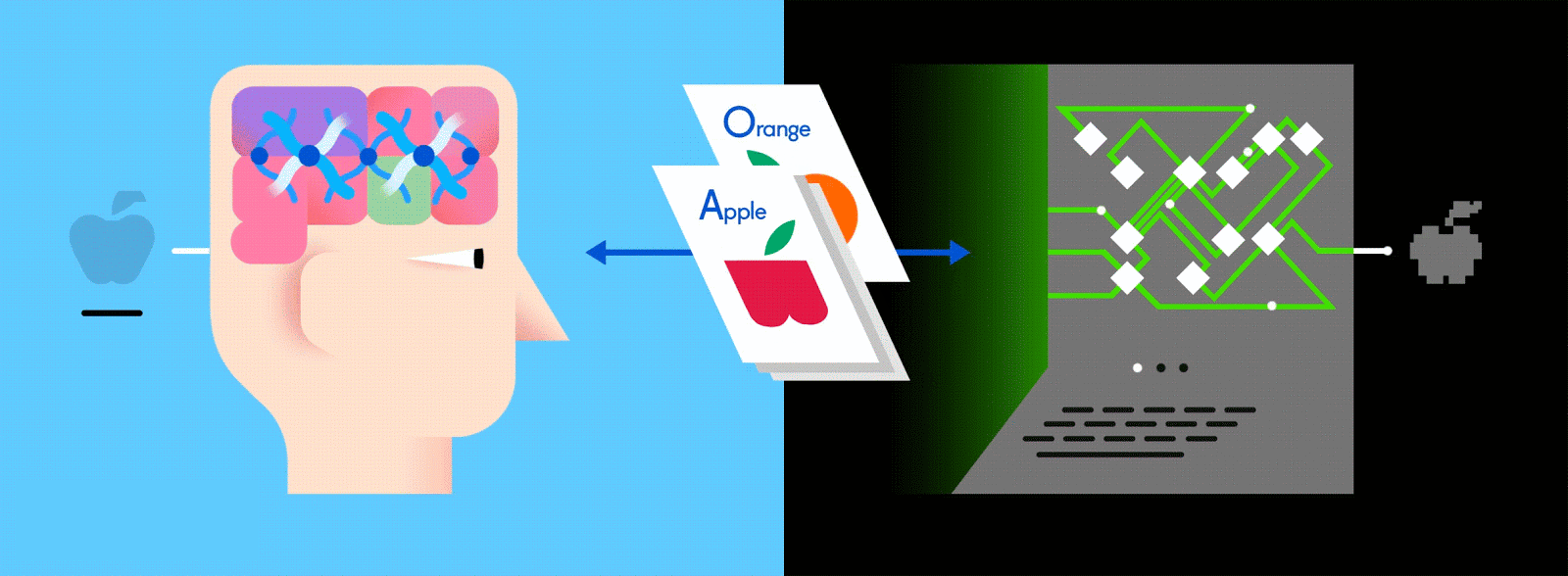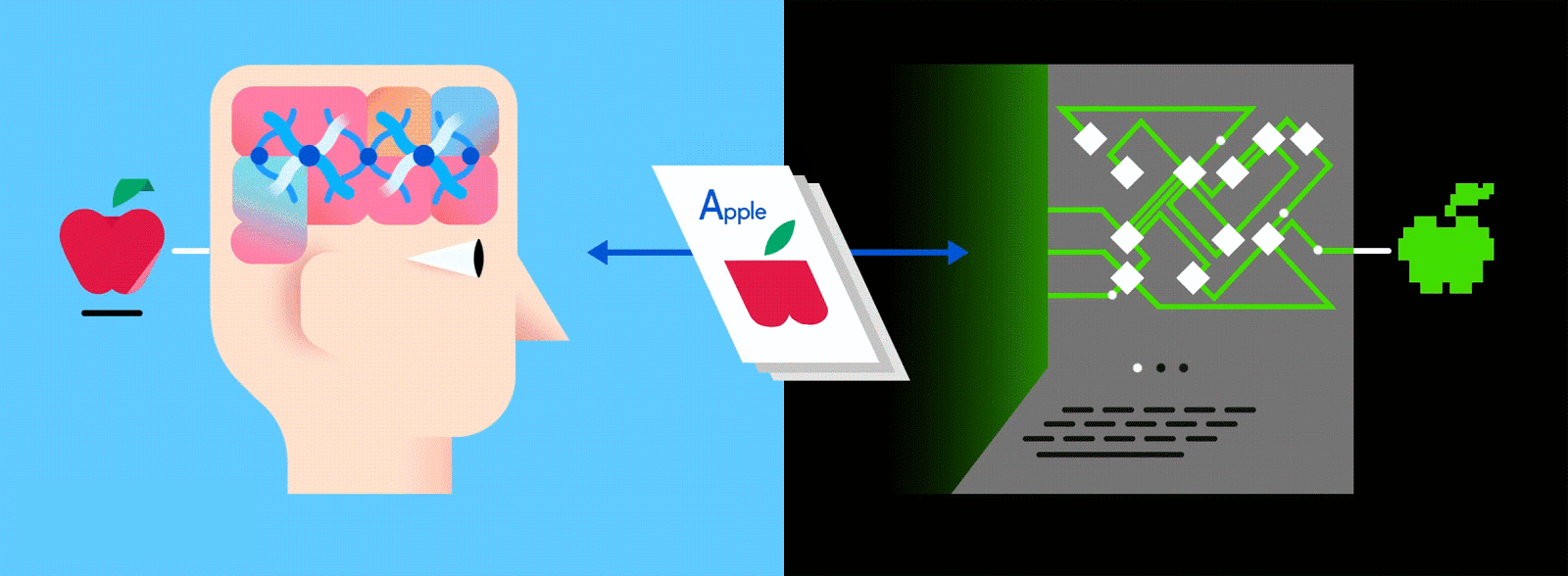
出典: GumGum
今日の機械学習では、この多層型のANNが広く利用されており、そこに大量のラベル付きのデータを与えることで、AIがそのデータを人間のように(ときには人間よりも上手く)理解できるようになる。
現実世界で親が子どもにリンゴとオレンジの見分け方を教えるときのように、コンピューターも練習を積めばふたつを見分けられるようになるということだ。
例えば画像認識においては、畳み込みニューラルネットワーク(Convolutional Neural Network=CNN)というタイプのニューラルネットワークが使われている。数学の畳み込みと呼ばれるプロセスから名前がつけられたCNNは、一部が見づらくなっている物体や一定の角度からしか見えないような物体が含まれている画像も非線形解析することができる(他にも再帰型ニューラルネットワークや順伝播型ニューラルネットワークなど、さまざまなタイプのものが存在するが、これらのニューラルネットワークは私たちが以下の例で取り上げている画像認識には向いていない)。
トレーニングの流れ
それではニューラルネットワークはどのように学習するのだろうか?極めてシンプルかつ効果的な、教師あり学習という手法を見てみよう。この手法では、ニューラルネットワークに人間がラベル付けした大量のトレーニングデータが与えられるため、ニューラルネットワークは自分で答え合わせができるようになっている。
リンゴとオレンジというラベルが付いた画像で構成されたトレーニングデータを思い浮かべてみてほしい。画像がデータ、それぞれの画像に対応している”リンゴ”、”オレンジ”という名前がラベルだ。トレーニングデータを受け取ったニューラルネットワークは、それぞれの画像を細かな要素(エッジ、テクスチャ、形など)に分解し始める。そして画像がネットワーク中を伝播していく中で、それらの要素が組み合わさって抽象的な概念を構築していく。曲線や色に関する情報が合わさって、茎やオレンジ、緑・赤のリンゴという絵が浮かび上がってくるといった具合だ。
このプロセスが終わると、ネットワークは画像に何が写っているかについての予測を立てようとする。そもそもまだ何も学習していないので、最初はこの予測が全くの当てずっぽうのように見えるだろう。そして、入力された画像がリンゴなのに、ネットワークがオレンジと予測したとすれば、ネットワーク内のレイヤーに修正を加えなければならない。
バックプロパゲーション(または誤差逆伝播法)と呼ばれるプロセスを通じて修正が行われると、次に同じ画像が与えられたときに、ネットワークがその画像をリンゴだと判断できるようになる確率が上がる。この作業は予測がほぼ正確になり、改善の余地がなくなったと感じられるくらいまで繰り返される。現実世界で親が子どもにリンゴとオレンジの見分け方を教えるときのように、コンピューターも練習を積めばふたつを見分けられるようになるということだ。もしもこの時点で「あれ、これって機械が何かを学んでるんじゃないかな?」と感じた人がいれば、その人はAIの分野で働けるかもしれない。
レイヤーに次ぐレイヤー
一般的に、畳み込みニューラルネットワークには、入出力用のレイヤーを除いて以下の4つのレイヤーが必ず含まれている。
- 畳み込み層
- アクティベーション層
- プーリング層
- 全結合層
畳み込み層
最初の畳み込み層(複数の畳み込み層が重なっていることもある)では、何千個ものニューロンが第一のフィルターとして機能し、画像内の各ピクセルにスコアを付けながらパターンを見つけようとする。処理された画像の数が増えるにつれて、それぞれのニューロンが画像の特徴的な箇所をフィルタリングするようになり、精度が向上していく。
リンゴを例にとると、あるフィルターは赤い色を探している一方で、別のフィルターは曲がったエッジを探し、さらに別のフィルターが細い棒のような茎を探しているかもしれない。引っ越しやガレージセールのために、散らかった倉庫を片付けたことがある人(もしくは業者に片付け作業をお願いしたことがある人)であれば、モノをまとめて(本、おもちゃ、電子機器、アート、服などへ)分類していく作業についてよく知っていることだろう。畳み込みレイヤーも同じような作業を通じて、画像をピクセルの特徴ごとにバラバラにしていっているのだ。
ニューラルネットワークの利点のひとつは、非線形学習ができることだ。
ニューラルネットワークが有名になった要因のひとつで、これまでのAI手法(Deep Blueなど)とは異なる強力な特徴として挙げられるのが、前述のようなフィルターを人間がつくる必要がないということだ。つまりネットワーク自体が、データを解析しながら処理方法を改善していくのだ。
畳み込み層の役割は、特徴マップと呼ばれる、もともとの画像がフィルターごとに分解されたものを生成することだ。そして特徴マップには、各ニューロンが画像のどの部分で赤い色や茎、曲線といったリンゴを特徴付ける要素を(どんなに部分的であっても)発見したかという情報が含まれている。しかし、畳み込み層はかなり自由に特徴を検知するようになっているため、画像がネットワーク内を伝播していく中で見落としがないか確認するような仕組みが必要になってくる。
アクティベーション層
ニューラルネットワークの利点のひとつは、非線形学習ができることだ。これはどういうことかと言うと、あまりハッキリと表れていない特徴も見つけることができるということだ。つまり、リンゴの木の写真に写った直射日光を受けているリンゴや影に隠れたリンゴ、さらにはキッチンカウンターのボールの中に山積みになったリンゴもニューラルネットワークを使えば認識することができる。これは全て、明らかなものも見つけにくいものも含め、重要な特徴をハイライトするアクティベーション層のおかげなのだ。
先述の片付けの様子を思い浮かべてほしい。今度は分別を終えた山の中から、珍しい本や今となっては皮肉にさえ見えるような学生時代に着ていた懐かしいTシャツなど、やっぱり残しておきたいと感じたお気に入りのモノを抜き出すとしよう。これらの”もしかしたら”というモノを、後で見直せるようにそれぞれの山の上に置いておくというのが、アクティベーション層の役割だ。
プーリング層
画像全体に”畳み込み”を行った結果、かなりのボリュームの情報が生成されるので、すぐに計算が面倒になってしまう。そこでプーリング層を使うことで、膨大な量のデータをもっと処理しやすい形に変換することができる。やり方はさまざまだが、もっとも人気のある手法が”マックスプーリング”だ。マックスプーリングを行うと、畳み込みで生成された特徴マップの要約版のようなものが作られ、赤い色や茎っぽさ、エッジの曲がり具合といった特徴がもっともハッキリと表れている部分だけが残される。
再度片付けの例を引っ張りだし、片付けコンサルタントとして有名な近藤 麻理恵氏の哲学を応用すれば、それぞれの山のお気に入りのモノの中から本当に”ときめく”モノだけを選んで、残りは全て売るか捨てるというのがプーリング層の役割だ。そうすると、本当に大切なものだけがカテゴライズされたままで手元に残ることになる(ちなみに、ニューラルネットワークの中で起きるフィルタリングやコンパクト化の作業の理解を促すための、片付け作業を用いた説明はここで終わりだ)。
ニューラルネットワーク設計者は、残りのレイヤーも同様に畳み込み層・アクティベーション層・プーリング層と積み重ねていくことで、より次元の高い情報だけ残すことができる。リンゴの画像で言えば、最初はほとんど認識できなかったようなエッジや色や茎も、何層にも重なり合ったレイヤーを通過していくうちに、その姿がハッキリと浮かび上がってくる。そして最終的な結果が出る頃に、全結合層が登場する。
出典: GumGum
全結合層
そろそろ答え合わせの時間だ。全結合層では、コンパクト化された(もしくは”プール”された)特徴マップが、ニューラルネットワークが認識しようとしているモノを表す出力ノード(またはニューロン)に”全て結合”される。もしもネコ、イヌ、ギニアピッグ、スナネズミを見分けることがネットワークのゴールであれば、出力ノードは4つになる。私たちの例で言えば、出力ノードは”リンゴ”と”オレンジ”のふたつだ。
もしも、トレーニングをある程度経て既に予測精度が上がってきたネットワークにリンゴの画像が入力された場合、特徴マップのほとんどにはリンゴの特徴をハッキリと示す情報が含まれているはずだ。ここで最後の出力ノードが逆選挙のような形で、その役目を果たすことになる。
新しい画像がネットワーク内を伝播したときの認識精度が上がるように、それぞれのレイヤーのニューロンに修正が加えられる。
リンゴとオレンジの出力ノードの(”オンザジョブ”で学習した)仕事は、それぞれの果物の特徴を示す特徴マップに”投票”することだ。つまり、ある特徴マップに含まれるリンゴの特徴が多ければ多いほど、その特徴マップに対するリンゴノードの投票数は多くなる。そしてどちらのノードも、それぞれの特徴マップが含んでいる情報に関係なく、全ての特徴マップに対して投票しなければならない。そのため、トレーニングが進んだニューラルネットワーク内では、全ての特徴マップに対するオレンジノードからの投票数が少なくなる。というのも、特徴マップにはオレンジの特徴がほとんど含まれていないからだ。最終的に投票数の1番多いノード(この場合で言えばリンゴノード)が、このネットワークの”回答”となる。実際にはもっと複雑だが、大体このようなプロセスでニューラルネットワークは画像を処理している。
同じネットワークがリンゴとオレンジという別のモノを認識しようとしているため、最終的なアウトプットは、「リンゴ:75%」「オレンジ:25%」といった感じで確率で表示される。もしもトレーニングが不十分でネットワークの精度が低ければ、「リンゴ:20%」「オレンジ:80%」といった結果が表示される可能性もある。
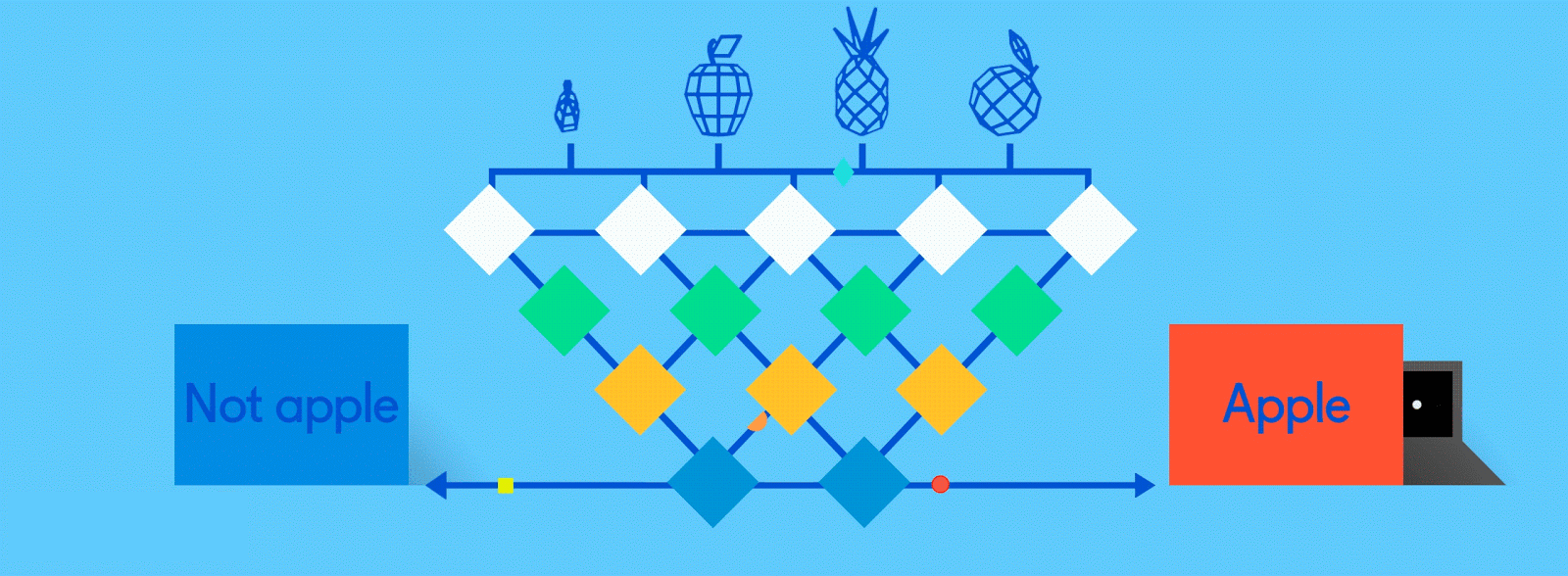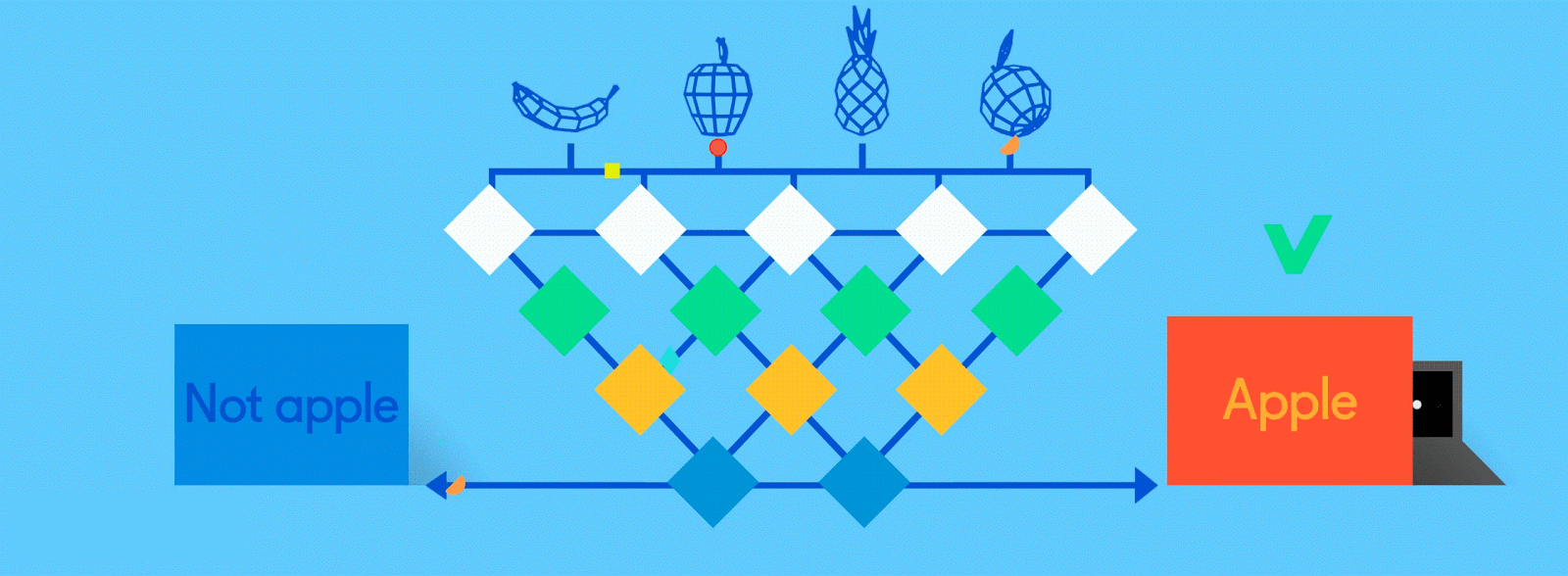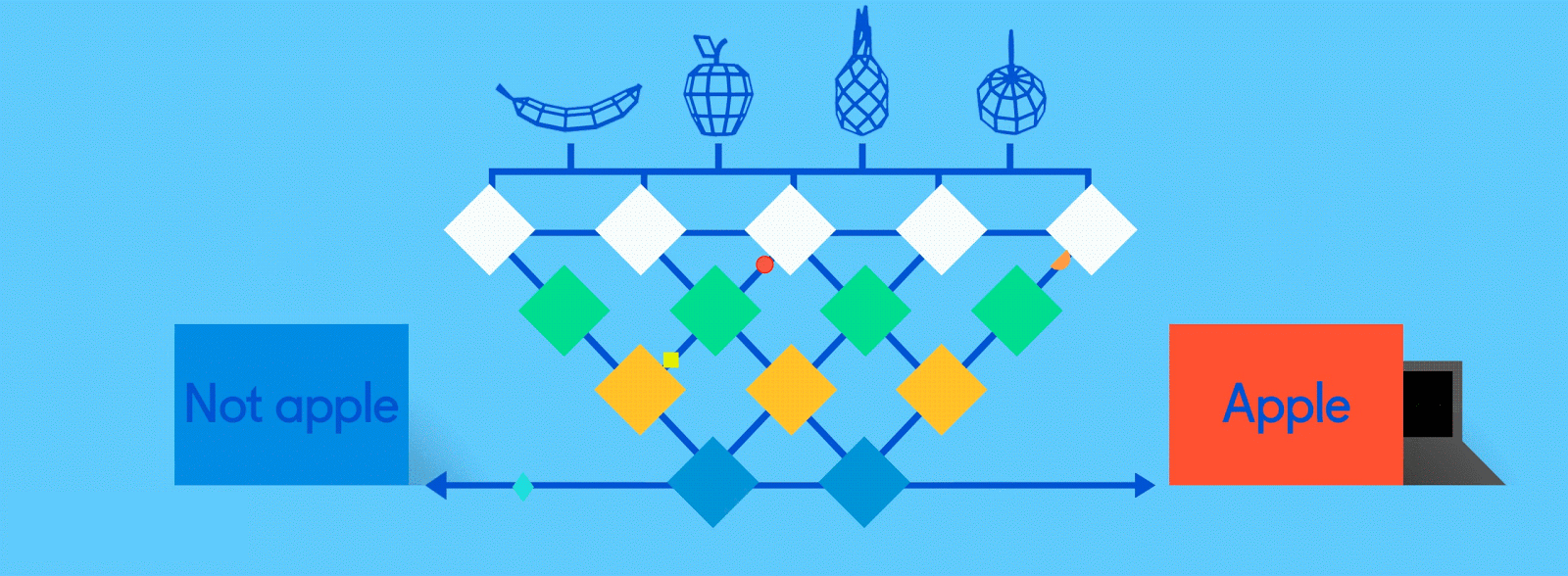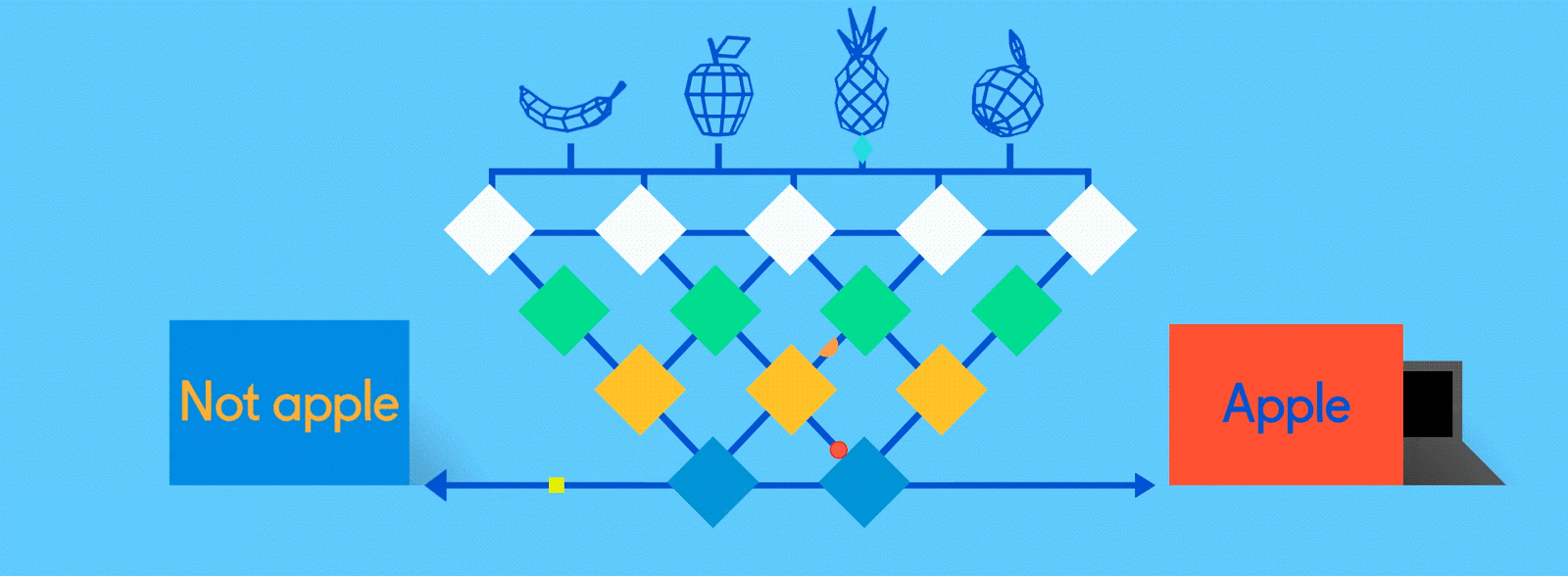
出典: GumGum
答えが間違っていれば繰り返しあるのみ
初期の段階にあるネットワークでは、不正解が続出するのが普通だ。「リンゴ:20%」「オレンジ:80%」というのは完全な間違いだが、ここではラベル付きのデータを使った教師あり学習を採用しているため、ネットワークはバックプロパゲーションを使い、どこでどのように間違ったかというのを自動的に解析できるようになっている。
冒頭の約束通り数学無しで説明すると、バックプロパゲーションとは、あるレイヤーのノードがひとつ前のレイヤーのノードに対して、自分たちの回答と実際の答えがどのくらいかけ離れていたかを伝える仕組みを指している。後ろのレイヤーからのフィードバックを受け取ったレイヤーは、さらにもうひとつ前のレイヤーに情報を伝え、その後も伝言ゲームのように畳み込み層まで情報が伝わっていく。そして新しい画像がネットワーク内を伝播したときの認識精度が上がるように、それぞれのレイヤーのニューロンに修正が加えられることになる。
その後も、ネットワークがリンゴとオレンジを100%の確率(多くのエンジニアは85%を許容値としているが)で当てられるようになるまで、このプロセスが何度も繰り返される。そしてトレーニングが完了すれば、そのネットワークは晴れてプロとして、リンゴとオレンジを認識する仕事に就くことができる。
*GoogleのAI囲碁プログラムAlphaGoは、ニューラルネットワークを使って盤面を評価しながら最終的に人間の棋士を破ったが、Deep Blueは人間によって記述された指示を基に戦っていたという点で異なる。
[原文へ]
(翻訳:Atsushi Yukutake/ Twitter)