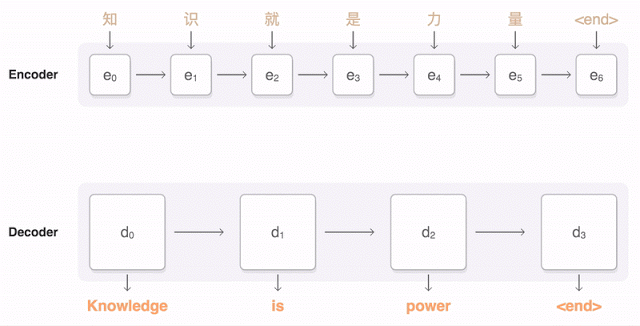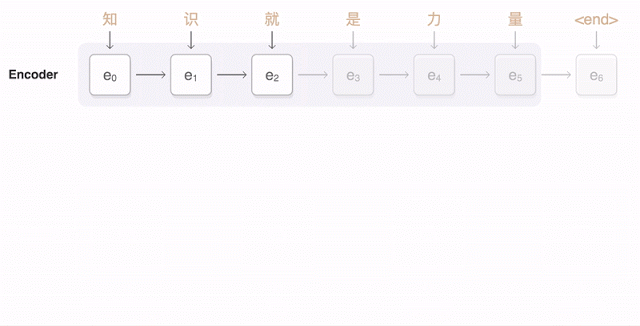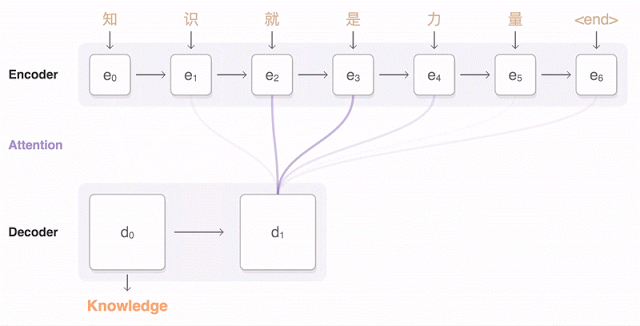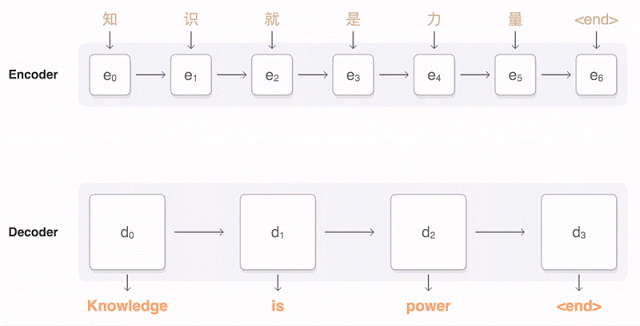
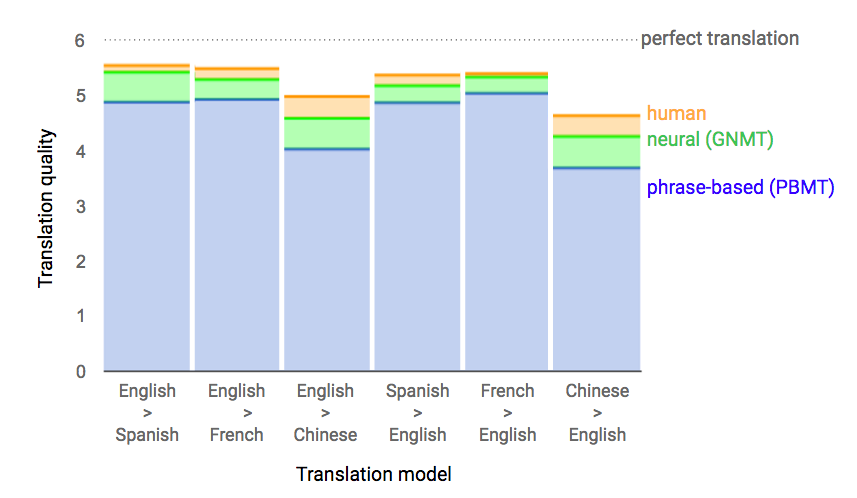
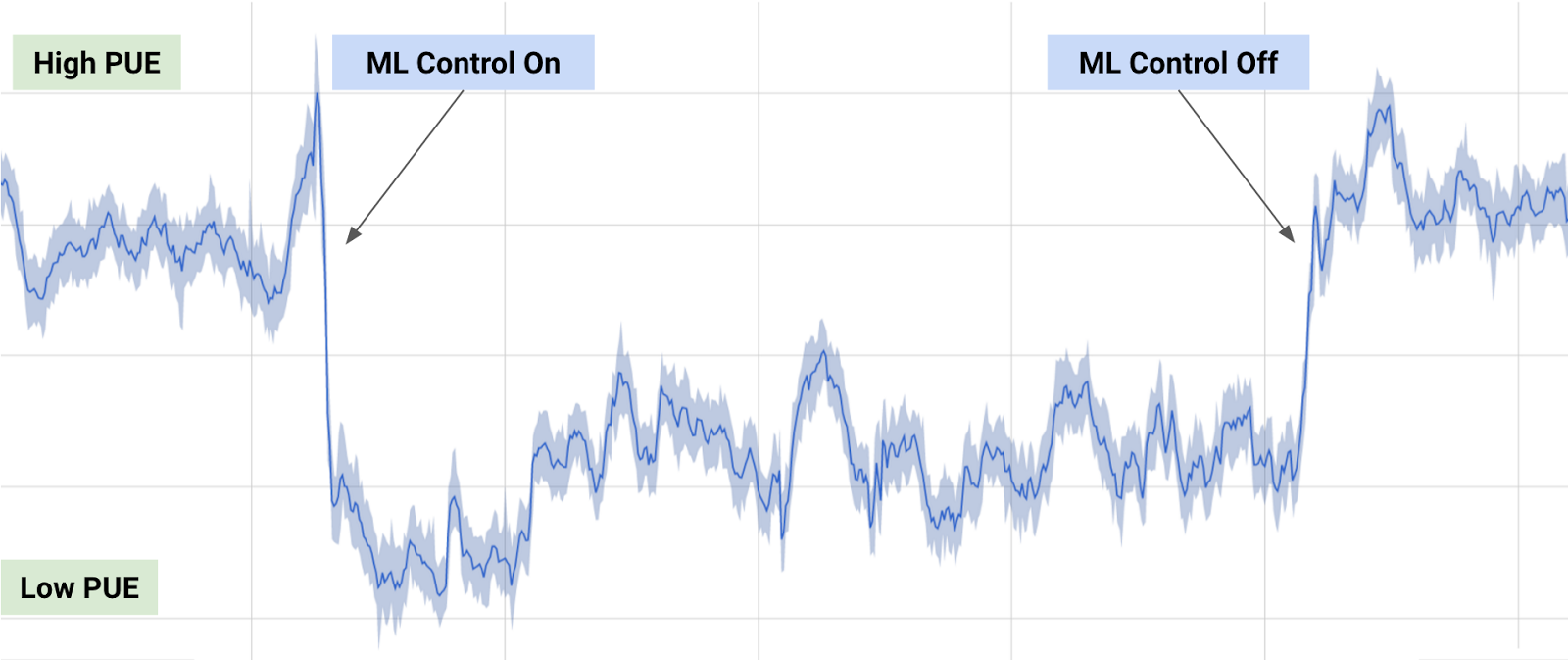
【編集部注】著者のAmir ShevatはSlackの開発者リレーションの責任者。
ボットは私たちの生活の一部になってきている。朝目覚めると、私はAlexaにブラジルのサンバを再生するように伝え、Amyにミーティングのセットアップを任せ、Slackで現在の状況とレポートを知る。ボットビルダーたちと同様にユーザーたちも、ボットが私たちの生活の不可欠な一部であることを理解し始めている。しかし、これらの新しいハイテク友人たちを支配するルールは何だろう?
所有権

人びとが訊ねるべきでありながら、結局訊ねることのない1つの大きな質問は、「このボットは私をサーブしているのか?あるいはサービスプロバイダーをサーブしているのか?」というものだ。言い換えれば、「このボットは私の関心を中心に振る舞っているのか、それとも他の誰かの関心が中心にあるのか?」ということだ。食品注文ボットは高価だったり/低品質だったりするアイテムを推薦してくるのか、あるいは最適価格の高品質食品をお勧めしているのか?人事部(HR) ボットは私をサーブしているのか、それとも会社なのか?保険ボットは保険金請求を行おうとする私を手助けしてくれるのか、それともそれを妨害しようとしているのか?
知的財産権の問題も存在している:ボットによって作られた、あなたの写真をコラージュに仕立てた作品/写真は、誰が所有しているのか?あなたのショッピングの嗜好を所有しているのは誰なのか?
パーソナルアシスタントボットはユーザーの立場でヒントを出し、一方業者代理ボットに話しかければ、業者の立場でヒントが出されてくる。ユーザーとサービスプロバイダの違いは常に明らかとは言えず、またしばしば想定もされなければ、考えられることもない。GmailやFacebook上の写真を考えてみよう ‐ 誰がそのデータを所有しているのか?同じ質問は私たちのボットにも向けられる。
私の所有権に対する立場は – 私はユーザーによる所有権に意味がある場合もあれば、サービスプロバイダーが所有権を明確に主張できる場合もあると考えている。
鍵となるのは、誰が何を所有していて、どれが利用者の選択によって提供されているサービスなのかが、明確で透明であることだ。
プライバシー

所有権がどうであるかに関わらず、プライバシーの問題が存在する。あるボットは、情報を他のボットや人間の監督者と共有することができるのか?情報は匿名化されるべきか?ユーザーは忘れられる権利を持っているのか?基本的に、ユーザー/ボット間に機密保持契約はあるのか?
プライバシーに対する私の立場は ‐ 特に断りのない限り、ボットは暗黙的にあなた個人のプライベートな情報を機密として扱うように委託されたものと考える(Chris Messinaは、法執行機関の行為や緊急避難の際には幾つかの例外があることを指摘してくれた)。透明性も同様に鍵となる。Slackにボットを投入する際には、私たちは開発者に対してプライバシーポリシーを作成し、公表することを要求している。
一般的に ボットビルダーは、ユーザ情報を可能な限りプライベートな状態に維持する必要がある。
広告のためのデータの使用
これは、プライバシーと所有権のサブセットであり、かつ議論の対象として非常に重要なトピックである。ボットビルダーたちは、今もまだボットを収益化する方法を模索している…ならば、ボットは広告を配信することはできるのだろうか?広告を最適化するために、直接またはAPIを介して、ボットはあなたの提供したデータを使用することはできるのだろうか?
広告に対する私の立場は – 私は、ユーザーに利益をもたらす強烈で明示的な目的がないかぎり、ボットは広告を表示すべきではないと考えている。例えB2Cプラットフォームに限ったとしても。私は ボットが、新しいトラッキングピクセルになるところを見たくない。ボットは、明示的にそうするように指示されない限り、何かをクリックして購入するようにユーザーを促すべきではない。
罵倒と共感

このトピックは、おそらく独立した記事を必要とするだろう。ボットの会話特性のために、彼らははるかに罵倒の対象になりやすい。Botnessと呼ばれるボットビルダーの集会では、ほとんどのボット開発者が、人びとはあらゆる種類の罵倒を試みると報告している。ボットを呪う言葉を投げつけるとことから実際にボットに被害を与えるところまで。
これは重いトピックであり、双方向の課題である。
ボットは罵倒対象なのか?
ボットは他の物体と同じようなものなのか?彼らは、現代社会の新たな「サンドバッグ」なのだろうか?ボットは人間にとって呪いと罵倒の対象なのだろうか?
ボットの罵倒に対する私の立場は ‐ 「罵倒できる」ことと「罵倒する」こと、私は両者に微妙な違いを観る。少なくともAIが個性と感情を手に入れるまでは、あなたは本当の意味でボットを罵倒することは「できない」。 ボットは気にもせず、あなたの呪いの言葉も、ユーザーが入力しがちな他のちんぷんかんぷんな文言と一緒にフィルタリングされるだけだ。一方私は社会として、私たちはボットを罵倒してはならないと思っている。ボットを罵倒することで、人間は他人に対しても罵倒を行い易くなると考えている。これは明らかに困ったことだ。
人間はサービスを共感をもって扱うべきだ – 一般的に、共感を失うことは、人間にとって悪い傾向なのだ。開発者は如何なる罵倒の言葉も、無視するか、丁寧に包まれた反応で対応する必要がある。
ボットが人間を罵倒する必要があるのか?
ボットは人間にスパムを送ったり嫌がらせをすることはできるのか?ボットは人間に害を与えることはできるのか?あるいは口答えをしたり?ボットは呪いの言葉を投げ返す必要があるのか?ソフトウェアは、自分自身を守るための権利を持っているのか?
攻撃的なボットに対する私の立場は – 私はすでにボットは人間に害を与えるべきではないことを物語る事実について書いている;そこには、スパム、ハラスメント、その他の色々な形の痛みが含まれている。私はボットもAIも同じように、こうしたタイプの攻撃を正当化できる理由はないと考えている(セキュリティに関する議論はまた別にある)。また、私は正面からユーザーに答えようとすることが、人間の攻撃性を和らげる最も効果的な方法だとも思っていない;単純に「そのリクエストは処理できません」と返したり、人間の罵倒を単に無視したりすることの方が、より効果的なUXとなるだろう。
一般的に、私は会話インタフェース内の共感が、ボットのデザインと、よくあるベストプラクティスの柱の一つであるべきだと思っている。
ジェンダーと多様性
ボットは女性のボットまたは男性のボットであるべきだろうか?人種的に多様なボットを持つ必要があるだろうか?宗教的に多様なボット持つ必要は?
ジェンダーと多様性に関する私の立場は – 私は、開発者は多様性についてとても真剣に考えるべきだと思っている。ボットは性別を持つべきではないと思うボット開発者もいる – これは英語圏の国では上手くいくかもしれないが、その他の多くの言語圏では上手くいかない。すべてのものが性別を持っている言語が沢山存在している – 物体や人物を性別に言及することなく参照することができないのだ。だから、英語ボットは「it」で良いかもしれないが、多くの国ではそうではない。
会話UIは人間に向かい合うことを想定しているので、ユーザーは性別スペクトル上のどこかにボットを位置づけようとする (他の多様性の属性も同様だ)。
開発者は何をすべきか?私は、もし可能なら、開発者はユーザーにボットの性別(およびその他の多様性の属性)を選択できるようにすべきだと思う。その例の1つが、x.aiのAmy/Andrewボット構成だ。
人間-ボット/ボット-人間のなりすまし
私が話している相手は、ボットなのか、それとも人間なのか?このボットは、人間のように行動しようとしているのか?ユーザーは、人間またはソフトウェアに話しかけているという事実について、知っているまたは気にすべきなのだろうか?
「人間なりすまし」に対する私の立場は – エンドユーザーにとって、人間に対して話しているのか、それともボットに対して話しているのかの区分がとても重要である主要なユースケースが、健康から金融まで沢山存在していると思っている。
一般的には、透明性がベストプラクティスだと考える。そして人間は(一般的なガイダンスとして)ボットのふりをするべきではない(その逆に関しても同じである)。
透明性と共感が、すべての問題への解決策
以上に挙げた課題のほとんどは、今日業界では対応が行われていない。もちろん悪い意図からそうなっているわけではなく、単に意識の欠如によるものだ。共感性と透明性を念頭に、開発者がこれらの問題に対処すれば、楽しく倫理的な体験をユーザーに提供することができるだろう。
[ 原文へ ]
(翻訳:Sako)
FEATURED IMAGE: YAGI STUDIO/GETTY IMAGES