
今年の初め、起業家で投資家のサム・アルトマン(Sam Altman)氏は、Y Combinatorの社長という注目される役職を離れ、OpenAIのCEOとなった。OpenAIは2015年の末にハイテク業界の最も著名な人たちによって設立されたAI研究組織である。この組織が目指すのは、創業者の1人であるイーロン・マスク(Elon Musk)氏がニューヨークタイムズへ回答したように、人工知能が「安全な方法で開発され、人類にとって有益なものであること」を確実にすることだ。
この動きは多くの意味で興味深いものである、なにしろ汎用人工知能(あるいは機械が人間に並べるくらい賢くなる能力)はまだ存在しておらず、AIのトップ研究者たちでさえ、それがいつになるのかについてはっきりとはとても言えないのだから。アルトマン氏のリーダーシップのもとで、もともとは非営利組織だったOpenAIは、「これからの数年のうちに大規模クラウドコンピューティング、才能ある人材の確保、そしてAIスーパーコンピューターの開発に対して数十億ドル規模の投資をする必要がある」というコメントを発しつつ、利益を目指す企業として組織変更を行った。
OpenAIが、それほどまでに多額の資金を集めることができるかどうかはまだわからないが、私たちはもしそれが実現されるとしたら、アルトマン氏自身の力によるものだろうと予想している。5月16日夜にステージ上で行われた、YCの進化からOpenAIでのアルトマン氏の現在の仕事までを網羅した拡大インタビューは、観衆をあっという間に魅了する力があった。
例えばYCでは、リーンネスと「ラーメン代がまかなえる利益率」が、一般的なアクセラレータープログラムの卒業生たちが目指すゴールだった時代もあったことを語り合った。しかし最近のゴールはすぐにでも数百万ドル、あるいは数千万ドルをベンチャーファンドから調達することになっているように思える。
「もし私が市場をコントロールすることができるなら、明らかに自由市場は勝手に進んで行きますが、私はYC企業たちには調達しようとしている金額や評価額を上げさせないでしょう」とアルトマン氏はこの小さな業界向けイベントの中で聴衆に語りかけた。「一般的に、それはスタートアップにとって良くないことだと思っているのです」。
アルトマン氏はまた、個人的だったり時に陳腐だったりする質問を投げかけられても率直に答えていた。さらには、このイベントのためにたまたま街にいた母親との、長期にわたる親密な関係についての話まで提供してくれた。彼は、彼女が「絶対に」信頼しているほんのひと握りの人々の一人だと語っただけでなく、その小さな輪の外の人々からの率直なフィードバックを得ることが、時間とともに難しくなっていることを認めた。「キャリアのある時点になると、人びとがあなたの気分を害したくないと思ったり、あなたが聞きたくないような話をしたくないと思ったりするようになります。もちろんこの時点で私が手にしているものは、フィルターがかけられ事前に計画されたものであることを、私ははっきりと意識しています」。

確かに、アルトマン氏は、多くの人たちよりは動き回れる範囲が大きい。このことはアルトマンがY Combinatorを5年にわたって運営したやり方(基本的に何度も規模を拡大した)から明らかなだけではなく、OpenAIについての彼の議論の仕方からも、彼の現在の思考が一層大胆なものであることは明白である。確かに、木曜日の夜にアルトマン氏が語ったことは、もし他の誰かが語ったならば、単なるたわごととみなされるようなものが多かった。アルトマン氏が語ることで、聞く者が驚かされることになるのだ。
例えば、OpenAIがどのように収益を上げることを計画しているのか(私たちは、成果の一部にライセンスを設定するのかを知りたいと思っていた)という質問に、アルトマン氏は「正直な答は『まだ何もない』ということです。私たちはいかなる収益も上げたことがありませんし、現段階では収益を上げる計画もありません。一体どうすれば、いつの日か収益を上げられるようになるのかがわからないのです」と答えている。
アルトマン氏は続けて、次のように述べた「私たちは投資家の皆さんに『もし汎用人工知能を開発できたら、それに対して投資家の皆さんにリターンを行う方法を考えて欲しいと依頼するつもりです』という、厳しくない約束をしているのです」。聴衆が爆笑したときに(なにしろ彼が真剣なのだとは思えなかったのだ)、アルトマン氏はこれはまるでドラマの「シリコンバレー」のエピソードのように聞こえるかもしれないと言いつつも「もちろん笑っていいんですよ。全然構いません。でも、それは本当に私が信じていることなのです」と付け加えた。
またアルトマン氏のリーダーシップの下で、OpenAIは投資家に最大100倍の利益を還元してから余剰利益を他に分配する、「上限利益」(capped profit)企業となったが、それは何を意味するのかという質問も行われた。私たちはその100倍という数字がとても高い目標であることに注目している。なにしろ旧来の営利企業に投資する投資家たちが、100倍近いリターンを得ることなどは滅多にないからだ。例えば、WhatsAppに対する唯一の機関投資家であるSequoia Capitalは、Facebookに220億ドルで売却したときに、同社が投資していた6000万ドルの50倍のリターンを得たと報じられた。素晴らしいリターンだ。
しかしアルトマン氏は、「上限利益」が、ちょっとしたマーケティング上の工夫であるという意見に反論し、なぜこれが理にかなっているのかについて改めて強調した。より具体的に言えば、彼は汎用人工知能がもたらす機会はとてつもなく巨大であり、もしOpenAIがなんとかこの扉をこじ開けられたとするならば、おそらく「光円錐内の宇宙の、すべての未来の価値を取り込むことができてしまいます。そうなったときに、特定の投資家のグループだけがその価値を独占することは正しいことではありません」と語った(光円錐というのは相対論の中に出てくる用語だがここでは「未来の人類に手の届く全宇宙」といった程度の意味)。
彼はまた、将来の投資家たちは、投資に対するリターンがさらに低く抑えられることになると語った。これは基本的に、リスクをとってくれた初期の投資家たちに、OpenAIが報いたいと思っているからだ。
インタビューを終える前に、私たちはアルトマン氏に対して、AI研究者たちによるさまざまな批判を投げかけてみた。これらの批判は今回のインタビューに先立って行われたもので、特にOpenAIは定性的なものへ注力しており、既に証明された成果の中での根本的な飛躍を目指しているものではないというもの、そしてその「安全」な汎用人工知能を発見するという使命は、不必要に警戒心を煽り、研究者たちの仕事をより難しくしてしまうというものだ。
アルトマン氏はそれぞれの点に対して熱心に回答した。彼はそれらの意見をまったく否定することはしなかった。例えば、OpenAIに対する最も人騒がせな意見に関しても「その中には共感できる部分もあります」と述べた。
それでもアルトマン氏は、たとえ不毛と思う人がいたとしても、人工知能の潜在的な社会的影響について考え、そしてメディアと話し合うために、よりよい議論がなされるべきだと主張した。「OpenAIは恐怖を煽って商売につなげていると言って批判している同じ人が、一方では『Facebookはこれをやらかす前に考えておくべきだったんじゃないか?』と言っています。何かをやってしまう前に、私たちも考えたいと思っているのです」。
インタビュー全体は以下から見ることができる。会話の前半は、主に(現在も会長を務める)YCでのアルトマン氏の経歴に集中している。OpenAIに関する詳細な話は26分付近から始まっている。
画像クレジット: Sara Kerr / StrictlyVC
[原文へ]
(翻訳:sako)















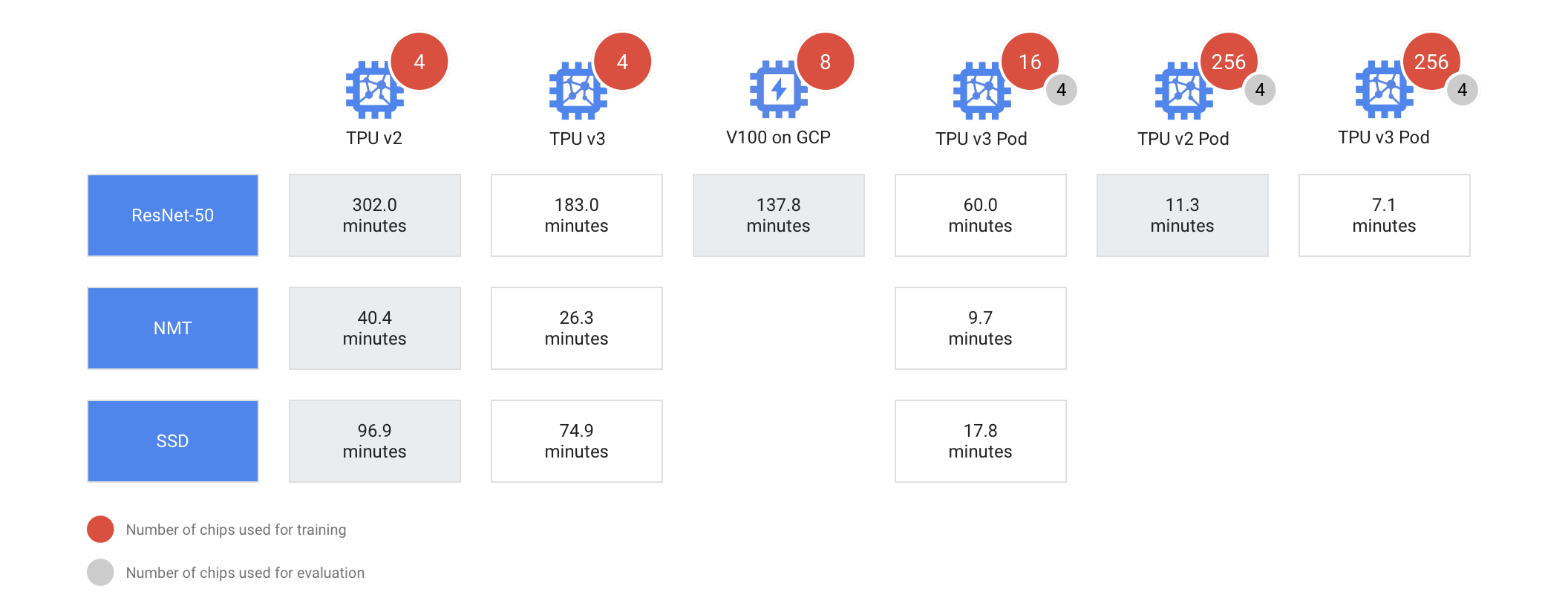
 現在、栄光(栄光ゼミナール)、学研塾ホールディングス、ティエラコムをはじめとする500以上の教室に導入されており、各教室で集めたデータを基にアルゴリズムやコンテンツが日々最適化されているとのこと。今年からは、駿台教育センターでは「AI演習講座」、Z会エデュースでは「AI最速定着コース」、城南進学研究社では「城南予備校DUO」として、atama+に特化したAI学習コースも開設されている。
現在、栄光(栄光ゼミナール)、学研塾ホールディングス、ティエラコムをはじめとする500以上の教室に導入されており、各教室で集めたデータを基にアルゴリズムやコンテンツが日々最適化されているとのこと。今年からは、駿台教育センターでは「AI演習講座」、Z会エデュースでは「AI最速定着コース」、城南進学研究社では「城南予備校DUO」として、atama+に特化したAI学習コースも開設されている。 atama+の教材は、高校生向けに数学・英文法・物理・科学、中学生向けに数学がある。平均学習完了時間は、高校の「数I」で16時間、「数A」で15時間とのこと。なお、文部科学省が告示している教育課程の基準である学習指導要領では、これらの授業時間は計175時間。学習と授業は同じ尺度で測れないが、AIによる効率化で学習成果を短時間で出せるのがatama+の特徴となっている。
atama+の教材は、高校生向けに数学・英文法・物理・科学、中学生向けに数学がある。平均学習完了時間は、高校の「数I」で16時間、「数A」で15時間とのこと。なお、文部科学省が告示している教育課程の基準である学習指導要領では、これらの授業時間は計175時間。学習と授業は同じ尺度で測れないが、AIによる効率化で学習成果を短時間で出せるのがatama+の特徴となっている。 具体的には、中学生や高校生の学習のつまずきの根本になっている単元をAIが突き止め、何を、どんな順番で、どのくらいの量やればいいかをナビゲートしてくれる。例えば、高校物理の「波の式・波の干渉」を学習する場合、「波の基本要素・波のグラフ」の講義動画や数学「三角比の定義」の演習問題等がレコメンドされるといった具合だ。
具体的には、中学生や高校生の学習のつまずきの根本になっている単元をAIが突き止め、何を、どんな順番で、どのくらいの量やればいいかをナビゲートしてくれる。例えば、高校物理の「波の式・波の干渉」を学習する場合、「波の基本要素・波のグラフ」の講義動画や数学「三角比の定義」の演習問題等がレコメンドされるといった具合だ。












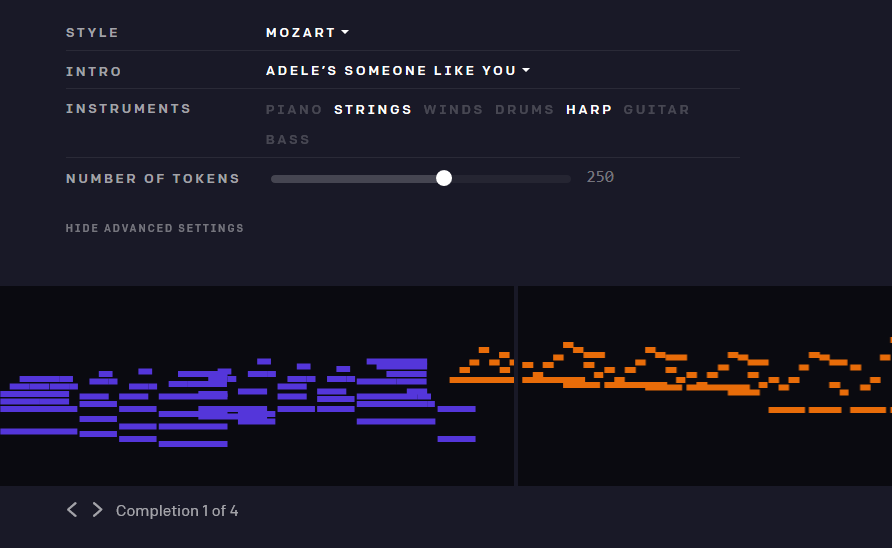 とはいえ、アデレのような雰囲気のものを、彼女の特徴的な声なしに生み出すのは少し難しい。そしてチームが選択した比較的基本的な合成手法は全体的に効果を安っぽくしている。そして、チームがTwitch上で提供した「ライブコンサート」を聴いても、MuseNetが次のヒットを量産してくれるとは、私には思えなかった。だがその一方で、特に少々の調子外れが許容される、ジャズやクラシックの即興演奏では、素晴らしい進歩を着実に挙げている。
とはいえ、アデレのような雰囲気のものを、彼女の特徴的な声なしに生み出すのは少し難しい。そしてチームが選択した比較的基本的な合成手法は全体的に効果を安っぽくしている。そして、チームがTwitch上で提供した「ライブコンサート」を聴いても、MuseNetが次のヒットを量産してくれるとは、私には思えなかった。だがその一方で、特に少々の調子外れが許容される、ジャズやクラシックの即興演奏では、素晴らしい進歩を着実に挙げている。






 Walmartでは
Walmartでは