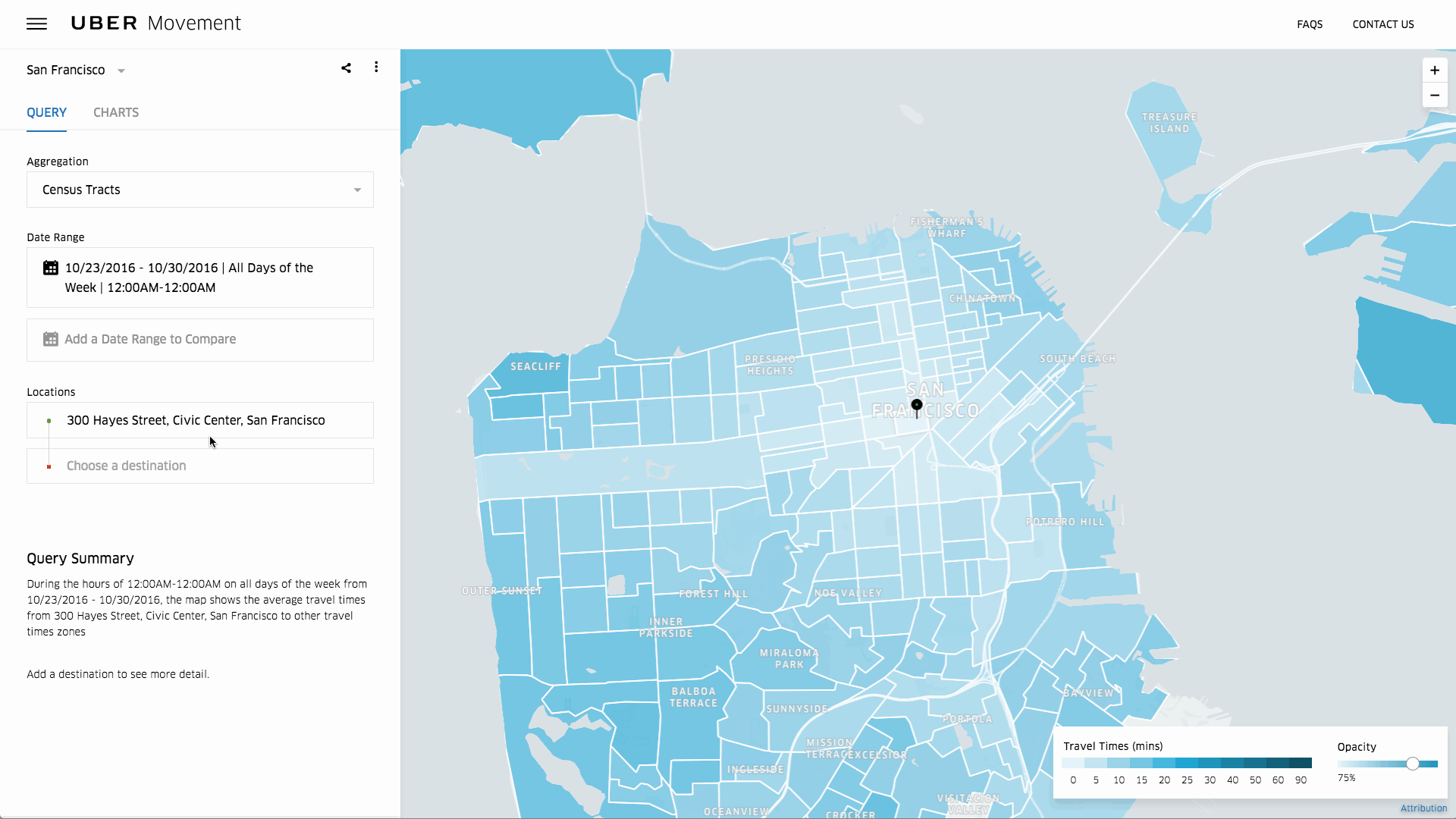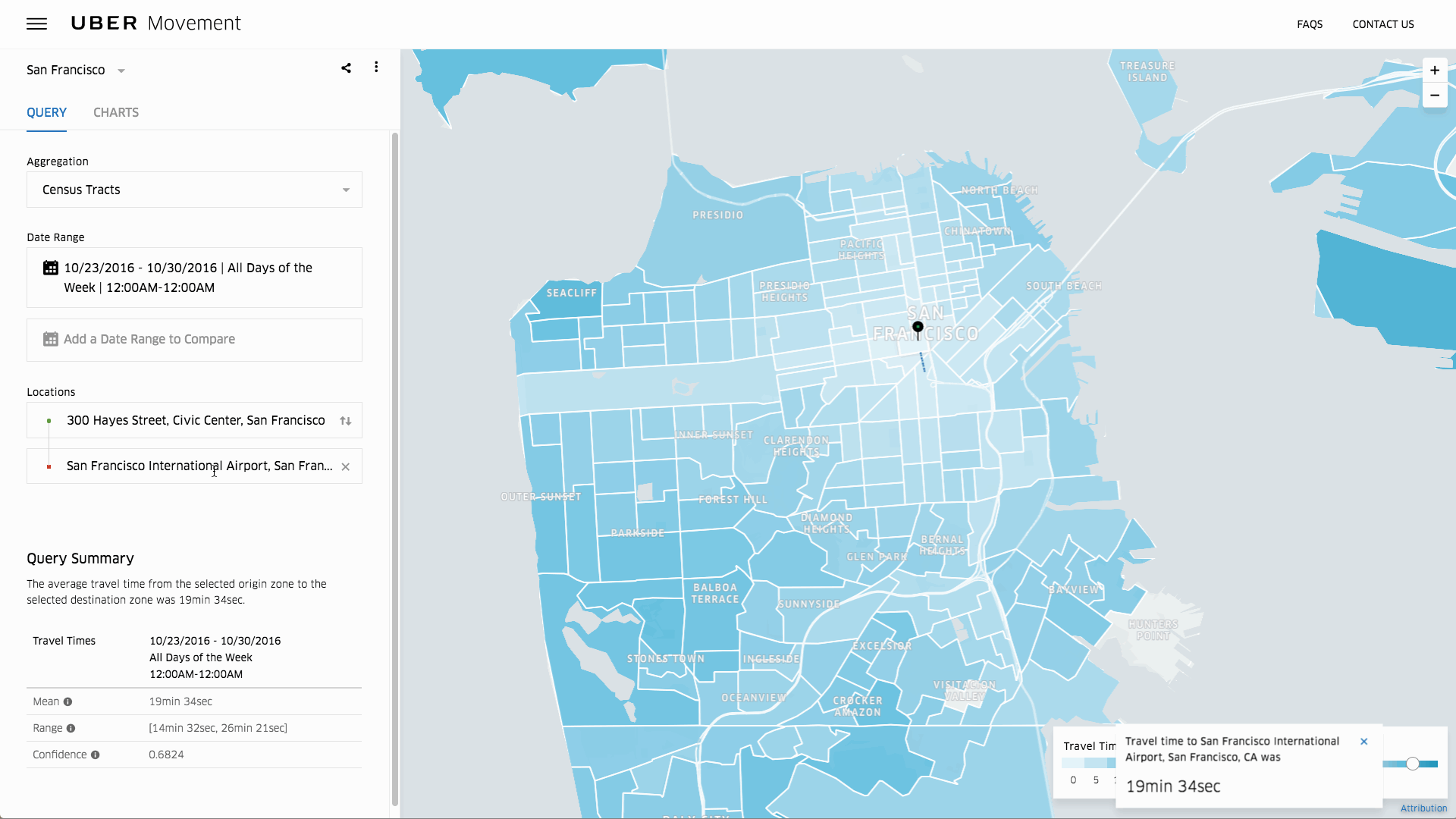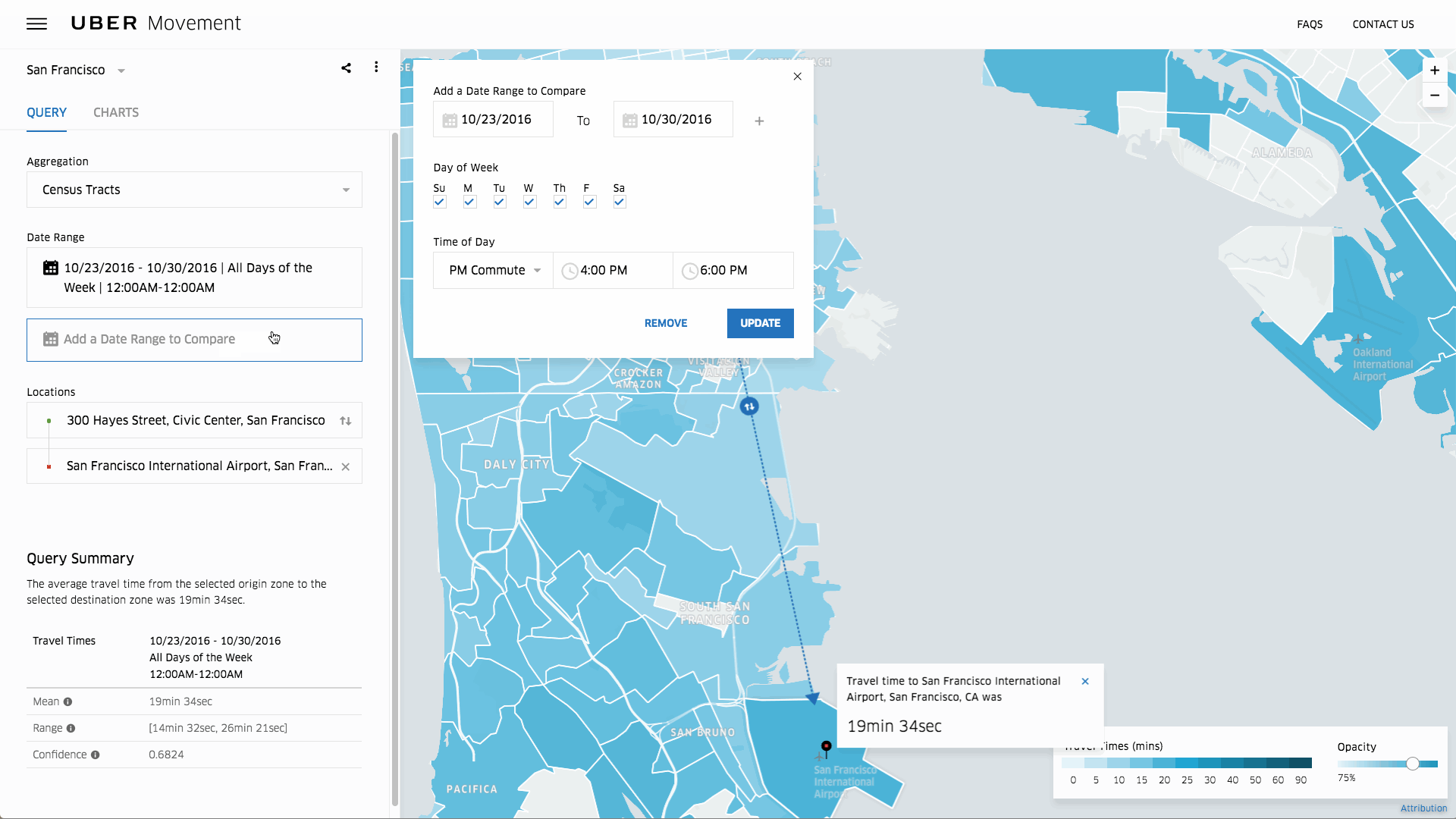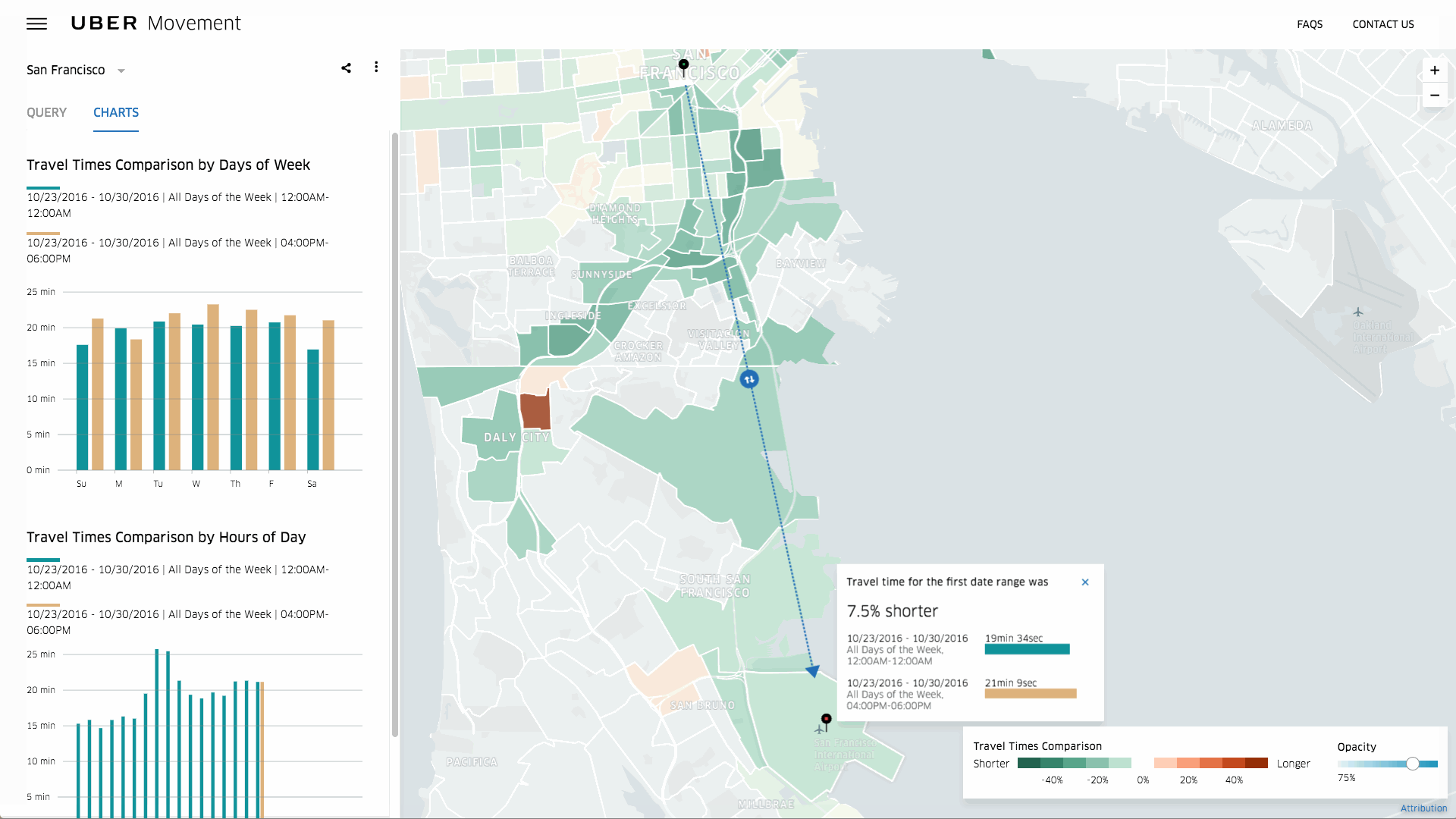
【編集部注】執筆者のRichie Heckerは、投資家でTraction & ScaleのCEOを務めるほか、Bloomberg Nationのコミュニティリーダーでもある。
結局のところ、保険とはリスクのビジネスだ。契約者に何も起きなければ保険金の請求額は低くなり、みんな幸せになれる。しかし、保険テクノロジー(もしくはインステック/保険テック)の分野が多くの起業家や投資家の間で人気を博している中、その実情はあまり理解されていない。
数ある業種の中でも、保険業は始めるのがとてつもなく難しい。というのも、規制機関が保険市場に新たなプレイヤーを参入させたがらないのだ。その理由はリスクで、保険業にはリスクを管理するための強固なシステムとバランスシートが欠かせない。しかし、新規参入の難しさゆえに、テクノロジーの観点から言うと保険業界は他の業界に遅れをとっている。これこそ、保険業界でディスラプションが起きようとしている背景だ。
「2016年の上半期だけで保険テクノロジー界に10億ドル以上もの投資が集まっていることや、1000人もの企業幹部の参加を予定しているInsureTech Connectのような業界イベントの盛り上がりから、保険業界にテクノロジーの波がきていることが分かります」とQED Investorsのパートナー兼InsureTech Connectの共同ファウンダーであるCaribou Honigは話す(実はInsureTechのもうひとりの共同ファウンダーは、以前私のポートフォリオ企業に投資している)。
冒頭の通り保険はリスクのビジネスであり、自分たちがケガをしないよう各企業の動きは遅い。保険商品の開発に3〜5年かかることもよくある。3年から5年もだ。スタートアップの世界で言えば、これは永遠に感じられるほど長い。一方で保険のプレミアムは毎年1兆2000億ドルに達している(アメリカでは”プレミアム”とは保険業界の売上を指す)。この数字は大したものだ。一般的にはどんなテクノロジーの開発にも一年以上かかり、さらにその後収集したデータを利用しながら3〜5年かけてアンダーライティングのモデルに磨きをかけなければいけない。しかし、現在収集できるデータの量や種類は昔に比べて豊富で、かつリアルタイムで入手することができる。つまり長い商品開発の期間は、スタートアップにとってのチャンスとなるのだ。
保険とは確率のゲームで、統計モデルに基づいた賭け事だ。
保険業界への参入の鍵は、行動経済学を理解することにある。行動経済学とは、人間の行動そのものや、それが購買活動にどのような影響を与えているかを研究する学問だ。まず、保険は負の支出だと考えられている。契約者が保険料の対価を得るということは、何か悪いことが起きたことを意味する一方、保険料を支払いっぱなしだと損をした気分になり、負けっぱなしな気がする。しかし実はそうではない。
市場規模を考えると、Win-Winな状況を作りだせることは明らかだ。自動車保険を例にとれば、さまざまな保険会社を比較している人たちの中でも、71%以上の人が2015年中に保険会社を変更することはなかった。
「保険業界の現状を表す例としては、Blockbuster(米レンタルビデオチェーン)とNetflixの対決が最適だと思います。既存の保険会社が商品の効率化に没頭しているかたわら、スタートアップは顧客の声に耳をかたむけて、保険業の基本的な構造から変えようとしています。彼らは過去100年間で誰も見たことがないようなやり方で、商品や流通、テクノロジーを根本的に変えつつあります」とBumbleBeeの共同ファウンダー兼CEOのJerry Guptaは話す。なお、Jerryは以前Liberty Mutualのイノベーション・ディレクターを務めており、ライドシェア向け自動車保険の世界を変えようとBumbleBeeを設立した(私はBumbleBeeに投資しており、同社の会長でもある)。
同時に、保険業界にディスラプションを起こし得る要素はいたるところにあり、シェアリングエコノミーやオンデマンドサービス、ビッグデータ、IoTやテクノロジー全般がそれにあたる。では保険テクノロジー企業が成功するにはどうすればいいのだろうか?この問いに対する答えは、自分たちで保険会社を立ち上げるか、サービスプロバイダーに徹するかの大きくふたつに別れる。この記事の中では、前者について議論していきたい。
保険とは確率のゲームで、統計モデルに基づいた賭け事だ。それでは、テクノロジーをどのように使えば勝率を上げて市場で稼ぐことができるのだろうか?
角を丸くする
保険テクノロジーの分野で大きな成功をおさめるには、既存商品の角をとっていくのが1番の方法だ。言い換えれば、いちから新しい商品を開発するのではなく、うまくいっている部分はそのままにして、既存の商品を今の時代にあった形に変化させていくということだ。具体的には、分かりやすい契約書を準備し、ユーザーエクスペリエンスを向上させ、インセンティブ(顧客にある行動を促す要因)を現在私たちが住む世界に合わせていくことなどが考えられる。
契約書の内容の多くは100年以上前に考え出されたもので、その頃には現代のテクノロジーもなければ、デジタルに繋がったシェアの世界に潜む複雑さも存在しなかった。そのため契約書を作る際には、補償内容をシンプルにして例外を省き、その保険商品を購入することで、加入者にはどんな利点があるのかをハッキリさせなければいけない。それはちょうど鋭い角を丸めるように、やるのは簡単な上、人がケガをするのを防ぐことができる。
契約書を作る際には、補償内容をシンプルにして例外を省き、その保険商品を購入することで、加入者にはどんな利点があるのかをハッキリさせなければいけない。
「保険業界には、わかりやすさを求める消費者のニーズに合わせてサービス内容を変更する責任があります」と大手生命保険会社RGAxでヴァイスプレジデント兼イノベーションスタジオリードを務めるFarron Blancは話す。「アンダーライターが加入希望者の情報を審査する際の基準や、保険相談にかかる費用や支払タイミングについての情報を明らかにするなど、保険業界は消費者の声に応えていかなければならない。その高潔な目的のもとで人々の生活を良くするため、保険業界には変化が求められているんです」
分かりやすい契約書:「保険は複雑で分かりにくい」というイメージを持つ人は多い。そもそも、弁護士の作った契約書に普通の消費者がサインをするというのは、不公平に感じないだろうか。分かりやすく補償内容がハッキリと書いてある契約書をつくるだけでも、保険業界にディスラプションを起こすことができるのだ。
そのためには、簡潔な言葉で何がカバーされていて何がカバーされていないのかを明記し、例外をなくしつつ、現状に合わせた微調整を行わなければいけない。住宅保険であれば、Airbnbの利用も一定の範囲でカバーすべきだし、自動車保険であれば、Uber車としての利用も許されるべきだ。もしもフルタイムでUberドライバーの仕事をする、ということであれば事情は変わってくるが、保険会社は保険内容に余裕をつくって、加入者が何か新しいことに手をだすのを許容しなければいけない。さらに契約書の内容はわかりやすく書いてあるか、そして実際に顧客に起こり得るような出来事をカバーしているかどうかも重要だ。このようなポイントを抑えれば、消費者の間でその保険会社の評判が高まることになるだろう。
ユーザーエクスペリエンスデザイン:ユーザーエクスペリエンスについても、分かりやすさを追求しなければいけない。ほとんどの保険会社は、未だに代理店を通して商品を販売しているが、代理店を利用するにも費用がかかり、結果的には消費者にそのしわ寄せがきている。そこで、保険テクノロジースタートアップは、ユーザーが彼らと直接契約できるようにしなければいけない。モバイルアプリをつくって、契約や保険金請求のプロセスをアプリ上で行えるようにすればいいのだ。そして、もし請求があればビデオチャットを通して、状況を把握することができる。さらに顧客とのコミュニケーションチャンネルは、モバイル、SMS、チャットボットなど、彼らの要望に合わせて用意しておいた方が良い。そして請求の処理が終わったら、顧客が請求時に使ったものと同じチャンネルを通じて、処理完了に関する連絡をする。そうすれば顧客満足度が高まっていくだろう。
同時に、できる限り多くのデータを集めるられるように、ユーザーにインセンティブを与えることも重要だ。モバイルデバイスやIoTデバイスを使うことで、データの収集経路を増やすことができる。さらに集めたデータを利用することで、リアルタイムで顧客の行動を解析でき、インセンティブの調整も可能だ。早い時点からデータ収集のために顧客の教育に注力すれば、最終的には顧客の行動に基いたセグメンテーションという形でその労力が報われることになる。
インセンティブの調整:必要なときに保険を請求できるかどうかというのが、保険商品の品質の要だ。しかし保険は、自動車のこすり傷や、ただ咳が出ているだけのときなど、全ての状況をカバーするためには設計さていない。もともと保険は大災害(=大きな出費)が起きたときのためのものだ。例えば船が海賊に盗まれたら、Lloyd’s of Londonはそれをカバーしてくれる。
保険金の請求プロセスは、請求額の大小に関わらず全ての案件で同じだ。だからこそ、少額の問題については加入者が自分で手数料をかけずに処理し、被害額が大きいときには保険を利用するように仕向けることで、保険会社は出費をかなり抑えることができる。そして減らした出費を顧客に還元すれば良いのだ。
保険業界は今ディスラプションを起こすには最適な市場だ。そして上述のように、保険業界で成功するためには、分かりやすい契約書や簡素化された契約プロセス、使いやすいサービスを準備し、加入者が出費を抑えつつ、本当に必要なときにだけ保険を請求するようにインセンティブを調整することが重要になってくる。
[原文へ]
(翻訳:Atsushi Yukutake/ Twitter)


















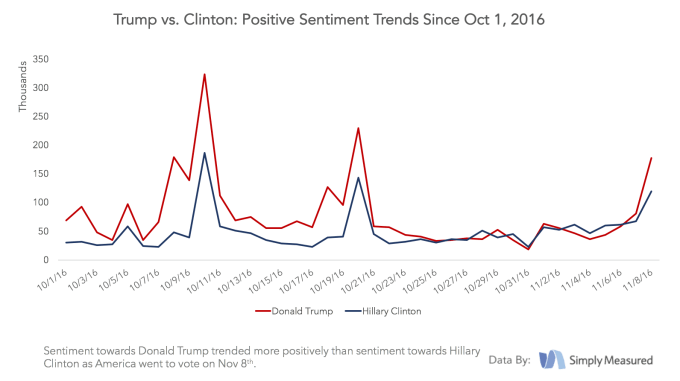
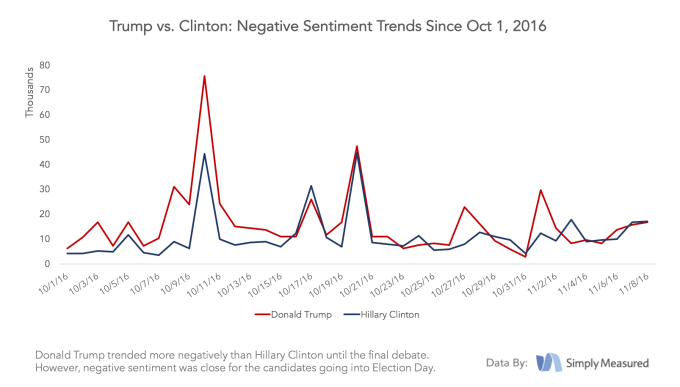
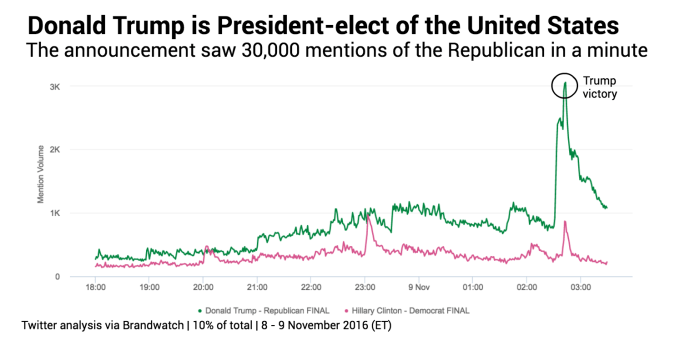
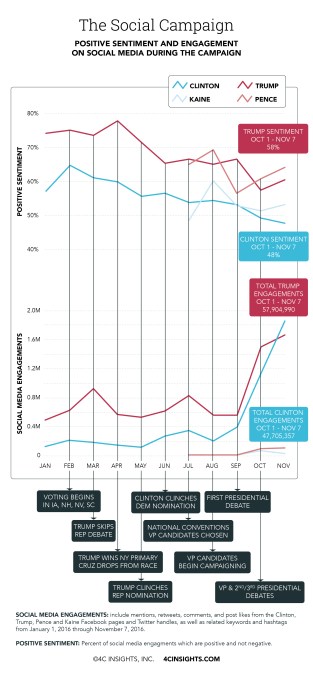 数々の世論調査の結果、民主党候補のヒラリー・クリントンがアメリカ大統領選で楽勝すると思われていたが、今となっては世論調査の予測モデルに問題があるのは明らかだ。現在データサイエンティストが大慌てでその原因を探っている一方、ソーシャルメディア分析サービスを提供する企業の多くは、彼らの方が上手く現実を把握できていたと共に、彼らはドナルド・トランプが選挙で勝つ可能性があるとずっと前からわかっていたと謳っている。
数々の世論調査の結果、民主党候補のヒラリー・クリントンがアメリカ大統領選で楽勝すると思われていたが、今となっては世論調査の予測モデルに問題があるのは明らかだ。現在データサイエンティストが大慌てでその原因を探っている一方、ソーシャルメディア分析サービスを提供する企業の多くは、彼らの方が上手く現実を把握できていたと共に、彼らはドナルド・トランプが選挙で勝つ可能性があるとずっと前からわかっていたと謳っている。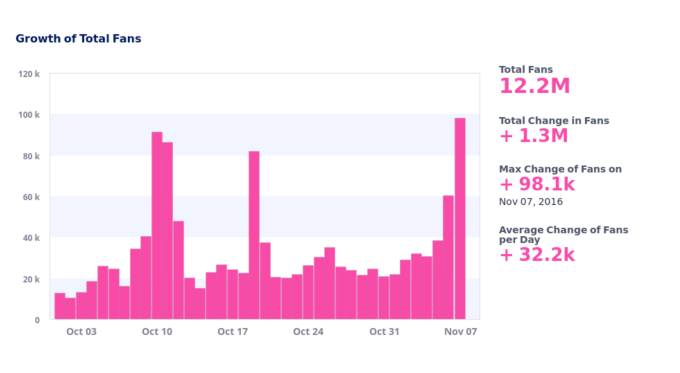





 Cardiogramの創業チーム
Cardiogramの創業チーム