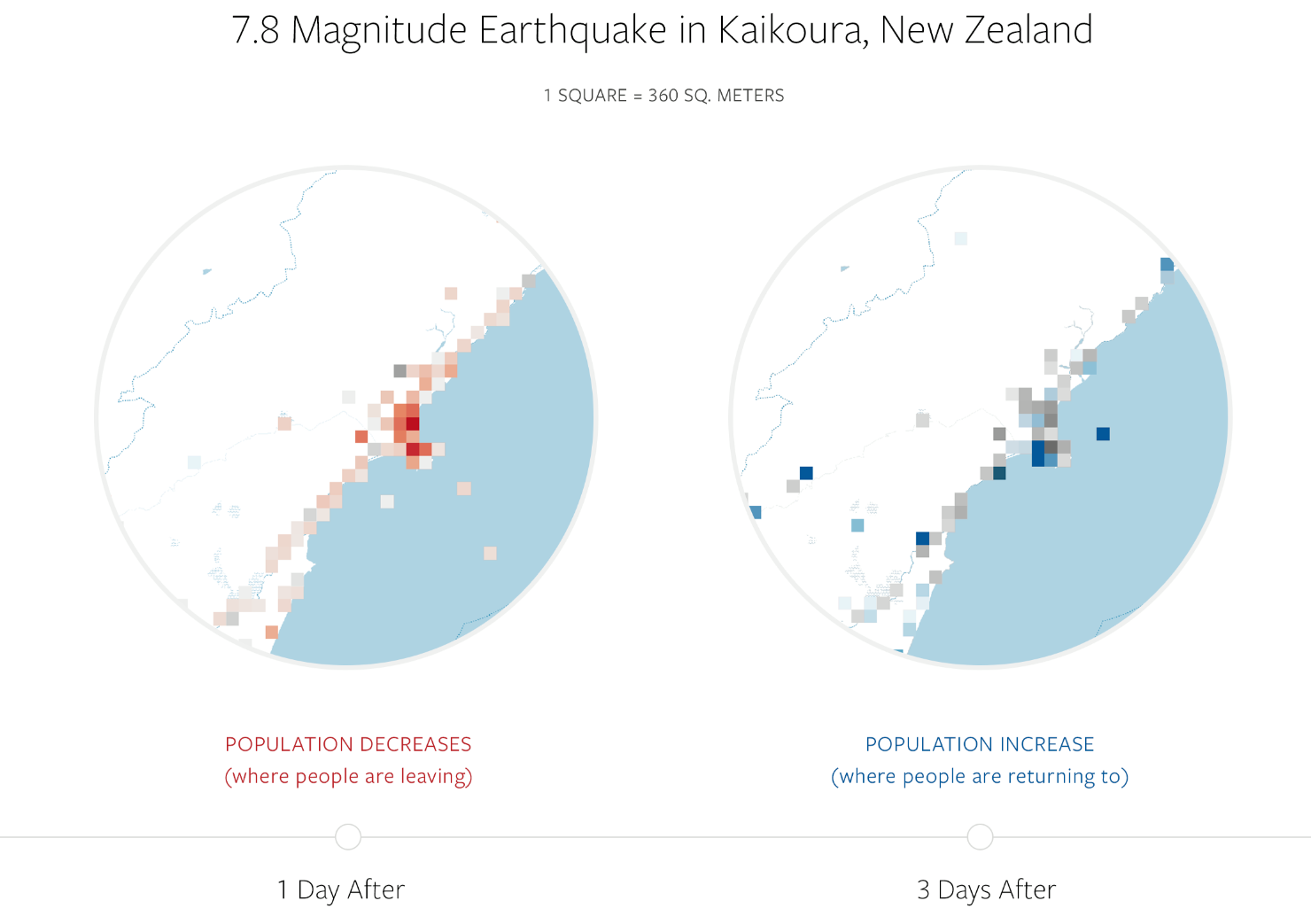
秘密計算技術のEAGLYS(イーグリス)は7月13日、東芝が新規事業創出を目指し開催した「Toshiba OPEN INNOVATION PROGRAM 2020」において、協業検討企業として選抜されたと発表した。
EAGLYSは、秘密計算技術で常時暗号化したデータ操作が可能なデータベース向けプロキシソフトウェア「DataArmor Gate DB」と、東芝のIoT・ビッグデータに適したデータベース「GridDB」との製品連携の実証を重ね、ビッグデータのリアルタイム分析における高セキュリティ・秘密計算機能の実現と価値創出に向け協業検討を進めるという。
Toshiba OPEN INNOVATION PROGRAM 2020は、東芝グループが持つローカル5G、IoT、ビッグデータ、画像認識などの技術を活用し、共に新規事業の創出や協業検討を行うプログラム。EAGLYSは、プログラム採択企業として2020年9月25日の成果発表会までに実証実験を重ねて検討をブラッシュアップ、より本格的なビジネスソリューションとしての事業化を目指す。
秘密計算技術とは、データを暗号化したまま復号することなく任意のデータ処理ができる暗号技術の総称。ゼロトラスト時代のデータセキュリティには、ネットワークなどの境界に依存したセキュリティ対策ではなく、「データそのもの」を守るアプローチが求められ、それを実現する基盤技術として期待されている。

EAGLYSの秘密計算技術は、格子暗号をベースとする準同型暗号を採用。暗号処理に伴う計算量の増加が準同型暗号実用化の課題となっていたが、IEEEをはじめ各種国際学会に採択された同社秘密計算エンジン「CapsuleFlow」(カプセルフロー)関連の研究成果によって、大幅な高速化と省メモリー化を達成。業界に先駆けて準同型暗号の実用化に成功した。
DataArmor Gate DBは、EAGLYSが開発・提供するセキュアコンピューティング・プラットフォーム「DataArmor」シリーズのデータベース向けの高機能暗号プロキシーソフトウェア。このソフトウェアでは、データを暗号化したまま透過的に検索・集計クエリなどのデータベース操作が可能。データベース側に鍵をもたない設計により、通信中・保管中・処理中(検索・集計などのクエリ)を常時暗号化し、セキュリティレベルの向上と高パフォーマンスを両立している。
また、プロキシー型で提供しているため、データベースの種別に依存しない連携が行える。同製品にはデータを暗号化したまま計算可能な秘密計算機能も搭載しており、IoTなどセンシングデータの計算処理などのユースケースにも適用可能。
関連記事
・量子コンピュータ対応の暗号化セキュリティ技術を擁するPQShieldが7.5億万円調達
・マイクロソフトがセキュリティスタートアップのCyberXを買収、Azure IoT事業のセキュリティ強化に超本腰
・暗号化したままデータ解析可能な「秘密計算」の実用化めざすEAGLYS




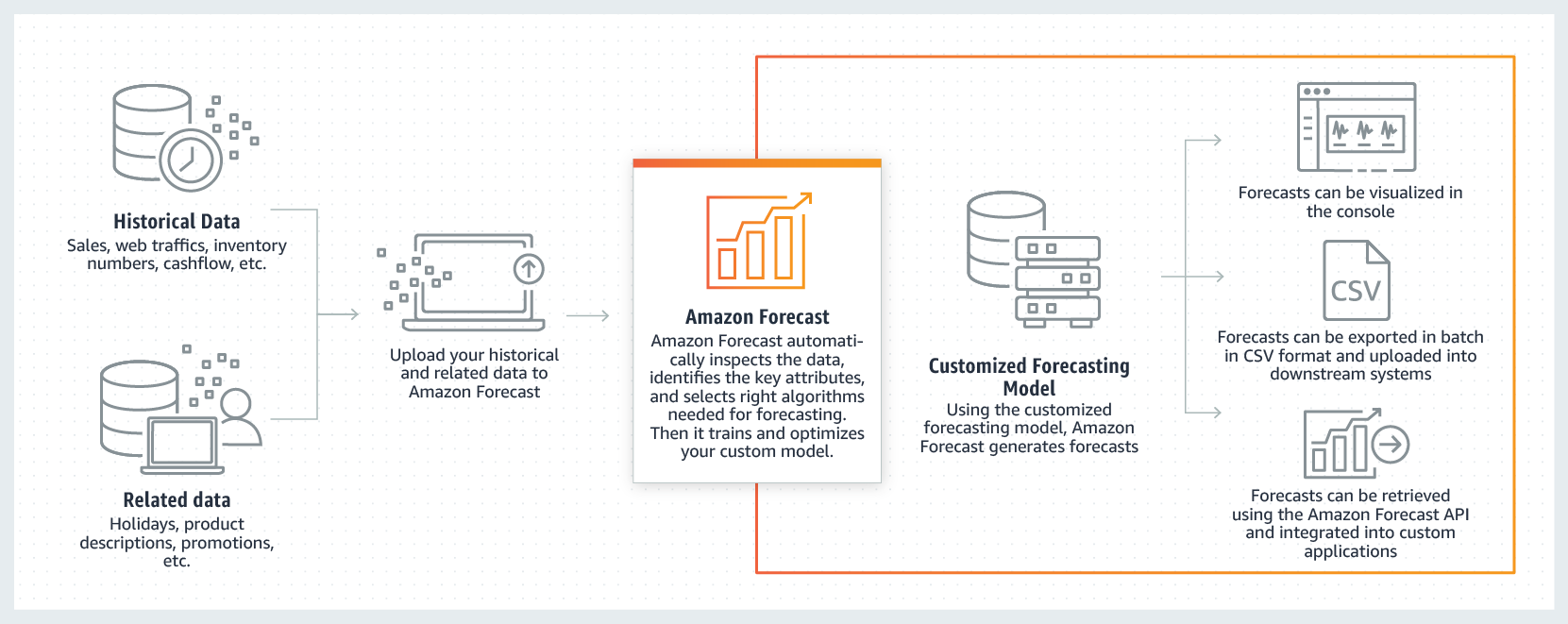







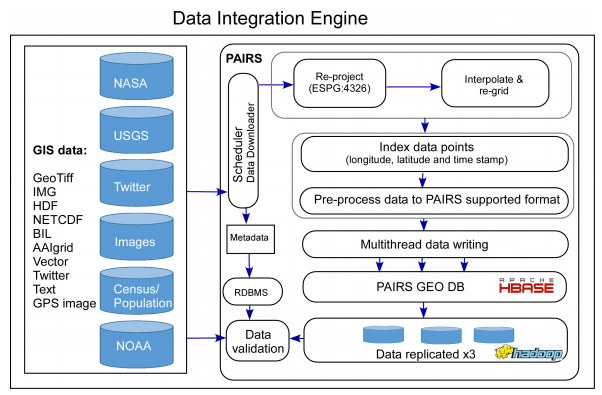
 SmartDriveは、自動車に取り付ける専用デバイスから50〜60項目にわたるデータを取得・解析し、それをもとに自動車保険の開発や走行データ可視化サービスなどを展開するスタートアップだ。そのようなデータを利用して、安全運転の度合いによって掛け金が変動する
SmartDriveは、自動車に取り付ける専用デバイスから50〜60項目にわたるデータを取得・解析し、それをもとに自動車保険の開発や走行データ可視化サービスなどを展開するスタートアップだ。そのようなデータを利用して、安全運転の度合いによって掛け金が変動する