Facebookでは毎日、何十億ものコンテンツがシェアされている。その膨大な量とペースに漏れなく遅れなく対応できるためにFacebookは、さまざまなツールを駆使してテキストを分類している。多層ニューラルネットワークのような従来的な方法は正確だが、ニューラルネットワークは訓練が大変である。
分類に正確さと容易さの両方をもたらすために、Facebookの研究部門Artificial Intelligence Research(FAIR)ラボはfastTextというものを開発した。そして今日(米国時間8/18)はそのfastTextがオープンソース化され、デベロッパーはどこででも、そのライブラリを使ったシステムを実装できることになった。
fastTextはテキストの分類と、語のベクタ表現の学習の両方をサポートしている。後者には、bag of wordsやsubword information(部分語情報)*などのテクニックが用いられる。skip-gramモデルに基づいて語は文字のn-gramのバッグとして表現され、それらは各文字のn-gramを表すベクタで表現される。〔*: 部分語情報、‘あかい’なら、あ、か、い、あか、かい、などが部分語。〕
“カテゴリー数のとても多いデータベース上で効率的であるために、fastTextは階層的な分類を用いる。そこではさまざまなカテゴリーがフラットなリストではなく二分木構造に編成される”、FacebookのArmand Joulin, Edouard Grave, Piotr Bojanowski, Tomas Mikolovらがドキュメンテーションでそう述べている。
bag of wordsのbag(バッグ)は、配列やリストや木(ツリー)などなどと並ぶコンピューター上の一般的なデータ構造の一種で、名前(“袋”)の名のとおり、データに順序性がなく、この場合は各語の出現頻度を各語が情報として持つ。“語(words)”は多次元空間として表現され、クェリとカテゴリー分けされた語の集合との関係を線形代数を使って計算する。コンピューターにテキストを投じたとき、それはゼロからのスタートになる。それに対して人間の大人はすでに文法知識を持ち、どこが語の始まりで終わりかを知っている。コンピューターの計算力は強力だが、そのままでは“I love TechCrunch”と“CrunchLove iTech”の違いを認識できない。そこでこのような方法では、ことばに対する定性的な分析を、統計的手法などにより、定量的な分析へと強制的に変換する。
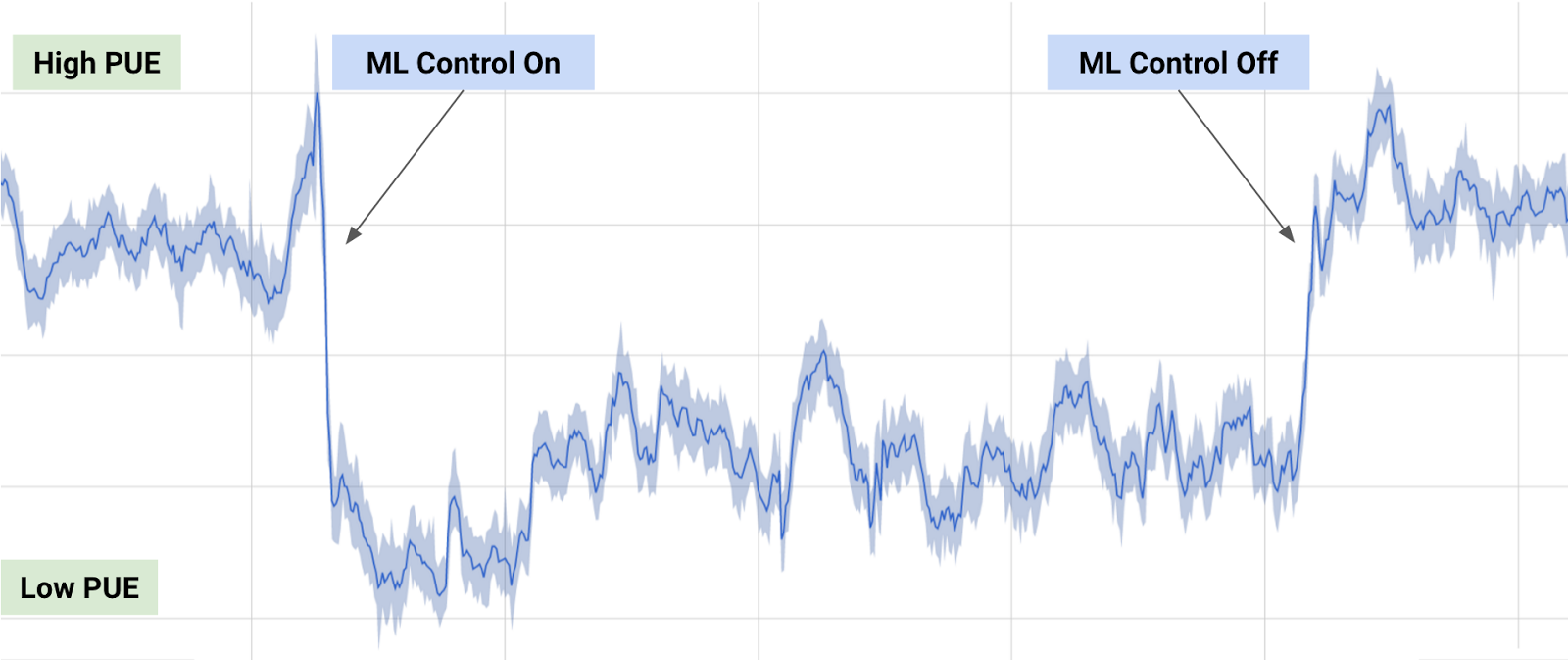
そして数を操作する処理が主体なので、fastTextは従来の深層学習の方法(多層ニューラルネットワーク)よりも速い。下図は、Facebookが作った比較表だ。実行時間が「秒」の単位なのは、fastTextだけである:

fastTextは英語だけでなくドイツ語やスペイン語、フランス語、チェコ語などに対しても使える。
今月の初めにFacebookは、クリックベイトをやっつけるアルゴリズムを同社のNewsfeedに実装した。そのアルゴリズムは言葉以外の要素(繰り返しパターンなど)も点検するから相当複雑だが、デベロッパーはfastTextを利用して同様のツールを自作できる。
Facebookによると、fastTextなら、“ふつうのマルチコアのCPUを使って、10億語を10分弱で学習できる。また、50万のセンテンスを30万あまりのカテゴリーに5分弱で分類できる”、という。これはすごい、かもしれない。
今日(米国時間8/18)からFacebookのfastTextは、GitHub上で入手できる。





















 人工知能(AI)で事件や事故、災害の画像・動画をネット上から自動収集し、投稿者の許諾を得て報道機関に提供するサービス「
人工知能(AI)で事件や事故、災害の画像・動画をネット上から自動収集し、投稿者の許諾を得て報道機関に提供するサービス「