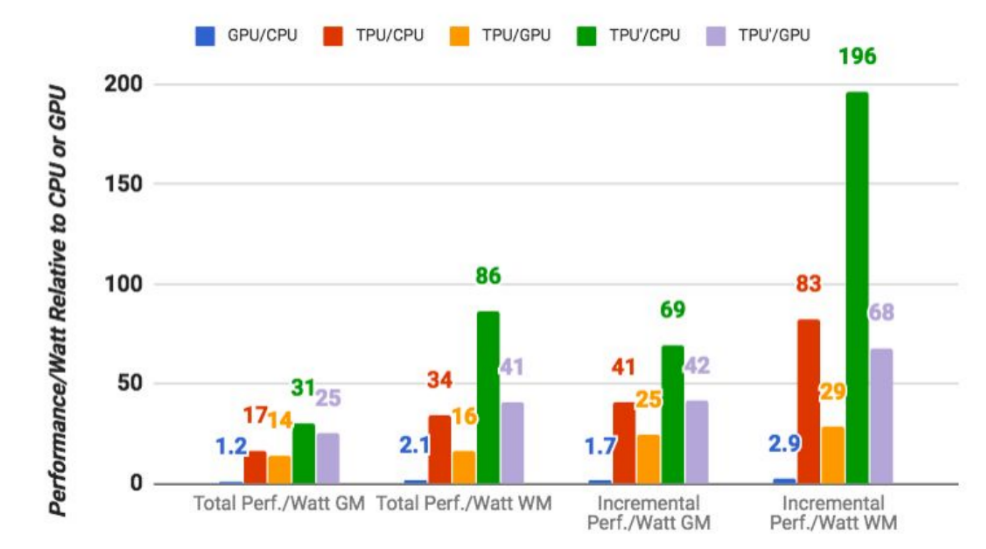
生後6か月とまだ非常に若いスタートアップのGrowlabsは、マシンインテリジェンスを利用して外回りの営業チームを支援している。このほどシードラウンドで220万ドルを調達した同社は、チケットアプリのUniverseを作ったBen Raffiが創業し、これにJaclyn KleinとSafeer Jiwanが加わった。Growlabsは、小さな営業チームの効率を上げることによって、企業の顧客獲得コストを減らすお手伝いをする。
Universeの経験からRaffiが学んだのは、顧客獲得コストを肥大させずにアプリケーションをスケールするのが、とても難しいことだ。チームが80%の時間を調査と、メールの乱発に費やしても、それが売上に結びつく保証はどこにもない。
“見込み客の生成に努力したが、結果は良くなかった”、とRaffiは語る。“何もかも、いきあたりばったりだった”。
Growlabsを使うと、営業チームがターゲットのタイプと業種を指定すると、Growlabsが自動的に見込み客を生成し、メールを送り、結果を評価する。
Growlabsは機械学習と3億5000万件の見込み客候補のデータベースを組み合わせて、一番売りやすいターゲットを見つける。対話のデータをすべて集めて、今度はいつメールを送るべきか、フォローアップは何回必要か、などをアドバイスする。
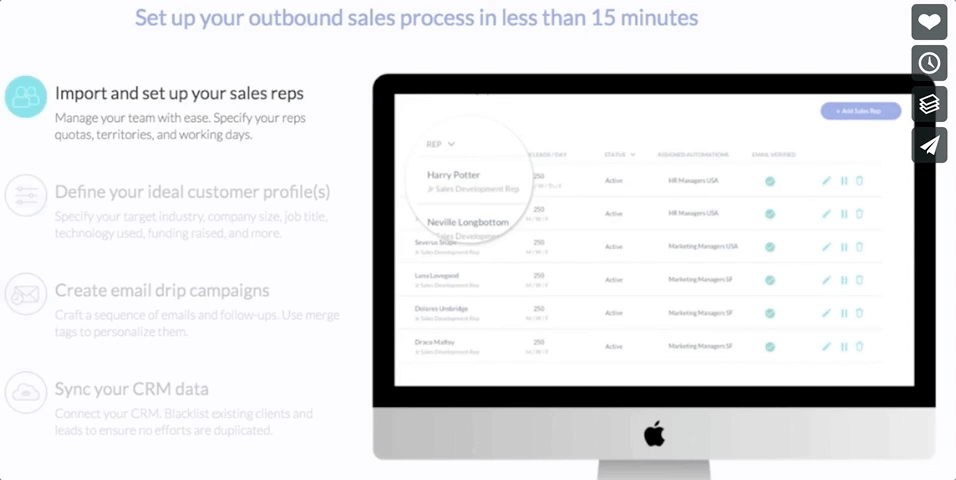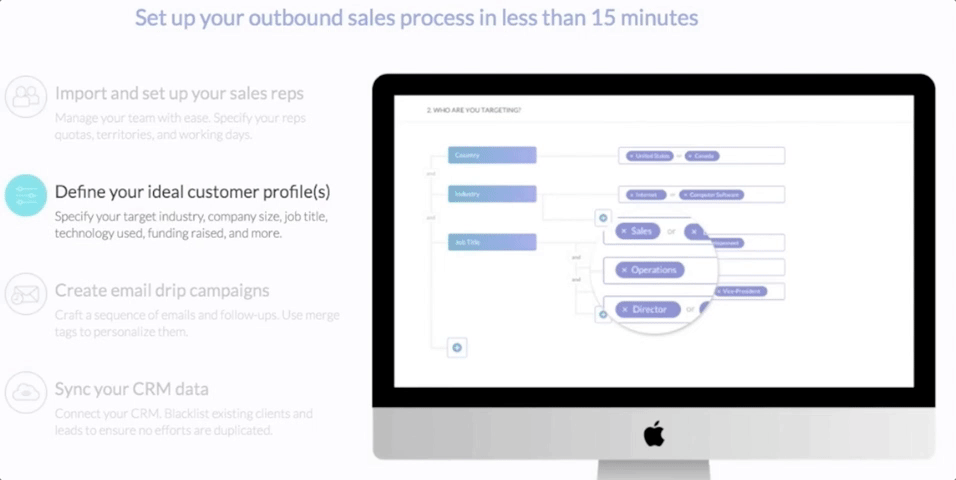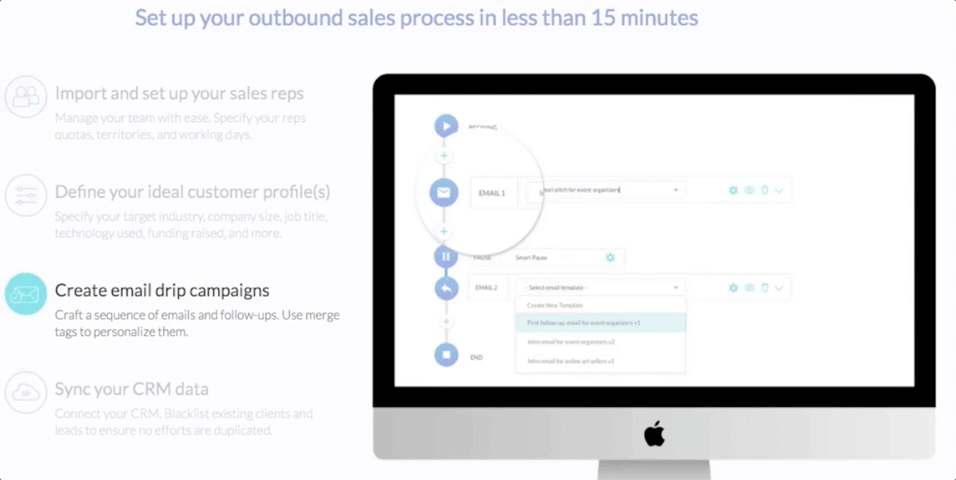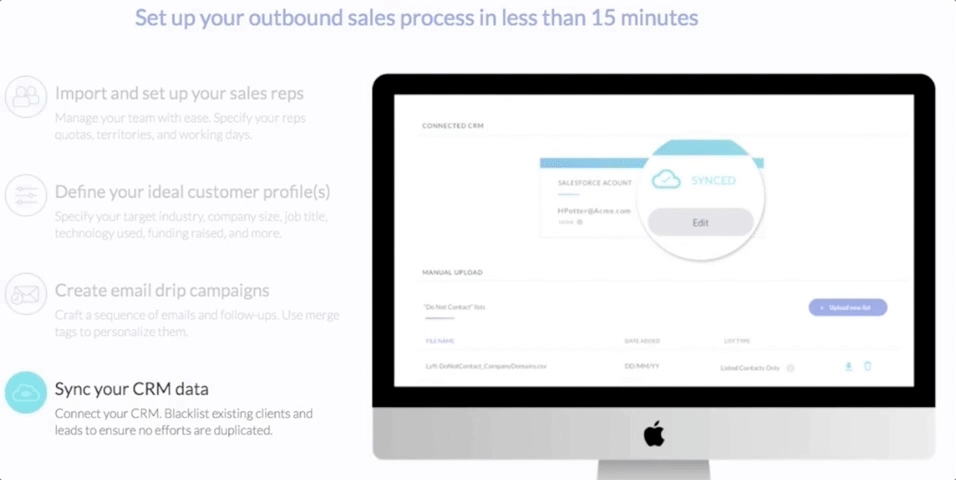
ターゲットに対しては、基本的な分析のほかに、自然言語処理によりメールの内容を分析する。メッセージを分類すると、どの役職にはどんな売り込みが効果があるか、などのフィードバックが浮かび上がってくる。CTOが関心を向けても、CMOはさっぱり、ということもある。
課金は有効見込み客の生成数に対して行われるから、高価な一律会費制のSaaSサービスを使えない零細企業でもGrowlabsの顧客になれる。Growlabsのいちばん小さい顧客でも、このサービスを使って毎月数千通のメールを送っている。大きな顧客なら、2万とか3万になる。
今日の資金調達ラウンドは主にエンジェルたちと、B2Bの営業活動の経験のある戦略的投資家たちが主体だ。Growlabsは今、社員が8人だが、同社自身がこれからますます、中小企業への営業を成功させていかなければならない。