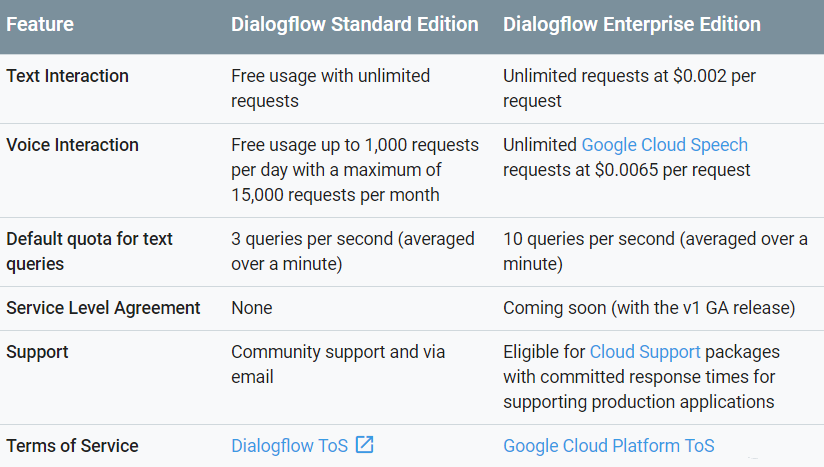
Appleは昨日(米国時間12/20)、App Storeにおけるアプリ・レビューのガイドラインを修正した。このガイドラインはテンプレートその他を用いるアプリ・ジェネレーション・サービスによって作成されたアプリの登録を禁止するもので、大きな議論を引き起こしていた。
Appleが今年に入ってApp Storeの利用規約を改正したのは低品質のアプリやスパム・アプリが登録されるのを防ぐ狙いがあった。しかしこの方針は 当初の目的を超えてはるかにおおきなマーケットに影響を与えることになった。つまりレストラン、NPO、クラブ、その他、オリジナルかつ高品質のアプリをインハウスで開発する専門知識、資金その他のリソースを持たない各種スモールビジネスがネガティブな影響を受けている。
Appleの新しいガイドラインは「App Storeで受け入れられないアプリ」の定義をさらに詳しく述べている。
改正前のガイドラインの当該部分、4.2.6 App Store guidelineは以下のとおりだった。
4.2.6 商用のテンプレートによって作成されたアプリ、またはアプリ・ジェネレーション・サービスによって作成されたアプリは受け入れられない。
これに対して、今回改正された文言は以下のとおり。
4.2.6 商用のテンプレートによって作成されたアプリ、またはアプリ・ジェネレーション・サービスによって作成されたアプリは受け入れられない。ただし、アプリの登録がアプリのコンテンツ提供者自身によって直接申請される場合はこの限りではない。〔アプリ・ジェネレーション・〕サービス等はクライアントを代理して登録の申請を行ってはならない。また〔これらのサービスは〕クライアントがカスタマイズしてイノベーティブかつ独自のユーザー体験を提供するアプリを作成できるツールの提供に努めなければならない。
テンプレートのプロバイダーはクライアントのコンテンツを一つのバイナリーに統合するいわゆる“picker”モデルを利用することもできる。たとえばレストランの情報アプリであれば、それぞれのクライアントのレストランがが独立のカスタマイズされたページを持つ単一のアプリを登録申請することは可能であり、イベント情報アプリであれば、それぞれのクライアント・イベントが独立のページとして表示されるような単一のアプリを登録することはできる。
これによってAppleがテンプレート・アプリについてどう考えているかがよく分かる。
根本にある考え方は、スモールビジネスがテンプレートや仲介者(アプリ作成サービス事業者)を通じてアプリを作成するのはかまわないが、テンプレートのプロバイダーが実際のビジネスに代わってアプリを登録することをは許されない、というものだ。
AppleはApp Storeに登録されるアプリはコンテンツの元となるビジネス自身が登録申請すべきだと考えている(この考え方は以前も述べられていた)。つまり、地域のピザショップであれ教会であれフィットネス・ジムであれ、アプリを登録しようとする組織はApp Storeのガイドライン、規約その他の文書を熟読し、登録プロセスに積極的に関与しなければならないということだ。
Appleでは2018年早々にもアメリカ政府・自治体諸機関およびNPOについて99ドルのデベロッパー手数料を免除してこの新方針を受け入れやすいものにするという。
またテンプレート・サービスのような仲介者もすべて排除されるわけではない。テンプレート・サービスがアプリを作成する手助けをするのはけっこうなことだ―Appleはアプリが「どのようにして」作成されたかにはさして興味を抱いていない(ウェブページを単にアプリ化したものでないかぎり)。Appleが審査するのは「その結果」だ。
App Storeに登録されるためには、アプリは高品質で優れたユーザー体験をもたらさねばならないというのがAppleの考え方だ。つまりアプリにはそれぞれ独自性が必要であり、多数のアプリがそっくりな外見を呈してはならない。つまり互いにクローンであってはならない。また、されに重要な点は、ウェブページやFaceookページをそのままアプリ化したものであってはならないということだ。
Appleは「アプリは単なるウェブページ以上の深く豊かな体験をユーザーに与えるものでなければならない」と信じている。

上図:AppMakrで作成されたThe Official Lumineersアプリ
ただし、このルールが適用されるべき範囲を巡っては見解の相違が残る。
たとえば、現在多くのユーザーが「テンプレート・アプリ」を使っている。お気に入りのタコショップ、所属する教会、地元の音楽クラブ、学校、その他のアプリだ。ユーザーはこれらのアプリが単一のテンプレートから作成され、相互にそっくりだと知らないし、知ったところでそもそもそんなことは気にかけないだろう。
またある種のアプリが互いにそっくりであることはユーザーにとってかえって使いやすくなっているという議論もある。たとえば「モバイルから注文」がそれぞれ独自のデザインで独自のプロセスだったら使いにくいだる。どこからメニュー表示をさせればいいのかアプリごとに探す必要があるのがユーザー体験の向上だろうか?
しかしAppleはApp Storeに無数のコピーキャット、クローン・メーカーがはびこっっているのを強く嫌っている。クローン・アプリが優勢になれば、わざわざ高品質のアプリを作成するデベロッパーが不利になる。テンプレート・プロバイダーが単一のデベロッパー・アカウントで一挙に2万件ものアプリを登録するといった事態はApp Storeを窒息させかねない、と考えている。
しかし低品質のアプリの大群を規制する必要があるにせよ、App Storeにおけるテンプレート・アプリ全般の禁止は行き過ぎでありエコシステムにネガティブな影響を与えるとする意見も強い。
この問題はTed W. Lieu下院議員( カリフォルニア、33選挙区) の注目を引いた。Liew議員はAppleについて「〔規制の〕網を広げ過ぎている」と述べた。スパム・アプリ、違法アプリの排除の必要は認めるものの、「App Storeに対しなんら危害を加えておらず、これまで長年にわたって役立ってきた正規のデベロッパーを排除するものだ」とLiew議員は批判している。
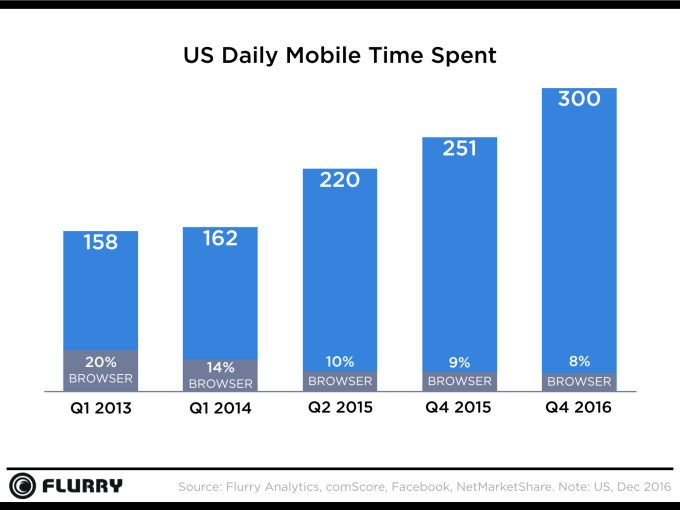
しかし一方でAppleはネット中立性を支持して、何人も平等かつ自由なインターネットへのアクセスの権利を持つと主張している。にもかかわらずApp Storeレビューの新しい方針はスモールビジネスや小規模なNPOに対して不利に働く。しかもモバイル・デバイスからウェブへのアクセスは次第にモバイル・アプリを経由する傾向を強めている(上記グラフ参照。ブラウザは時代遅れになりつつある)。【略】
なるほど、ピザショップはUber Eatsを使うこともできる(高額な手数料を払えばだが)。ネールサロンは店をYelpに掲載できるし、パパママ・ストアもFacebookページを作れる。また事実作っているだろう。しかし全体としてこれはスモールビジネスが巨大アグレゲーターの支配下に置かれるるという傾向をますます強めるトレンドだ。
最近、TechCrunchはApp Storeにアプリを登録している多くの会社が 2018年1月1日という締め切りを言い渡されたことを報じた。この期限までにアプリを新しいガイドラインに対応させないかぎり、レビュー・チームはアプリをApp Storeから排除するという。一部のアプリはすでにこの禁止条項を適用され、登録申請を却下されている(すでにライブであるアプリは次のアップデートまで適用を除外されているが、この状態がいつまで続くのかは不明だ)。
Appleの新方針のために一部の会社は運営停止に追い込まれている。
今回修正された後の字句をみても、影響を受けた会社が以前のとおり運営を続けられるようになったとは思えない。 こうしたサービスはやはり「クライアントがカスタマイズしてイノベーティブかつ独自のユーザー体験を提供するアプリを作成できるツール」を新たに提供する必要がある。
言い換えれば、Google Sites のようなシンプルな構成ではなく、Squarespaceのような凝った構成にせよ(ただしアプリだが)ということだ。

テンプレート・ベースのアプリの例。 一般ユーザーはテンプレートだと気づくだろうか?
しかし今回影響を受けた会社は、すべてがスパム・メーカーというわけではない。一部はウェブページをラップしてアプリにするだけのツールを提供していたものの、一部はグレーゾーンだった。
これにはChowNowのような、特定のバーティカルに属するスモールビジネスがApp Storeを利用することを助けようとするものが含まれる。CowNowは近隣のレストランがモバイル経由で注文を受けるためのアプリだが、同様のアプリはフィットネス・ジムや教会、スパ、コンサート、政治家など非常に幅広い分野に存在する。
こうしたビジネスはApp Storeガイドラインの4.2.6(ときおり4.3)項によって登録を拒絶されつつある。こうしたアプリの申請者によれば、Appleに対し電話などで直接説明を求めようとしても困難だという。
修正以前の4.2.6項は、テンプレート・ベースのアプリ全般を禁止し、4.3項はスパム・アプリ全般を禁じる網羅的条項だった。4.3項はAppleがあるアプリを排除したいが、アプリ作成ウィザードやドラグ・アンド・ドロップなどによって一挙に作成されたものだということを証明できない場合に用いられることを意図したものだということだ。
-
screen-shot-2017-12-20-at-3-41-33-pm.png
-
screen-shot-2017-12-20-at-3-41-42-pm.png
Appleがこの方針をWWDCで発表したとき、テンプレート・プロバイダーの多くは自分たちに影響が及ぶとは考えていなかった。この禁止方針はクローン・アプリ、スパム・アプリを締め出すためのものだと考えたからだ。そのため、App Storeのレビュー・ガイドラインがテンプレート・プロバイダー自身もApp Storeから締め出されれることを明らかにしたためパニックが広がった。これらのテンプレート・プロバイダーは自分たちがスパマーだとは考えていなかった。
修正後のApp Storeのガイドラインは、字句の訂正により明確化されているものの、本質的なAppleの意図は変わっていない。
ともあれアプリが実質的にはウェブページそのものである場合、あるいは他のアプリとデザインがそっくりである場合、申請の手間をかけるには及ばない。App Storeがそういうアプリを排除することは動かない。
[原文へ]
(翻訳:滑川海彦@Facebook Google+)