[筆者: Salil Deshpande](Bain Capital Venturesの専務取締役で、主にインフラストラクチャのソフトウェアとオープンソースが専門。)
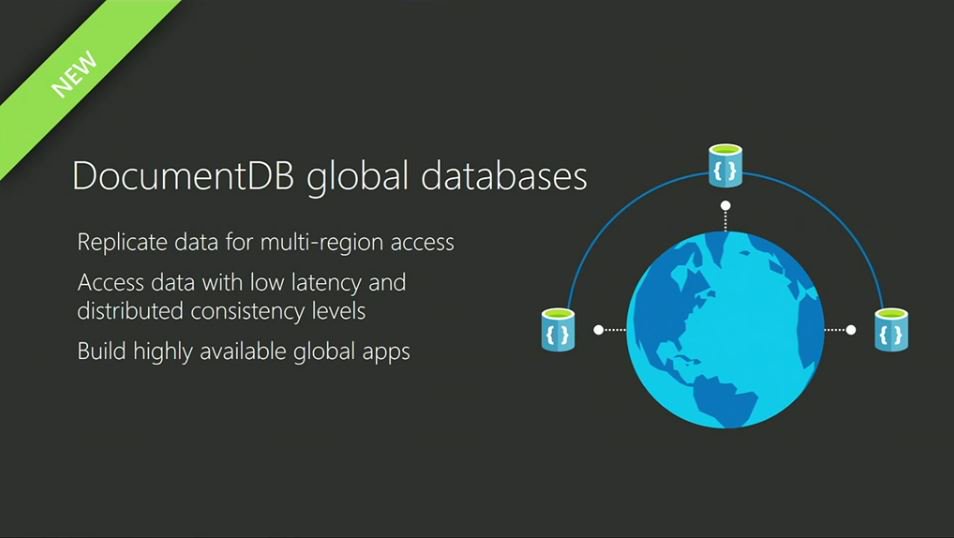
顧客は品物やサービスに今すぐ自分のいるところからアクセスしたいと欲するから、サーバーはリクエストの洪水になり、膨大な量の並列処理と応答能力が求められる。そこで今や、どんなタイプの企業も、“Webスケールの”*システムを作ることに力を入れている。〔*: Web-scale, “Web大の”。〕
Webスケールのシステムは最初、FacebookやGoogleのような巨大なサービスが必要とした。しかし今では、どんなサイズの企業でもこのスローガンを唱えている。Webスケールのアーキテクチャで作られたシステムは、その柔軟性とスケールとパフォーマンスで顧客を幸福にするから企業にとって必須である、と信じられている。
しかし、さまざまなテクノロジーの重なりの全体の中では、とくにデータベースが、Webスケールを構築するための最難関の隘路として目立っている。
それは単純に技術的難関であるだけでなく、データベースが当然のように持っている性格でもある。…データというものはACIDな特性を持ち、複数のサーバーに亙って複製される場合でも、いや、さまざまなデータセンターに分散していても、一貫性と保存性を維持しなければならない。そこでデータベース、とりわけ関係データベース(リレーショナルデータベース)は、Webスケールのの技術の重なり(“技術スタック”)の中でのアキレス腱であり続ける。データベースがアプリケーションのパフォーマンスを左右し、そして顧客が毎日体験するのはデータベースではなくてアプリケーションなのだ。
ぼくのVC稼業は今年で10年になるが、その過程で幸運にも、さまざまな関連技術に投資することにより、このアキレス腱の恩恵にたっぷりと与(あずか)ってきた。アプリケーションサーバーのSpringSourceに投資した。エンタープライズサービスバスのMuleSoftや、CassandraによるNoSQLデータベースDataStax、Redis NoSQLデータベースRedis Labs、インメモリコンピューティングファブリックHazelcast、JavaとScalaのためのマイクロサービスプラットホームAkka、AWS Lambda的なマイクロサービスアーキテクチャIron.io、などなどにも。これらはどれも、直接的または間接的に、データベースというアキレス腱の痛みを和らげていたが、痛みそのものと対決してはいなかった。
初めてWebスケールのの技術を作った彼らGoogleやFacebookは、従来からの(関係)データベースの問題を、抽象化層(abstraction layer)を作って解決した。彼らはそれを“データアクセスレイヤ”(data access layer)と呼び、それをアプリケーションとデータベースのあいだに置いた。
アップタイムに関しては多くの場合、データベースがシステムのいちばん弱い急所だ。
抽象化層は、そのぶん処理の負担は増えるけれども、これまであったアプリケーションとデータベースのあいだの1:1の結びつきを切るので、アップタイムとパフォーマンスを改善する。このような分離、このような離散的な技術の層は、アプリケーション開発を単純化し、Webスケールの利点をデータベースにももたらすので、今ではシステムとアプリケーションをスケールするときのベストプラクティスとされている。柔軟性(負荷耐性)とスケールとパフォーマンスが上がるからだ。
データベースの抽象化層と相前後して、一種のトレンドのように、さまざまな技術が“抽象化”され、あるいは“仮想化”された。サーバー仮想化やソフトウェア定義ネットワーク(SDN)、WebレベルにおけるWebロードバランサなどはいずれも、アプリケーションと低レベルとのあいだの1:1関係を破り、アップタイムとパフォーマンスにおけるWebスケールのの利点をもたらす。
データベースのレベルでは、抽象化層が提供する重要な利点により、データベースの欠点の一部が克服される。このような、データベースをロードバランスするソフトウェアは、たとえば、フェイルオーバーとスケールアウト(分散化)とスループットの高速化をを透明に可能にする。
上の、“透明に”がとくに重要だ。こういった能力をすべて、アプリケーションやデータベースに変更を加えずに獲得することが、キモ中のキモである。
初期のインターネット企業が“データアクセス層”を着想したときは、デベロッパーたちが抽象化層の仕様や特性に合わせてアプリケーションを書き換えなければならなかった。でも、アプリケーションとデータベースの仲を取り持つネットワークレベルの透明なプロキシなら、コードの書き換えやアーキテクチャの変更は要らない。このこともやはり、キモ中のキモである。
以下は、Bain Capital Venturesにおけるインフラストラクチャソフトウェアのプラクティスだ。うちのベンチャー資金の半分以上はこれらに投じられている。データベースのレベルにおける抽象化は、いろんなところで進展している:
- 代替データベース
- プロキシを作るデータベースベンダ
- Webロードバランサ企業が彼らのプロダクトのSQLバージョンを作る。そして、
- スタートアップは目的指向(purpose-built)のシステムを作る
以上はどれも、抽象化方式の価値を認知し、それをベースにしている。最初のWebスケールの企業がまさにそうだったし、これらのベストプラクティスは今では99%の企業を助けている。しかも彼らのほとんどは、数百名のエンジニアと数百万のドルを投じて抽象化層を自作してはいない。
われわれは4年前に、ScaleBaseに投資した。そこは、目的指向のデータベース抽象化ソフトウェアを作っているスタートアップだ。この企業の技術的資産は今ではScaleArcがオーナーになり、そこにはわれわれも最近投資をした。この技術は、データベースというアキレス腱に挑戦し、それを解消する。
調査会社のGartnerが最近、抽象化アーキテクチャに向かうこのトレンドを特集している。そこで同社は、“SQLロードバランシング”を、その最新の“ITサービスの継続性誇大宣伝賞”の一員に加えた。その報告書の中でGartnerは、ITショップが求めるべきソフトウェアの特質を次のように推奨している:
- 複数のデータベースをサポートしている
- クラウドでもオンプレミスでも快調に動く
- セキュリティで妥協をしていない
アップタイムに関しては多くの場合、データベースがシステムのいちばん弱い急所だ。Webスケールを構築するテクノロジーの全体的な重なり(“スタック”)の中では、データベースがいちばん難しい部分だからだ。われわれは、全員がFacebookでもGoogleでもないから、内部のエンジニアだけで問題を解決できない。その代わり、データベース抽象化ソフトウェアが企業にWebスケールの能力を与える。彼らが必要とする、柔軟性とスケールとパフォーマンスを。
[原文へ]
(翻訳:iwatani(a.k.a. hiwa)