ソーシャルメディアは厄介なことになる可能性がある。
これは仮定の話ではない。いつかはこんなことを考える日が来るだろう「おっと、最後にInstagramやTwitterに投稿してから随分時間がたったぞ」 — そしてまあ、何も言いたいことがないのに無理やりでっち上げた投稿は、惨めな失敗に終わるというわけだ。そんなとき、おそらくPost Intelligenceを使っていたなら、私はもっとうまくやれていただろう。
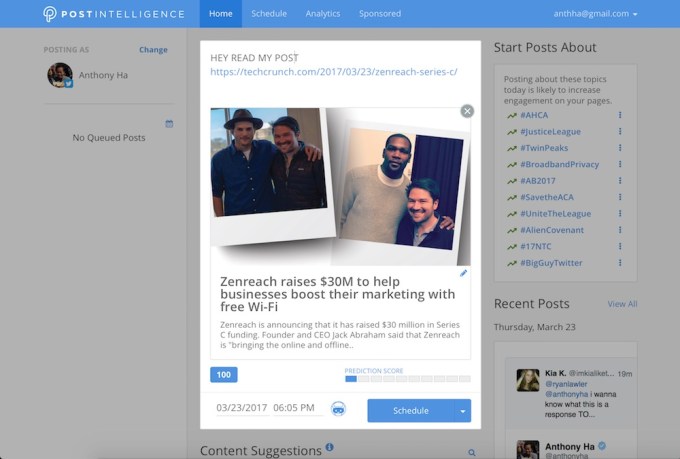
私はこれまで沢山のソーシャルメディアのダッシュボードやアシスタントを見てきたが、Piという名のPost Intelligenceのアシスタントは、これまでで最も直接的なアドバイスを提供してくれるものだ。TwitterアカウントやFacebookページに接続すると、それはあなたが投稿に使っても良いかなと思えるような話題のリンクの一覧を生成してくれる(例えば、今日最初に提案されたものは、BatmanとTrumpに関する話題などだ、まあ悪い提案ではない)。
投稿の下書きを書くと、Piはその投稿がどれくらいウケるかを予測し、投稿するのに適した時間も提案してくれる。また、投稿がどれくらいウケたかも分析するし、更にスポンサー付きの記事を通してお金を稼ぐ手段も提供されている。
Post Intelligenceの共同創業者兼CEOのBindu Reddyは、このプロダクトがFacebookとTwitterからのエンゲージメントデータ(投稿への反響データ)を調べていると語った。そして人工知能を用いて、フォロワーによる反響が良いであろうと予測されるトピックを浮上させてくるのだ。投稿のパフォーマンスは話題、長さ、気分、そしてキーワードを用いて予測される。
「私たちは皆のツイートを良くします」とReddyは語る。
彼女は、Piはユーザーに何を言うべきかを指示しているわけではないこと、そして単純に現在何に人気があるのかに焦点を当てているだけでもないことを強調した。もちろん他の人たちと全く同じものをシェアしていたのでは成功は覚束ない。
「トップ5のテレビ番組や、トップ10のニュース記事だけではなく、1000の異なるトピックに光を当てたいと思っているのです」とReddy。「なので、私たちのプロダクトは、現在のような反響の洞窟(同じようなニュースが拡散するネット)状況を取り除いてくれることに対して役立つだろうと、かなり楽観的に考えています」。
Post Intelligenceは、ソーシャル広告プラットフォームのMyLikesの背後に居るものと同じ会社によって開発された。Reddyは、この技術に関して「完全に新しいものです、インスラストラクチャ全体を書き直しました」と語る。チームは現在はPost Intelligenceに専念しているということだ。
現在のPost Intelligenceは無償で利用できる。
[ 原文へ ]
(翻訳:Sako)