遅かれ早かれ、私たちの子供たちはロボットによって育てられることになる。このためロボットと子供関連の商品を提供しているディズニーは、その傾向を先取りしたいと考えている。その研究部門から発表された3つの研究は、子供たちが、ロボットやそれ以外のある程度スマートなマシンとどのように会話もしくはやりとりを行うのかを理解し、改善することを目指している。
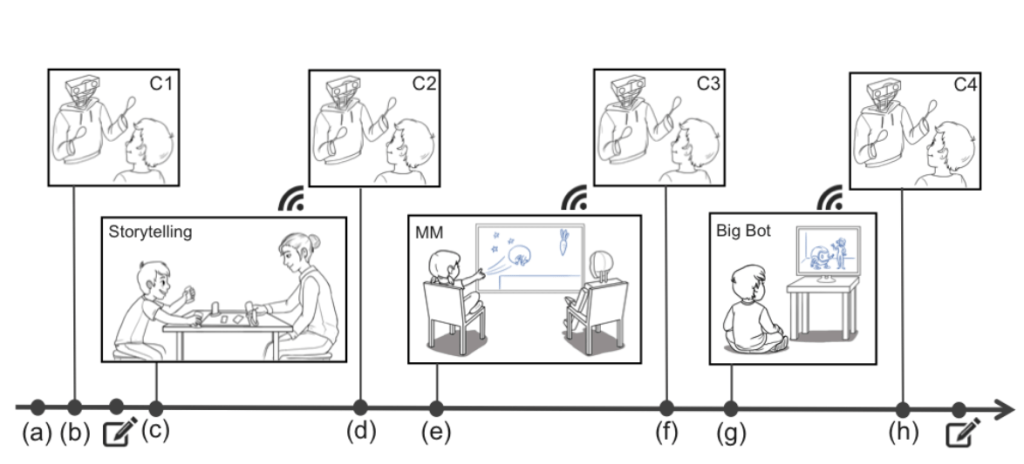
3つの研究は、全部を合わせて1度に実施され、それぞれの研究が別々の論文として執筆され、米国時間6月27日に公開された([論文1][論文2][論文3])。研究対象の子供たち(約80人)には、基本的に物語を話すことと会話を伴った連続した短いアクティビティが与えられ、子供たちの反応は実験者たちによって注意深く記録された。
 まず初めに子供たちはPiperという名前のロボットに紹介される(この紹介は実験のために、当然個別に行われる)。ロボットは別の部屋にいる人形使いによって遠隔操作(「オズの魔法使い方式」だ)されているが、異なる実験の条件に合わせてあらかじめ決められた反応が設定されていた。ここでの発想は、ロボットは何を言うにせよどのように言うにせよ、何かを伝えようとする際には、それまでに得た相手と関連する知識を使うべきだということだ。しかし特に子供相手の場合には、それがどのように役立つかはあまり明らかではない。研究者らは次のように述べている:
まず初めに子供たちはPiperという名前のロボットに紹介される(この紹介は実験のために、当然個別に行われる)。ロボットは別の部屋にいる人形使いによって遠隔操作(「オズの魔法使い方式」だ)されているが、異なる実験の条件に合わせてあらかじめ決められた反応が設定されていた。ここでの発想は、ロボットは何を言うにせよどのように言うにせよ、何かを伝えようとする際には、それまでに得た相手と関連する知識を使うべきだということだ。しかし特に子供相手の場合には、それがどのように役立つかはあまり明らかではない。研究者らは次のように述べている:
人間とロボットの対話は、長時間に渡る対話という課題に晒されている。それまでに行った会話を、関係の感覚を育むためにどのように利用できるのかを理解することが鍵なのだ。何故ならロボットが私たちの話したことを記憶しているか否か、それらの記憶をいつどのように提示してくるかが、私たちがロボットに対して抱く感覚に関係してくるからだ。
挨拶を済ませたあと、子どもたちは実験である協力して物語を語るアクティビティ(storytelling:子供と指導者が協力しながら物語を組み立てていくアクティビティ)に参加した。研究者たちは、このアクティビティの背後にある根拠をこのように説明する:
近年の進歩にもかかわらず、AIは子供たちの言葉の認識と自然言語の意味の理解に対しては不完全なままである。不完全な音声認識と自然言語理解は、ロボットが意味的に一貫した方法で子供に応答できない可能性を示唆する。こうした困難な要因のため、子供とロボットの間に流れるような物語活動が実現可能なのか、子供たちによって価値あるものと認識されるかどうかという点には、まだ疑問が残されている。
理論上の共同作業AIの代役を担う実験者は、子供とその相手の2人が紡ぎ出す物語にキャラクターを追加した。ある場合にはストーリーの文脈に沿って(「彼らは洞窟の中に仔猫を見つけました」)、またある場合にはランダムに(「物語に仔猫を追加しましょう」)。目的は、どちらがより多く子供たちを引きつけたか、どちらがアプリやデバイスをつかうのに現実的なタイミングだったのかを観察することだ。
幼い子どもや少年たちは、文脈の追加を求められた場合に躓きがみられた。これはおそらく、ある程度の思考と統合が必要だったからかもしれない。よってそれらとやり取りをする際には、反応が多くなる可能性がある。
 物語を語るアクティビティの途中で、子供たちはPiperのところに立ち寄る。Piperは子供たちの物語について一般的なやりかたで対話する。例えばストーリーの中に出てきたキャラクターを識別したり、それについての感想(例えば「その仔猫が洞窟を無事に出られたことを祈るよ」など)を追加したりする。続いて別のアクティビティ(ロボットとのコラボレーティブゲーム)が行われ、その後同様の反応と共に同様の対話が続いた。
物語を語るアクティビティの途中で、子供たちはPiperのところに立ち寄る。Piperは子供たちの物語について一般的なやりかたで対話する。例えばストーリーの中に出てきたキャラクターを識別したり、それについての感想(例えば「その仔猫が洞窟を無事に出られたことを祈るよ」など)を追加したりする。続いて別のアクティビティ(ロボットとのコラボレーティブゲーム)が行われ、その後同様の反応と共に同様の対話が続いた。
3番目の実験は一言で言うなら「Dora the Explorer(アニメの主人公)が、あなたが彼女の質問に答えるのを耳にしたら、何が起きるでしょう?」実験だ(日本では「ドーラと一緒に大冒険」というタイトルで放映された。Doraが番組中で質問をするが、約2秒後には答が示される)。
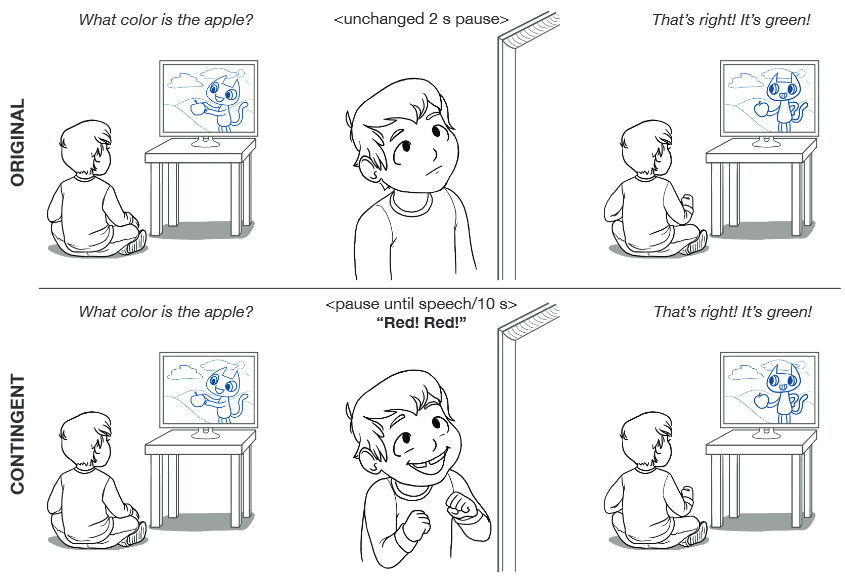
子供たちが、タブレットやビデオゲームシステムなどのインタラクションを可能にするシステム上で、より多くのテレビ番組を見るようになるにつれて、彼らを引き込む様々な機会が増えている…私たちは3つの実験を通して、正確なプログラム応答時間の影響、未回答に対する質問の繰り返し、子供が応答しそうな内容に関するフィードバックの提供、に関する調査を行った。
子供が何か言うか言わないかがわからない1,2秒後にただ答を言うのではなく、反応を(最大10秒まで)待って継続するか、あるいは答を言うように再び促す実験を行った。待つことと、促すことは明らかに応答率を高めたが、誤った答に対する指摘などのフィードバックが含まれていても効果はあまり見られなかった。
この活動をした後、子供たちはPiperの前に戻り、また別の会話を行った。その後、親しみやすさ、賢さなどの点でロボットを評価した。
研究者がPiperに関して発見したことは、以前の会話や選択肢を覚えているといった、より人間らしい反応が多いほど、より年齢の高い子供たちが好み、より反応がよくなったということだ。このことは基本的な社会的機能が、共感を生み出すためには重要であることを示唆している。
実はこれらはすべて、最初に述べたような、ロボットを私たちの子供たちに育てさせるために重要というよりも、むしろ人間とコンピューターのやりとりをより自然にするために大切なものなのだ。この際に、やりすぎや不気味さを防ぐことは大切だ。誰しもAlexaやGoogle Homeに「先週あなたが、家で1人落ち込んだ気分でピザを作っていたときに聴いていたものと同じプレイリストを、再生しますか?」とは言われたくないだろう(しかしそれは技術的には可能なのだ!)。
これらの論文はまた、子供が理解や言葉使いを改善するためにしばしば使われるゲームを用いたスピーチ療法のような局面に、このような研究が良く適用可能であることを示唆している。より幅広い応用を想像するのは難しいことではない。より暖かく、より曖昧さを許容し、コンテキストを意識したコラボレーティブなAIには多くの利点がある。こうした初期の実験は、そうしたことを可能にするための始まりに過ぎない。
[ 原文へ ]
(翻訳:Sako)
FEATURED IMAGE: JEFF SPICER / STRINGER/GETTY IMAGES