SQLはプログラミングの世界ではやさしい方だが、ふつうの人たちがリレーショナル・データベースを対話的に利用したいと思ったときには、やはりその学習曲線は急峻だ。そこでSalesforceのAIチームは、SQLを駆使できない人でもデータベースを使えるために、機械学習を利用できないか、と考えた。
彼らの最近のペーパー、Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning(強化学習を使って自然言語からSQLを生成する)は、機械学習でよく使われるシーケンス変換モデルを利用している。強化学習の要素を加えたことによりチームは、自然言語によるデータベースへのクェリをSQLに翻訳するという課題に対し、かなり有望と思われる結果を得た。
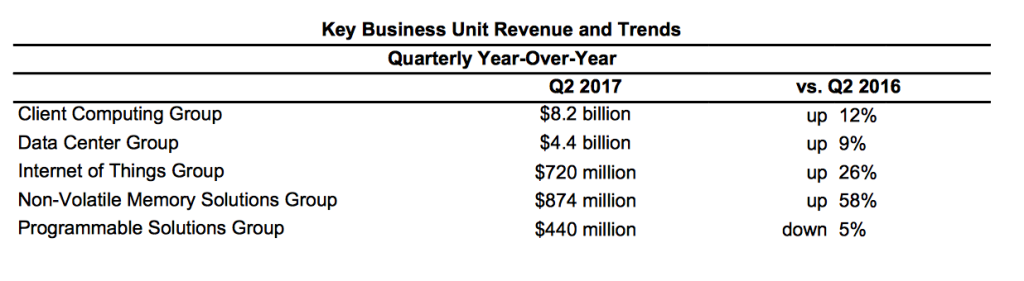
すなわちミシガン大学のデータベースに対し、データベースにフットボールの優勝チームを尋ねるクェリで、正しい結果が得られた。
このプロジェクトに関わった研究員の一人、SalesforceのVictor Zhongは、こう語った: “クェリの正しい書き方は一つではない。自然言語で言われた質問*に対し、それを表すSQLのクェリは二つも三つもあるだろう。われわれは強化学習を利用して、同じ結果が得られるクェリを使うよう、学習を誘導した”。〔*: 自然言語は、語形はまったく同じでも、話者の込めた含意がさまざまに異なることが多い。〕

どなたもご想像できると思うが、ボキャブラリーがとても大きいと、機械翻訳という問題はたちまち複雑困難になる。しかし、翻訳の可能性の多様性を野放しにせずに、どの語に関しても少数に限定してやると、問題はよりシンプルになる。そのためにSalesforceにチームは、ボキャブラリーを、データベースのラベルに実際に使われている語に限定した。つまりそれらの語は、SQLのクェリに実際に登場する語だ。
SQLの民主化は、これまでにもいろいろ試みられている。たとえば最近Tableauに買収されたClearGraphは、データをSQLでなく英語で調べることを、自分たちのビジネスにしている。
“データベース本体の上で実行されるようなモデルもある”、とZhongは付言する。“しかし、社会保障番号を調べるような場合は、プライバシーの懸念が生じる”。
ペーパー以外でSalesforceの最大の貢献は、モデルの構築に利用したデータセットWikiSQLだ。最初に、HTMLのテーブルをWikipediaから集める。これらのテーブルが、ランダムに生成されるSQLクェリのベースになる。これらのクェリを使って質問を形成するが、それらの質問はAmazon Mechanical Turkで人間に渡されてパラフレーズ(語形変化)される。それぞれのパラフレーズは二度検査され、人間によるガイダンスが付く。そうやって得られたデータセットは、このようなデータセットとしてはこれまでで最大のものだ。