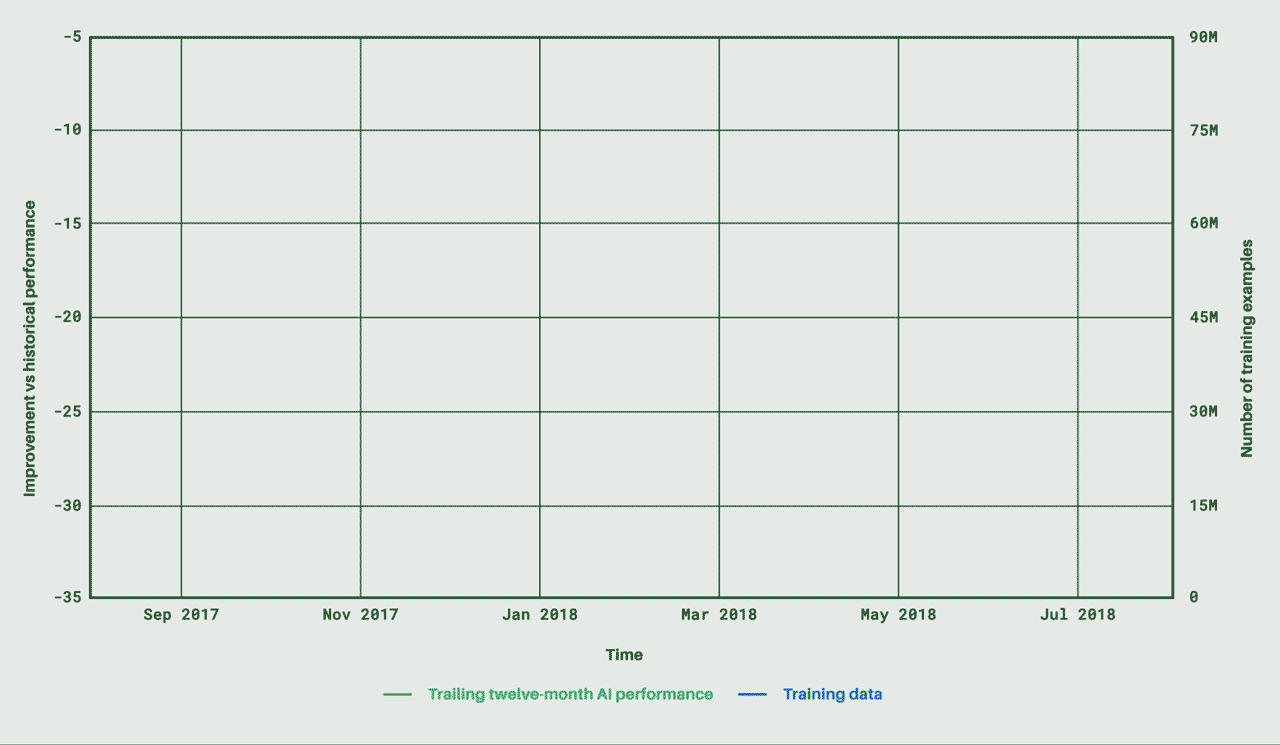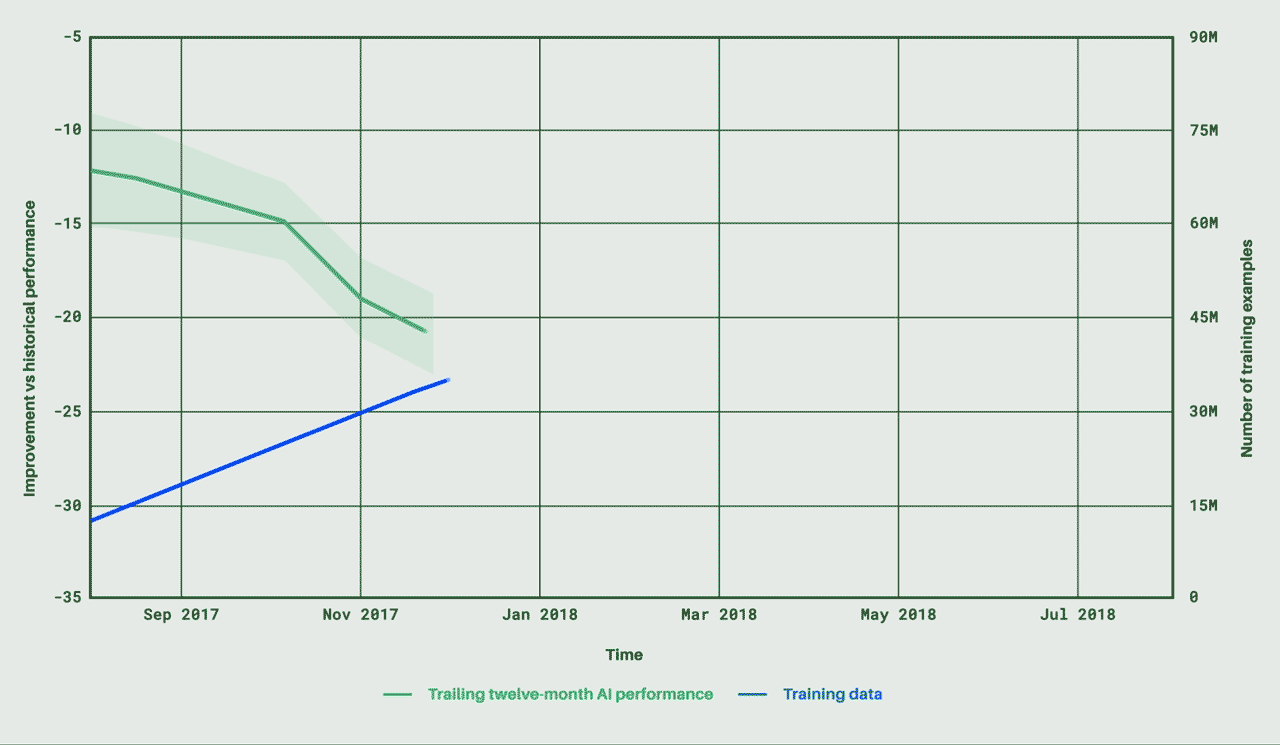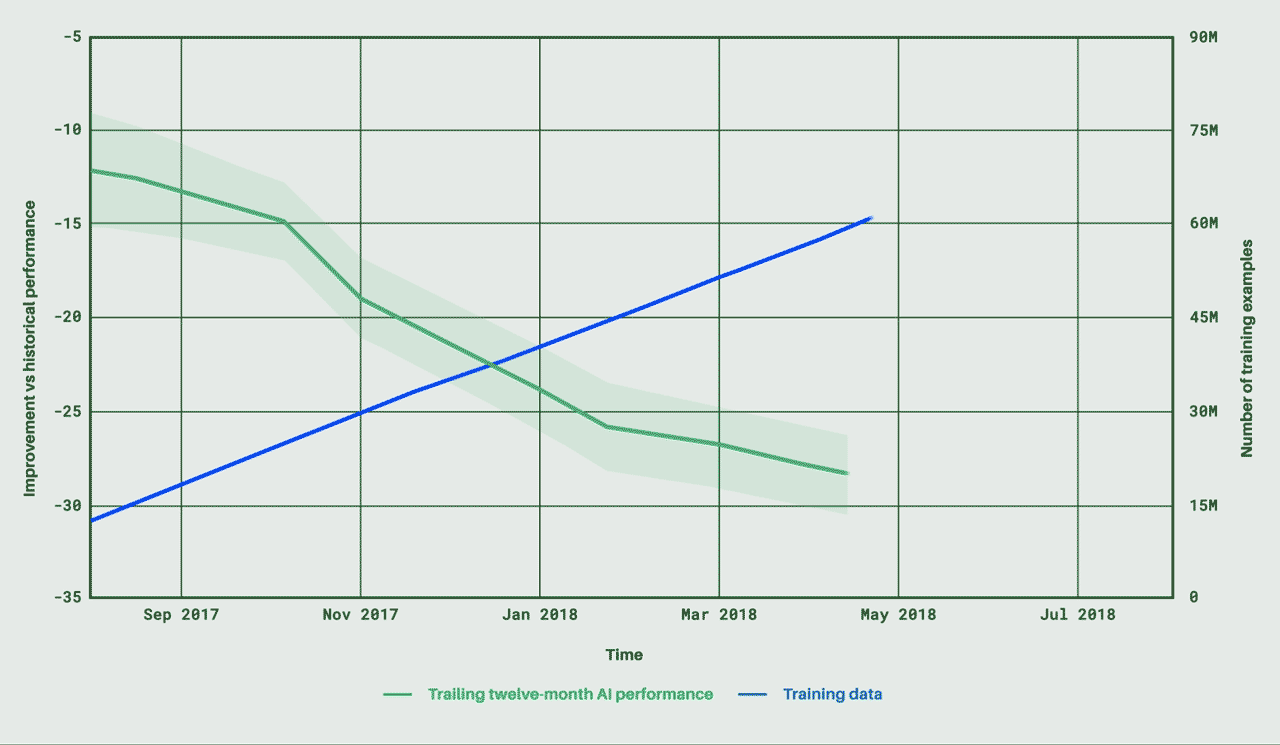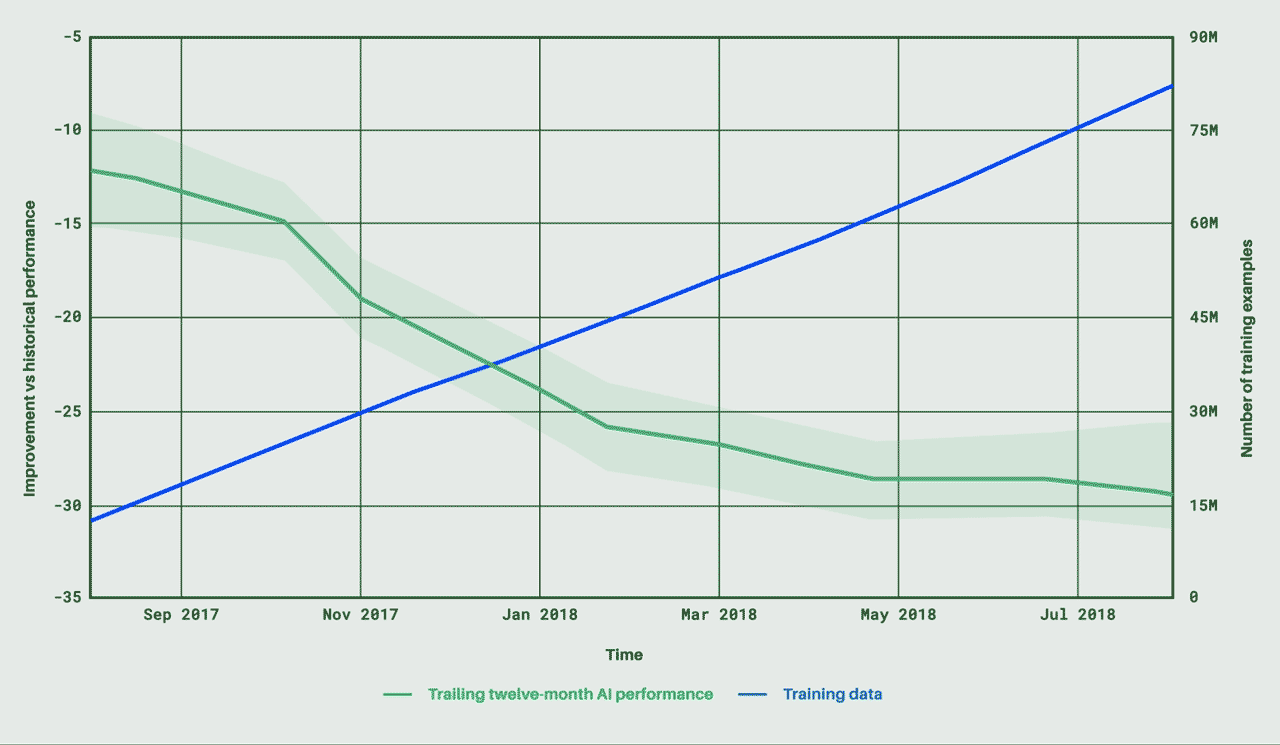
暗号通貨のプロジェクトは、人間がそのブロックチェーンを悪用すると破綻する。しかも分散デジタル経済が実際に動き出し、コインが離陸すると、それらを統治するスマートコントラクトの修復は難しい。あくまでも、デベロッパーによる事前対策が必要である。そこで、今日(米国時間8/17)ステルスを脱したIncentivaiは、その人工知能によるシミュレーションで、セキュリティホールを調べるだけでなく、ブロックチェーンのコミュニティを構成している人間たちの貪欲や非論理性にメスを入れる。暗号通貨分野のデベロッパーはIncentivaiのサービスを利用して、自分たちのシステムが動き出す前に、その欠陥を修復できる。
Incentivaiの単独のファウンダーPiotr Grudzieńはこう言う: “スマートコントラクトのコードをチェックする方法はいろいろあるが、新たに作った経済が期待通りに動くことを確認する方法はない。そこで私が考えたのは、機械学習のエージェントを利用するシミュレーションを作り、それが人間のように振る舞うことによって、システムの未来の振る舞いを予見する方法だ”。
Incentivaiは来週Y Combinatorを卒業するが、すでに数社の顧客がいる。顧客(ユーザー)は、Incentivaiの有料サービスにより自分たちのプロジェクトを監査してレポートを作るか、または自分でそのAIによるシミュレーションツールをホストしてSaaSのように利用する。同社がチェックしたブロックチェーンのデプロイは数か月後になるが、そのとき同社はすでに、そのプロダクトの有意義性を実証するための、いくつかのケーススタディーをリリースしているだろう。
Grudzieńは説明する: “理論的にあるいは論理としては、一定の条件下ではこれこれがユーザーにとって最適の戦略だ、と言うことはできる。しかしユーザーは、合理的でも理性的でもない。モデルを作ることが困難な、予想外の行動がたくさんある”。Incentivaiはそれらの理不尽な取引戦略を探求して、デベロッパーがそれらを想像しようと努力して髪をかきむしらなくてもよいようにする。
人間という未知数から暗号通貨を守る
ブロックチェーンの世界には巻き戻しボタンがない。この分散技術の不可変かつ不可逆的な性質が、良かれ悪しかれ、一度でもそれを使ったことのある投資家を遠ざける。ユーザーが偽りの請求をしたり、贈賄によりそれらを認めさせようとしたり、システムを食い物にする行動を取ったりすることを、デベロッパーが予見しなければ、彼らは攻撃を阻止できないだろう。しかし、正しくてオープンエンドな〔固定しない〕(AIに対する)インセンティブがあれば…これが社名の由来だが…AIエージェントはなるべく多くの収益を得るために自分にできることをすべてやってみて、プロジェクトのアーキテクチャにあるコンセプトの欠陥を明らかにするだろう。
Grudzieńはさらに説明する: “この〔すべてをやってみるという〕やり方は、DeepMindがAlphaGoでやったものと同じで、さまざまな戦略をテストするのだ”。彼はケンブリッジの修士課程でAIの技能を究め、その後Microsoftで自然言語処理の研究を担当した。

Incentivaiの仕組みはこうだ。まず、デベロッパーは、ブロックチェーンの上で保険を売るなどの、自分がテストしたいスマートコントラクトを書く。IncentivaiはそのAIエージェントに、何を最適化するのかを告げ、彼らが取りうるすべての可能なアクションを羅列する。エージェントの役柄はさまざまで、大金を手にしたいと思っているハッカーだったり、嘘をばらまく詐欺師だったり、コインの機能性を無視してその価格の最大化だけに関心のある投機家だったりする。
そしてIncentivaiはこれらのエージェントにさらに手を加え、彼らを、ある程度リスク忌避型だったり、ブロックチェーンのシステム全体を混乱させることに関心があったり、といったタイプにする。それから、それらのエージェントをモニターして、システムをどう変えればよいかというインサイトを得る。
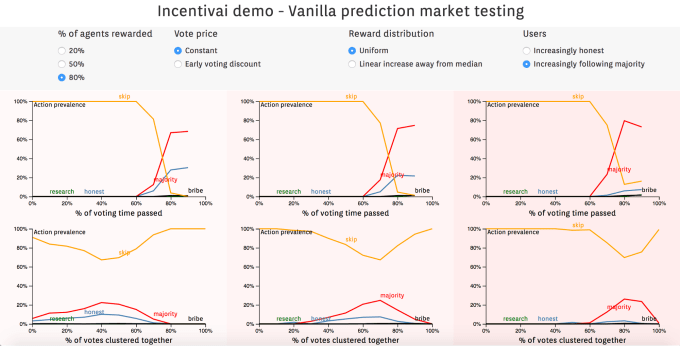
たとえば、トークンの不均一な分布がパンプ・アンド・ダンプ(pump and dump, 偽情報メールによる価格操作詐欺)を招く、とIncentivaiが学習したら、デベロッパーはトークンを均一に分割して、初期のユーザーには少なめにする。あるいはIncentivaiは、認められるべき支払請求をユーザーが票決する保険製品は、投票者が偽の請求を偽と立証するために支払う債権価格を上げて、詐欺師から収賄しても投票者の利益にならないようにする必要があることを、学ぶかもしれない。
Grudzieńは、自分のスタートアップIncentivaiについても予測をしている。彼の考えによると、分散アプリケーションの利用が上昇すれば、彼のセキュリティサービスのやり方を真似るスタートアップが続出するだろう。彼によると、すでに一部のスタートアップは、トークンエンジニアリングの監査や、インセンティブの設計、コンサルタント活動などをやっているが、ケーススタディーを作る機能的シミュレーションプロダクトは誰もやっていない。彼曰く、“この業界が成熟するに伴い、そういうシミュレーションを必要とする、ますます複雑な経済システムが登場するだろう”。
[原文へ]
(翻訳:iwatani(a.k.a. hiwa)