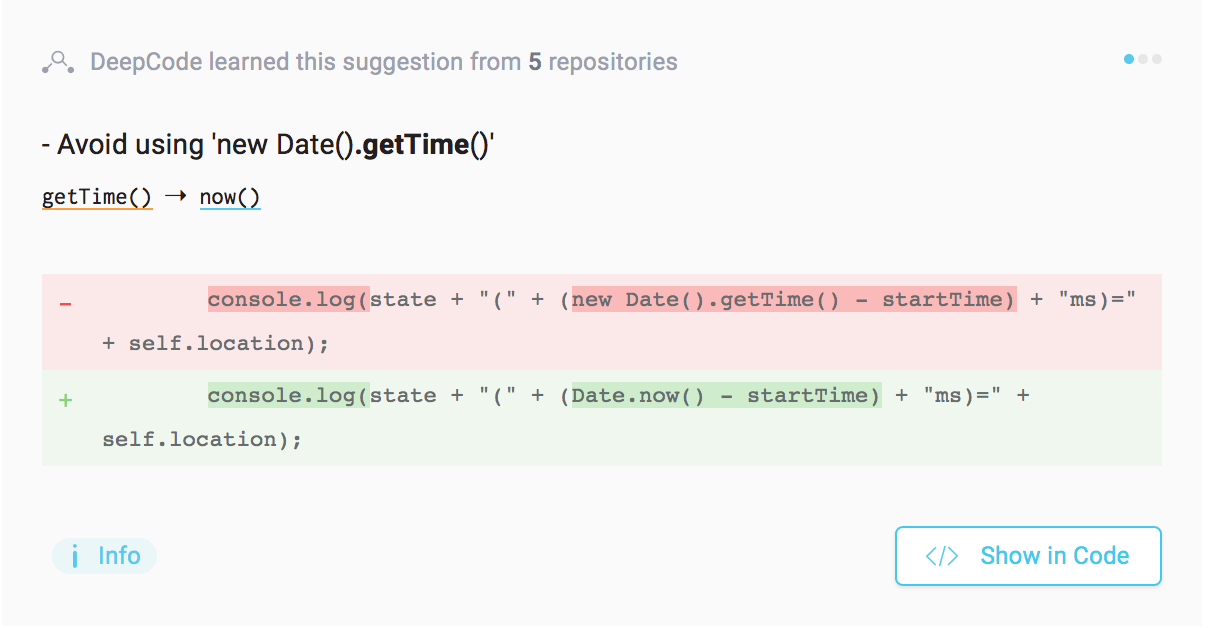
クラウドサービスは、ソフトウェアやインフラストラクチャの‘管理’という面倒な部分を取り除いてくれる。今日では、機械学習が多くのデベロッパーたちのあいだで急速に関心を集めつつあるが、AWSはそれのいちばん面倒な部分、すなわち機械学習のモデルの構築とデプロイの過程を、同社のクラウドサービスにより、単純化しようとしている。
そのサービスが、今日(米国時間11/29)のre:Inventカンファレンスで発表されたAmazon SageMakerだ。それは、デベロッパーやデータサイエンティストに、機械学習のモデル制作プロセスを管理するためのフレームワークを提供し、そのプロセスに通常含まれる複雑面倒な部分を取り去る。
AWSのシニア・テクニカル・エヴァンジェリストRandall Huntが、このサービスを発表するブログ記事〔上記リンク〕で、デベロッパーが新しいアプリケーションで機械学習を利用するときのプロセスを加速化するフレームワークを提供することが、サービスの基本コンセプトだ、と言っている: “Amazon SageMakerは、完全な管理を伴う。エンドツーエンドの機械学習サービスであり、データサイエンティストやデベロッパー、それに機械学習のエキスパートが、大規模な機械学習モデルを迅速に構築・訓練・ホストできるようにする”。
またAWSのCEO Andy Jassyは、このサービスを紹介するとき、こう述べた: “Amazon SageMakerを使えば、ふつうのデベロッパーが機械学習のモデルを容易に訓練しデプロイできます”。
この新しいツールには、三つの主要部分がある。
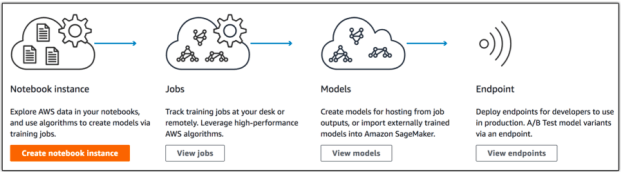
まずNotebook。これはオープンソースの標準的なツールJupyter Notebooksを使って、モデルのベースとなるデータを概観し整理する。この最初のステップは、EC2の標準的なインスタンスを使ってもよいし、もっと厳しい処理要求があるならGPUインスタンスを使う。
データが用意できたら、モデルの訓練を始める。これには、モデルのためのベースアルゴリズムも含まれる。モデルのフレームワークは、TensorFlowなどを自分で持ち込んでもよいし、あるいはAWSが事前に構成したものを使ってもよい。
re:Inventのステージで、JassyはSageMakerの柔軟性を強調した。すぐに簡単に使えるツールとして使ってもよいし、自分のフレームワークを持ち込んでもよい。どちらの場合でも、そしてソースが何であっても、サービスはもっともポピュラーなアルゴリズム向けに調整されている。
Constellation ResearchのVPで主席アナリストのHolger Muellerによると、この柔軟性は両刃の剣だ: “SageMakerはアプリケーションを作るときの作業努力を大幅に減らしてくれるが、そのためにAWSは多くのモデルを無理やり多面的に(polyglot)サポートしようとしている。AWS/Amazonが本当に欲しいのは、多くのユーザーをつなぎとめることと、計算とデータの負荷が大きいことだから”。
彼は、AWSがTensorFlowのような独自のニューラルネットワークフレームワークを提供すべきだ、と主張する。しかしまだ、そんな話はどこにもない。
今のところAmazonは、モデルを動かすために必要なインフラストラクチャのすべてを自前で整え、ノードのエラーやオートスケーリング、セキュリティパッチなどの問題を…フレームワークが何であれ…自分で処理する。まさに、多面的だ。
Jassyによると、モデルが出来上がったらそれをSageMakerから動かしてもよいし、ほかのお好きなサービスを使ってもよい。彼曰く: “これはデータサイエンティストやデベロッパーにとってすばらしいツールだ”。
このサービスは、AWSの無料ユーザーなら無料で利用できる。しかし処理量が一定のレベルを超えたら、使い方やリージョンに応じて課金される。

[原文へ]
(翻訳:iwatani(a.k.a. hiwa)