機械学習はトレンドだ。CERNの素粒子の探求からGoogleによる人間の声の合成まであらゆる場所に用いられている。ただしハードルが高い。 しかしビデオ編集、音声編集の実際の動作は複雑きわまるものだが、好奇心さえあれば子供でも手を出せるくらい優れたUIが数多く実用化されている。
それなら機械学習でも同じことができるはずだ、というのがLobeのファウンダーたちのコンセプトだ。LobeはLEGOブロックを組み合わせるのと同じくらい簡単に機械学習モデルを作れるようにするプラットフォームを提供するスタートアップだ。
共同ファウンダーの一人でこれまでの各種の優れたデジタル・インターフェイスをデザイナンしてきたMike Matasに話を聞くことができた。Matasはこのプラットフォームの目的や開発の動機について話をしてくた。
「これまでもAIを使ったらこんなことができるはずだというアイディアを思いつくものの、実行するのに十分な知識がないという状況が多々あった。いくらいいアイディアでもAI専門家のチームを雇うことできなければ意味がなかった」とMatasは言う。
実は彼自身、こういう状況を経験した。
そこで私は自分でAIモデルを作れるものか調べてみた。たしかに入り口にはたくさんの術語、フレームワーク、数学といった難題が立ちふさがっていた。しかしそこをなんとかくぐり抜けると、コンセプト自体は直感的に理解しやすいものだった。機械学習は人間にものを教えるのと基本的に同じやり方だから、普通のプログラミングよりやさしいぐらいだ
そうは言っても術語は難解だし、開発デバイスはまだまだ荒削りだった。機械学習は強力な手法だが、UIとしてはまだPhotoshopで画像編集をするようなレベルになっていなかった。
これまでの機械学習ではいろいろな要素を自分で組み合わせる必要があった。ダウンロードが必要なコードが多数あった。実は私もフレームワークを始めとしてダウンロードして組み合わせなければならないソフトウェアの数があまりに多く、ので嫌になった。私はUIデザイナーなので、それならこういう複雑な状況を整理して誰でも理解できるようなUIを構築するチャンスではないかと考えた
MatasとMarkus Beissinger、Adam Mengesが共同ファウンダーとなってスタートさせたLobeは機械学習を利用して大量のデータから意味のある特徴を抽出し、ラベル付けするための直感的に理解しやすいビジュアルなインターフェイスを作っている。下にエンベッドしたデモ・ビデオでは、手のジェスチャーをカメラで読み取って絵文字に変換するアプリを作るプロセスが詳しく紹介されている。アプリを開発するのにコンピューター言語の知識は必要ない。コードの処理は1行も出てこない。ましてコードを書く必要はない。もちろん必要なら(また能力があれば)詳細レベルに立ち入って調整することはできる。Lobeのプラットフォームは非常に使いやすく、処理も高速だ。十分なデータがあり機械学習による処理の可能性を感じているものの技術的ノウハウがないユーザーが簡単に新しいアプリを開発する可能性を開くものだろう。
Matasはこの状況をパソコンの初期に例える。
それまでコンピューターを扱えるのは専門のエンジニアと計算機科学者だけだった。「専門家しかコンピューターを扱えなければコンピューターの利用法を考えられるのも専門家だけになる。しかし80年代の後半になるとコンピューターにはクリエーティブな使い方が数多く登場した。それは大部分UIの改良によるものだった。
Matasは機械学習に関しても使いやすいUIの登場によって入門のハードルが下がれば新しいアプリが洪水のように登場するとみている。「データサイエンス以外のフィールドの人々も自分たちの課題に機械学習が適用できると考え始めている。しかも今後はアイディアからプロトタイプを作ることを機械学習専門家の手を借りず、自分たちでできるようになる」という。
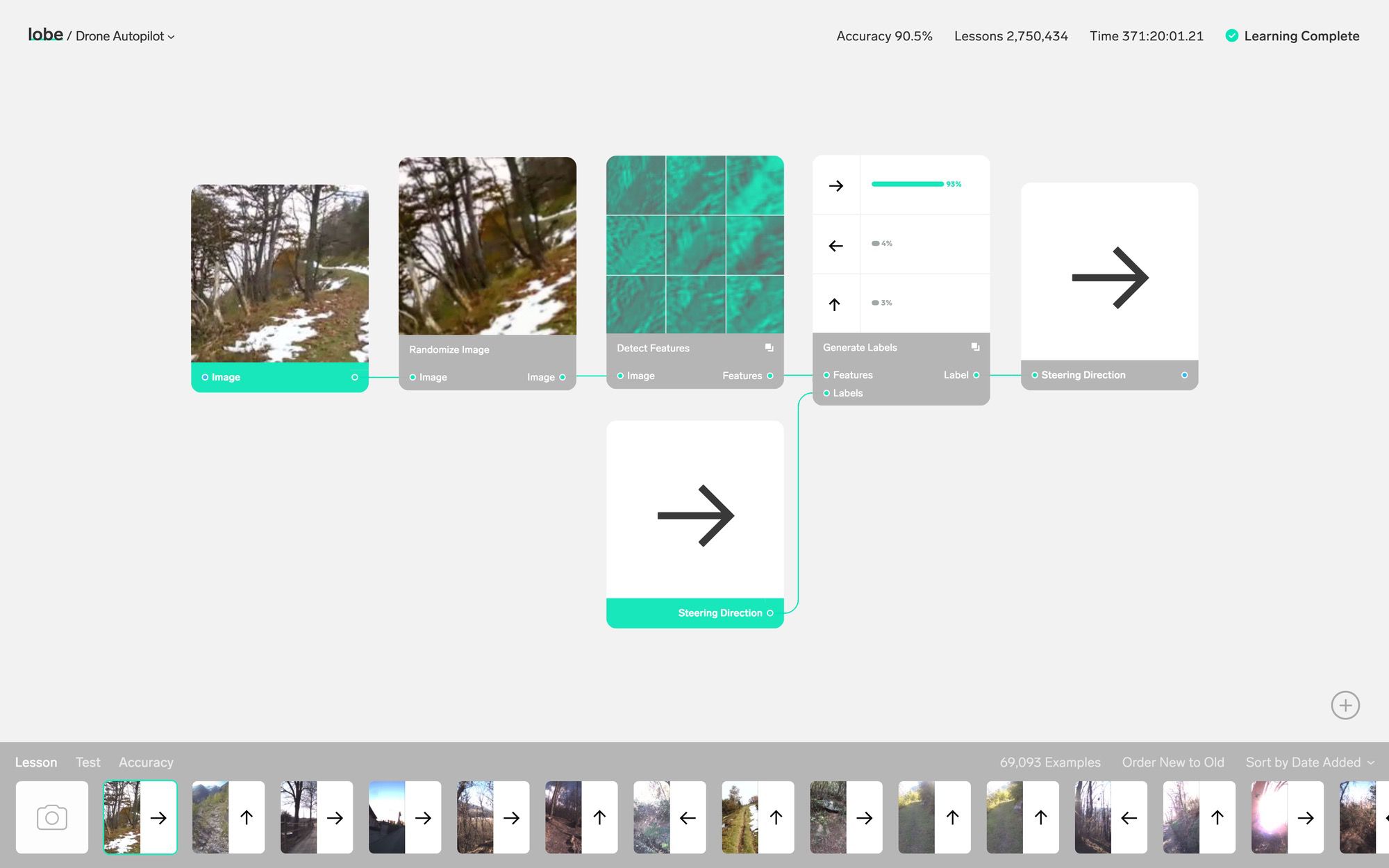
機械学習の応用が期待される分野は無数にあるが、Lobeでは簡単なモジュールで計測認識、ジェスチャー認識、読唇術、花びらのような対象をリアルに再現するなど多数のアプリが可能となることを示している。学習のベースとなるデータはユーザーが用意しなければならない。しかし機械学習で処理するのは今後は困難な部分ではでなくなるという。
機械学習コミュニティーはオープンソースに徹することをモットーとしている。 Lobeも独自のAPIを通じてLobeのサーバーでしか作動しないようなモデルは採用していない。「LobeのアーキテクチャはTensorflowのようなオープン規格をベースとしている。Lobeで学習、テスト、調整などをした後は、どんなプラットフォーム向けにもコンパイルして作動させることができる」ということだ。
現在Lobeはまだクローズド・ベータの段階だ。 「問い合わせが殺到している。強い関心を呼んでいるのは確かだ。公開は徐々にしていくが、できるかぎり小さく始めるつもりだ。われわれは急がず身の丈にあったやり方をしていく」とMatasは語った。
[原文へ]
(翻訳:滑川海彦@Facebook Google+)