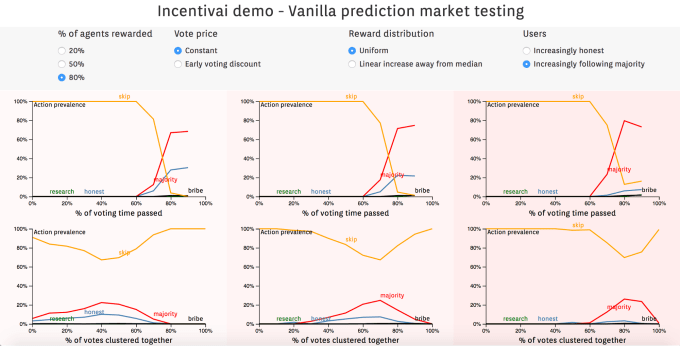
たとえば、トークンの不均一な分布がパンプ・アンド・ダンプ(pump and dump, 偽情報メールによる価格操作詐欺)を招く、とIncentivaiが学習したら、デベロッパーはトークンを均一に分割して、初期のユーザーには少なめにする。あるいはIncentivaiは、認められるべき支払請求をユーザーが票決する保険製品は、投票者が偽の請求を偽と立証するために支払う債権価格を上げて、詐欺師から収賄しても投票者の利益にならないようにする必要があることを、学ぶかもしれない。
その仕組みはこうだ: Test PilotでAdvanceを有効にすると、Webの閲覧はふつうにできるが、Advanceはユーザーが閲覧するサイトの種類について記録と学習を開始する。そしてその学習に基づいて、その人のWeb閲覧を補完するようなページや、その人が好きになりそうなページをサイドバーで推奨する。そしてユーザーは、Advanceが正しくないと感じたら、推奨されたページに「退屈」「的外れ」「スパム」などのフラグをつけて、エクステンションの推奨能力を鍛えていく。
4/ Apple's custom SoC effort is a key reason why the iPhone leads in performance and go-to-market. Tesla's AI chip effort will do the same—they will be able to deliver performance & features *ahead* of other auto makers that must wait for the next chip from Nvidia/Intel。
Empathは、スマートメディカルのICTセルフケア事業部門としてスタートし、2017年11月にスマートメディカルの子会社として独立した企業。ルクセンブルクで開かれる世界的なイベントITC Spring 2018で開催されたスタートアップピッチでは日本企業として初めて優勝するなど、海外のピッチコンテストで複数の優勝経験を持つ。
Eubanksは、例としてAllegheny Family Screening Tool(AFST:アレゲーニー家族スクリーニングツール)を利用する、Pittsburgh County Office of Children, Youth and Families(ピッツバーグ郡、青少年、および家族のためのオフィス)を挙げている。このツールは統計的モデルを用いて幼児虐待やネグレクトのリスクを評価するものだ。このツールを使用すると、貧困家庭の割合が不均衡に増えることになる。なぜならツールのアルゴリズムに供給されるデータは、公立学校、地方住宅機関、失業サービス、少年保護観察サービス、そして郡警察などから得られることが多いためだ。基本的に、ここに集まるデータはこうしたサービスを利用したりやりとりのある事の多い、低収入の市民たちから得られるものが多くなる。反対に、私立学校、子守サービス、プライベートな精神衛生および薬物治療サービスといった、民間サービスからのデータは入手できない。
Taylor Owenは、2015年に発表した“The Violence of Algorithms”(アルゴリズムの暴力)という記事の中で、彼自身が情報分析ソフトウェア会社のPalantirで目撃したものを報告し2つの主要な点を指摘した。1つはこうしたシステムは、ほぼ人間によって書かれ、人間によってタグつけされ入力されたデータに基いているということ、そしてその結果「人間の偏見とエラーで溢れたものになってしまう」ことだ。そして2つめに彼は、こうしたシステムが徐々に暴力に用いられるようになっていることを示唆している。
その昔Giannandreaは、Appleのチームメンバーが1989年に作った伝説の企業General Magicのシニアエンジニアだった。創業者には、Andy Hertzfeld, Marc Porat, Bill Atkinsonらがいたが、会社は結局失敗し、そのあとに革新的な技術の数々を遺した。たとえば小型のタッチスクリーンや、ソフトウェアモデムなどだ。General Magicは天才たちのインキュベーターとしても機能し、Susan Kare, Tony Fadell, Andy Rubin, Megan Smith, そしてAppleの今の技術担当VP Kevin Lynchらはみなここから巣立った。